《步步高2022届秋招》专题
-
如何定期同步线程?
在不消耗太多cpu的情况下,我无法定期同步多个线程。 我有一个主线程和几个计算线程,它们都以以下形式出现: 目前,我让我的线程等待彼此循环std::this_thread::yield()指令,并在原子共享标志上设置一些条件。它可以工作,但是这些循环非常消耗CPU。 必须有另一个解决方案,可能是使用互斥和条件变量,但我是新手,我所有的尝试都会导致失败。。。 有人有主意吗?谢谢你的帮助。
-
安装后找不到异步
今天,我发现奇怪的事情,当我在全局安装async后,nodejs报告它找不到模块,下面是工作流程 获取此输出: 3.尝试使用它。
-
用Jasmine进行异步测试
我正在尝试用Jasmine和RequireJS做一些测试。一切都进行得很好,直到我注意到我所描述的函数的上下文出现了问题。 有人知道怎么解决这个吗?
-
异步初始化过滤器
我在尝试用异步数据初始化过滤器时遇到了麻烦。 过滤器非常简单,它需要将路径转换为名称,但要做到这一点,它需要一个对应数组,我需要从服务器获取该数组。 在返回函数之前,我可以在过滤器定义中做一些事情,但是异步方面阻止了这一点 使用promise可能是可行的,但我不清楚角度负载是如何过滤的。这篇文章解释了如何通过服务实现这样的魔力,但是对于过滤器也可以这样做吗? 如果有人对如何翻译这些路径有更好的想法
-
React useReducer异步数据获取
我正在尝试使用新的reactuseReucker API获取一些数据,并停留在我需要异步获取它的阶段。我只是不知道如何:/ 如何将数据提取放在switch语句中,还是不应该这样做? 我试图这样做,但它不与异步工作;
-
Play Framework 2.5.4异步Hibernate操作
如何使用Akka在使用Hibernate的db上执行操作而不阻塞web客户端? 结果发现错误是由dao.get()方法引起的。我更改了start()方法,以获取一个实际的对象,而不是数据库中的id,现在没有错误,但没有发生任何事情(如我前面所说,它卡在em.merge()上)。 过时: 如果我尝试这样的事情: 当我使用下面的代码启动上面的过程时: 那么新创建的线程(Actor)在尝试数据库操作时进
-
clojure中与http-kit同步POST
-
Spring控制器串行同步
在我看来,将myObject序列化为JSON和f的Spring代码将同时尝试在get()返回时访问myObject。除了返回MyObject的深度副本之外,还有什么方法可以防止这种情况发生吗?
-
 Android studio 3.6.1 gradle同步太慢
