《内推》专题
-
为什么C#内存流保留了这么多内存?
我们的软件正在通过一个从内存流读取数据的GZipStream解压某些字节数据。这些数据以4KB的块解压缩,并写入另一个内存流。 我们已经意识到进程分配的内存远高于实际解压的数据。 示例:具有2425536字节的压缩字节数组被解压缩为23050718字节。我们使用的内存分析器显示了方法MemoryStream。设置容量(Int32值)分配的67104936字节。这是保留内存和实际写入内存之间的2.9
-
如何忽略ANTLR中大括号内的任意内容?
我正在尝试编写一个配置文件语法并让ANTLR4来处理它。我对ANTLR很陌生(这是我第一个使用它的项目)。 在很大程度上,我理解大多数配置文件语法需要做什么(或者至少我认为我需要做什么),但我将要阅读的文件将在大括号内包含任意C代码。以下是一个示例: 类似于: 可能有很多这样的人。我似乎无法让它理解我只想忽略(不跳过)源代码。以下是我迄今为止的语法: 问题是,我在C\U BLOCK lexer规则
-
 内容太长,如何在console.log()中显示完整内容?
内容太长,如何在console.log()中显示完整内容?我有一个很大的数组,它有很多元素,我需要在控制台中显示它,我使用console.log(),但只显示了一部分。 如何显示完整的内容?
-
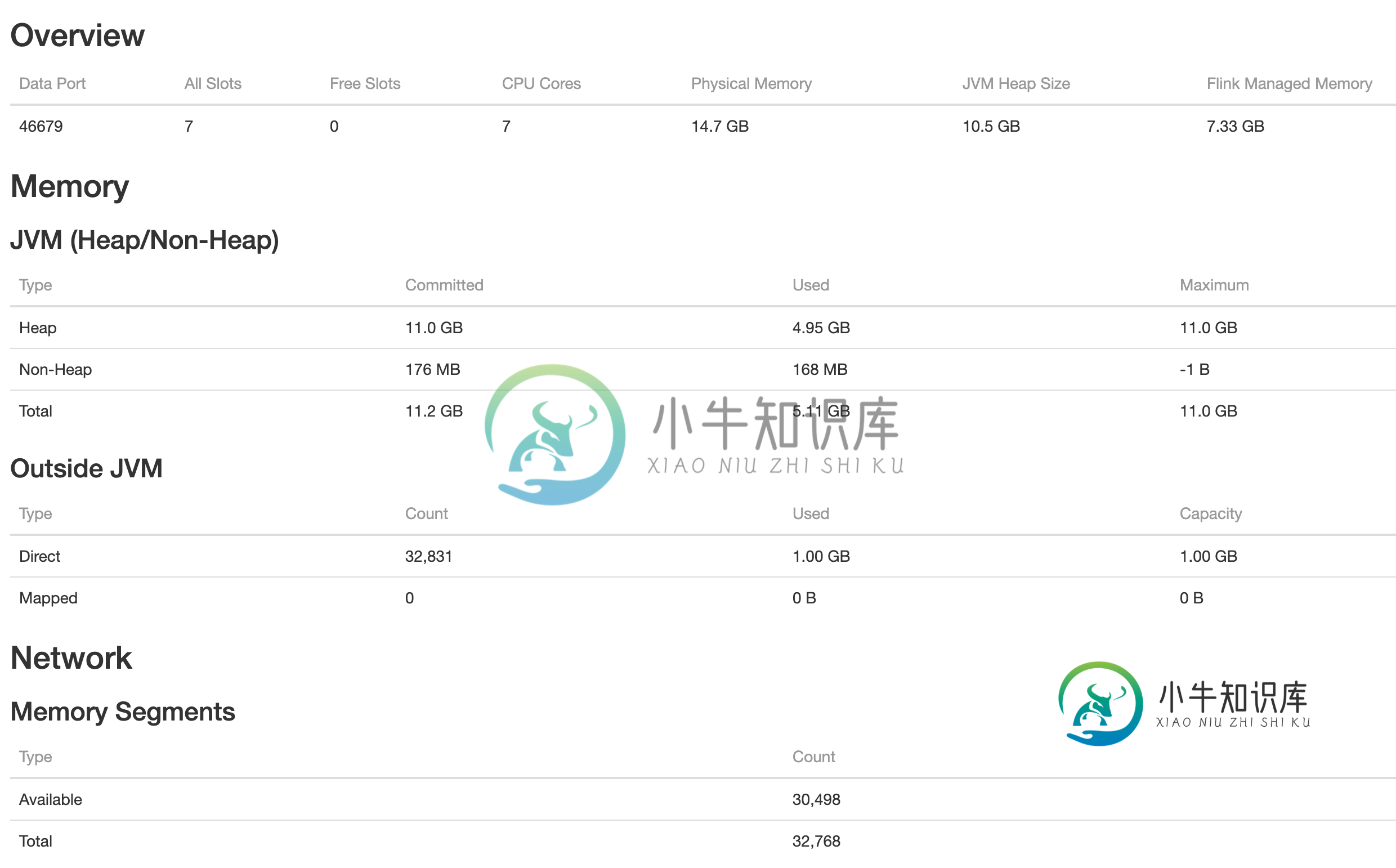 Apache Flink:与网络内存段的直接内存关系
Apache Flink:与网络内存段的直接内存关系我正在运行Flink 1.8版。 主要配置如下: 声明的堆大小是12GB,为什么在概述部分显示为7.33GB。 根据文档,堆大小=声明的堆大小-网络缓冲区内存(默认值:声明的堆的0.1倍,但最大为1gb)。所以正确的值是JVM(堆/非堆)部分中显示的值,即11GB :我假设,由于现在使用1GB作为网络缓冲内存,因此32768段基本上是指32KiB大小的内存段的计数。这些用于在任务之间传输数据的TC
-
 PDFBox 以内联方式插入与 TEXT 内联的图像
PDFBox 以内联方式插入与 TEXT 内联的图像我第一次使用PDFBox来生成PDF。我有一个文本文档,其中包含由我的java程序生成的一系列约40个多选题。有些问题与小图像相关联,需要在问题上方插入。出于这个原因,我正在将文本文档转换为PDF,并希望在其上插入图像。 我成功地在PDF文档中插入了一张图片,但是它像背景一样嵌入了文本。我希望将图像与文本对齐(如word格式的文本框,内嵌)。看起来插入图像类需要一个绝对位置,这取决于文本的位置。
-
从xamariniOS应用程序内的内存流播放视频
我正在用xamarin开发一个应用程序,用户可以用它来播放电影。我需要应用程序从内存流播放电影,而不是直接从url或文件。是否有一个播放器控件或库,我可以使用它来播放来自mmemory流的电影?
