《内推》专题
-
ABAP 内联数据声明
本文向大家介绍ABAP 内联数据声明,包括了ABAP 内联数据声明的使用技巧和注意事项,需要的朋友参考一下 示例 在某些情况下,可以内联执行数据声明。
-
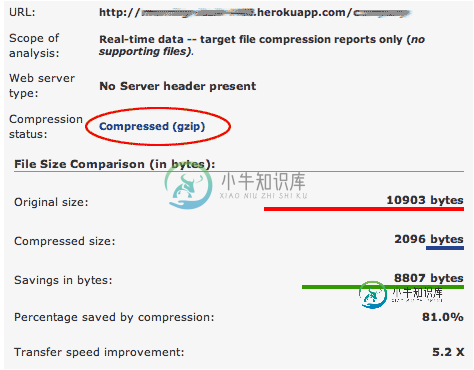 表达gzip静态内容
表达gzip静态内容问题内容: Express和connect似乎已删除其gzip功能,因为它们效率太低。目前,对于express-js的gzip是否有可靠的解决方案? 问题答案: Connect 2.0 添加了对基于新zlib东西的compress()中间件的支持,而这些东西刚刚出现在Node Core API中。 通过在文件中添加连接2.0的依赖关系,可以在快速服务器中使用此功能: 然后将以下逻辑应用于快速应用程
-
玉:段落内的链接
问题内容: 我正在尝试用Jade编写一些段落,但是当段落中有链接时会发现很难。 我能想到的最好的,我想知道是否有一种方法可以减少标记: 问题答案: 从jade 1.0开始,有一种更简单的方法可以解决此问题,但是不幸的是,我在官方文档中找不到它。 您可以使用以下语法添加内联元素: 因此,没有在ap中插入多行的示例将是这样的: 您还可以执行嵌套的内联元素:
-
Python内存优化技巧
问题内容: 我需要优化应用程序的RAM使用率。 请避免让我的讲座告诉我在编写Python时我不关心内存。我有一个内存问题,因为我使用了很大的默认字典(是的,我也想很快)。我当前的内存消耗为350MB,并且还在不断增长。我已经不能使用共享主机了,如果我的Apache打开更多进程,内存将增加两倍和三倍……这很昂贵。 我已经进行了 广泛的分析, 而且我确切地知道了问题所在。 我有几个带有Unicode键
-
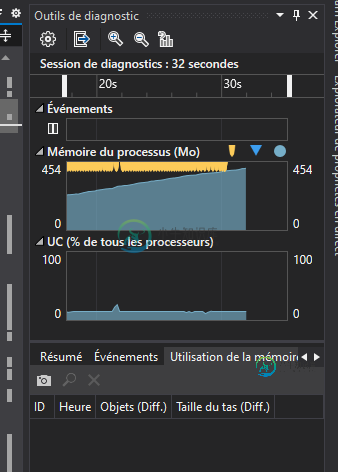 WPF DataGrid ItemsSource内存泄漏
WPF DataGrid ItemsSource内存泄漏我不知道为什么,但当我定义DataGrid的ItemsSource时,它会造成一些内存泄漏。 这是我的DataGrid的xaml代码: 这是我定义ItemsSource的代码: 我知道这是由行,因为如果我注释它,内存泄漏不会发生。 如果你有任何线索,请与我分享
-
内容不能为null laravel
我正试图提交一份表格,但出现了此错误 查询异常在Connection.php647行:SQLSTATE[23000]:完整性约束违反:1048列内容不能为空(SQL:插入到(,,,,)值(主, , [], 2017-03-28 11:10:58, 2017-03-28 11:10:58)) 内容应该可以为空。 我的迁移表 我的存储方法
-
Python:内存泄漏调试
问题内容: 我有一个在django中运行的小型多线程脚本,随着时间的流逝,它开始使用越来越多的内存。将其保留一整天会消耗大约6GB的RAM,我开始进行交换。 在http://www.lshift.net/blog/2008/11/14/tracing-python-memory- leaks 之后,我将其视为最常见的类型(仅使用800M内存): 这没有什么奇怪的。我现在应该怎么做才能帮助调试内存问
-
JavaScript内存管理介绍
本文向大家介绍JavaScript内存管理介绍,包括了JavaScript内存管理介绍的使用技巧和注意事项,需要的朋友参考一下 简介 低级语言,比如C,有低级的内存管理基元,想malloc(),free()。另一方面,JavaScript的内存基元在变量(对象,字符串等等)创建时分配,然后在他们不再被使用时“自动”释放。后者被称为垃圾回收。这个“自动”是混淆并给JavaScript(和其他高级语言
-
PHP内爆(101)带引号
问题内容: 插入一个简单数组 看起来像这样 那会返回这个 太好了,所以我可能会这样做 现在我有了我想要的漂亮的csv字符串 有没有更好的方法可以做到这一点,在我看来应该有一个可选的参数爆破,我错过了什么吗? 问题答案: 不,您的操作方式很好。仅需要1-2个参数(如果您仅提供一个数组,它将通过一个空字符串将各个部分连接起来)。
-
数组内的Foreach循环
问题内容: 我正在尝试使用for循环在数组内创建一个数组-这是我的代码: 不幸的是,这给了我一个 “解析错误:语法错误,意外的T_CONSTANT_ENCAPSED_STRING,预期为’)’” 对于该行: 对于出了什么问题,我有些茫然-非常感谢您的帮助。$ clients是在其他地方定义的,所以这不是问题。 问题答案: 那是无效的语法。您必须首先构建数组的“父”部分。然后使用foreach循环添
-
411内容-所需长度
我试图使用Android Apache HttpClient做一个POST,但它返回错误411内容长度必需。这是代码。 我已经尝试添加行:- 但我得到了一个“组织”。阿帕奇。http。ProtocolException:内容长度标头已出现“错误”。这必须意味着HttpClient已经在发送内容长度。不幸的是,我无法访问服务器端。知道为什么会返回这些错误吗?
-
增加内存流容量
我试图从SSRS服务器读取报告,问题是我的内存流不能超过65536字节。 到目前为止,我已经尝试过使用内存流,但尚未成功设置其容量,然后再阅读报告本身 上面的MemoryStream必须在我读取文件之前增加它的容量。 我试过在我的应用程序中玩。配置,但我不知道从哪里开始设置内存流的字节容量
-
WSL内的Jupyter笔记本
在wsl(Windows linux子系统)中的conda虚拟环境中运行jupyter笔记本时,复制粘贴url将不起作用。它总是显示“响应时间太长”或“连接超时”。
-
JSON内容多通关系
我有两个模型,当我尝试添加新文件时,file\u id为null。我怎样才能解决这个问题? 客户: 文件: 存储库: 控制器: 我想添加带有Json内容的文件并使用customer_id作为外键。但是当我添加文件时,customer_id返回null。
-
了解ThreadPoolExecitor内部工作
我有以下代码: } 我对ThreadPoolExecitor工作方式的了解是否正确: 如果NumberOfThreadRunning 根据第3点。我应该能够使用ThreadPoolExecutor执行20个任务。 为什么上述代码的输出是?