Android studio 3.6.1 gradle同步太慢首先,我很抱歉我的英语很差。 Android Studio 3.6.1构建#AI-192.7142.36.36.6241897,构建于2020年2月27日运行时版本:1.8.0_212-Release-1586-B04 amd64 VM:OpenJDK 64位服务器VM by JetBrains S.R.O Windows 10 10.0 GC:ParNew,ConcurrentMarkSweep
-
如何逐步使用ndk-stack?
我正在尝试调试此错误: 从这个问题中我了解到,我应该使用来获得错误日志的含义。 因此,我在Android Studio中使用下载了,现在在我的目录中有一个文件夹。 文件中说: 要使用ndk-stack,首先需要一个包含应用程序共享库未剥离版本的目录。 顺便说一句,我不知道那可能是什么。 你能给我一个循序渐进的指导吗?一步一步的。 TL;DR: 我有上面的错误日志,需要你帮我理解。
-
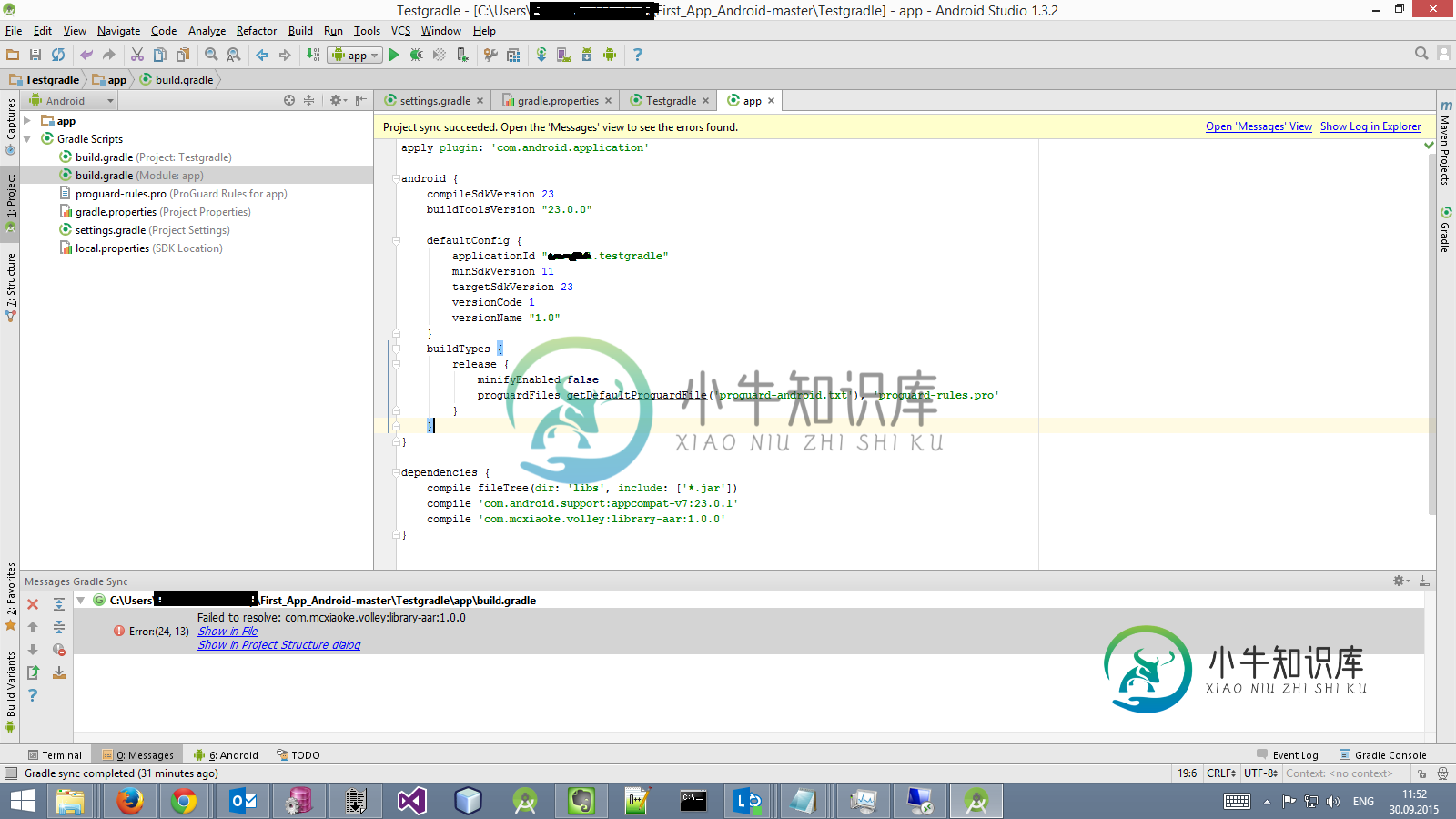 AndroidStudio gradle同步:无法解析
AndroidStudio gradle同步:无法解析驴你看,我要添加截取到我的应用程序添加这行代码com.mcxioke。截取:库aar:1.0.0建立。gradle文件 我也试着添加改装。但它给出了相同类型的错误:未能解决:bla bla bla。 所以我认为在我的情况下gradle不能同步任何其他库不同于com.android....... 我也尝试将这行代码添加到我的build.gradle。但是什么都没有改变 请指教 编辑:添加注释后生成。
-
材料设计步进控制
有人能告诉我如何开始实施Android Material Design guide中描述的垂直非线性步进控制吗 http://www.google.com/design/spec/components/steppers.html
-
MongoDB写关注同步级别
的HADR配置 IBM DB2-http://pic.dhe.IBM.com/infocenter/db2luw/v9r7/index.jsp?topic=%2fcom.IBM.DB2.luw.admin.ha.doc%2fdoc%2fc0011724.html, MySQL-http://dev.MySQL.com/doc/refman/5.5/en/replication-semisync.h
-
带有回调的Java同步
所以问题是在这种情况下notificationPhoneNumber对象锁定了多长时间?它是否会在线程完成其工作时被锁定?
-
Azure EventHub:发送异步性能
在日志中,我有将近1秒(~800毫秒)的值,为什么会有这么长的执行时间?