-
不支持内容类型的内部服务器错误
我已经构建了一个RESTendpoint,它使用Spring和Apache CXF2.5来使用和生成Application/JSON。 配置: 当我使用不受支持的内容类型(如application/xml)发送请求(使用REST客户端应用程序)时,我会得到一个内部服务器错误。我希望是405,因为endpoint不支持任何其他内容类型。为什么我会得到这个例外?
-
共享内存:shmget()/共享内存是如何工作的?
通过查看shmget()的手动页面,我了解到shmget()调用在内存中分配了#个页面,这些页面可以在进程之间共享。 它是否要创建内核内存页,并将其映射到进程的本地地址空间?还是为该段保留了相同的进程内存页,并将为其他附加进程共享相同的内存页? 调用shmget()时,内核将保留一定数量的段/页。 调用shmat()时,保留的段映射到进程的地址空间/页。 当一个新进程附加到同一段时,前面创建的内核
-
IPC共享内存与线程内存的性能差异
我经常听说,与在线程之间访问进程内存相比,在进程之间访问共享内存段没有性能损失。换句话说,多线程应用程序不会比使用共享内存的一组进程快(不包括锁定或其他同步问题)。 但我有我的怀疑: 1)shmat()将本地进程虚拟内存映射到共享段。这种转换必须为每个共享内存地址执行,并且可能表示一个很大的开销。在多线程应用程序中,不需要额外的转换:所有VM地址都转换为物理地址,就像在不访问共享内存的常规进程中一
-
第7章 OpenCL设备端内存模型 - 7.7 内存序
对于任何编程语言来说,内存序对于内存模型来说十分重要,需要用一定的顺序来保证线程得到的是期望的结果。当我们使用多线程和共享数据时,内存一致性模型能帮助保证线程得到的是正确的结果。OpenCL需要提供可移植化的高度并行代码,那么内存模型在正式发布的标准文档中就尤为重要。 之前我们提到过,执行内核中的所有工作项都可以访问全局内存上的数据。另外,在同一工作组的工作项可以共享局部内存。直到现在,我们在处理
-
内存检查 - dump.rdb文件成生内存报告(rdb-tool)
# rdb -c memory ./dump.rdb > redis_memory_report.csv # sort -t, -k4nr redis_memory_report.csv
-
java进程随着时间的推移消耗更多的内存,但没有内存泄漏[重复]
我的java服务运行在一个16 GB的RAM主机上,-xms和-xmx设置为8GB。主机正在运行其他几个进程。 我注意到随着时间的推移,我的服务消耗了更多的内存。我在主机上运行以下命令,并记录java服务的内存使用情况。 当服务启动时,它使用了大约8GB内存(将-xms和-xmx设置为8GB),但一周后,它使用了大约9GB+内存。它每天消耗大约100MB的内存。 我去了一个垃圾堆。我重新启动了我的
-
如何比较两个文本文件的内容并返回“相同内容”或“不同内容”?
问题内容: 我的Java应用程序需要具有比较文件系统中两个不同文件并确定它们的二进制内容是否相同的能力。 这是我当前的代码: 任何有关如何正确进行比较功能的提示或建议,将不胜感激。 问题答案: 最简单的方法是将内容读取为两个字符串,例如 ,然后对这些执行。您是否需要更复杂的差分功能?
-
具有映射内存、统一虚拟寻址和统一内存的GPU内存超额订阅
我正在考虑在GPU上处理数据的可能性,这对于GPU内存来说太大了,我有几个问题。 在CUDA 6.0中,UM不允许超额订阅GPU内存(并且通常不允许分配比GPU拥有的内存更多的内存,即使在主内存中也是如此),但是在CUDA 8.0中,这是可能的(https://devblogs.nvidia.com/parallelforall/beyond-gpu-memory-limits-unified-m
-
内部版本号:major.minor.revision
问题内容: 您如何使用既不使用自定义代码也不使用外部依赖关系(例如Shell脚本)的文件来编写: 生成格式major.minor.revision的内部版本号(例如 01.02.34 )。 在每次编译源代码时自动递增修订。 每次执行dist(ribution)任务时,都会自动增加次要版本。 另外: 提供增加主号码的选项。 提供增加小号的选项。 主编号递增时,次编号和修订版本号设置为0。 每当次要编