《寒假实习》专题
-
水槽假脱机目录源:无法加载较大的文件
我正在尝试使用水槽假脱机目录摄取到 HDFS(SpoolDir 我正在使用Cloudera Hadoop 5.4.2。(Hadoop 2.6.0,Flume 1.5.0)。 它适用于较小的文件,但适用于较大的文件时失败。请在下面找到我的测试场景: < li >千字节到50-60兆字节的文件,处理时没有问题。 < li >大于50-60MB的文件,它将大约50MB写入HDFS,然后我发现flume代
-
使用水槽将文件从假脱机目录移动到HDFS
我正在为我公司的 POC 实施一个小型 hadoop 集群。我正在尝试使用Flume将文件导入HDFS。每个文件都包含如下 JSON 对象(每个文件 1 个“长”行): “objectType”是数组中对象的类型(例如:事件、用户…)。 这些文件稍后将由多个任务根据“对象类型”进行处理。 我正在使用spoolDir源和HDFS接收器。 我的问题是: > 当flume写入HDFS时,是否可以保留源文
-
绑定OpenGL上下文时使用假GLFW _ VISIBILE提示的目的
我目前正在遵循一个教程,其中有创建窗口的初始化代码 注意< code > glfwWindowHint(GLFW _ VISIBLE,GL _ FALSE);提示被禁用,那么在创建窗口、设置按键回调、绑定opengl上下文之后,它又被启用< code > glfwShowWindow(window); 留档不建议这样做,删除两行似乎不会改变任何事情。为什么首先禁用提示? 教程:https://lw
-
可以使jQuery UI Datepicker禁用周六和周日(和节假日)吗?
问题内容: 我使用日期选择器选择约会日期。我已经将日期范围设置为仅下个月。很好 我想从可用选项中排除周六和周日。能做到吗?如果是这样,怎么办? 问题答案: 有一个选项,该选项需要为每个日期调用一个函数,如果允许日期,则返回true,否则,则返回false。从文档: ShowShow之前 该函数将日期作为参数,并且必须返回一个数组,该数组的[0]等于true/false,表示此日期是否可选,默认表示
-
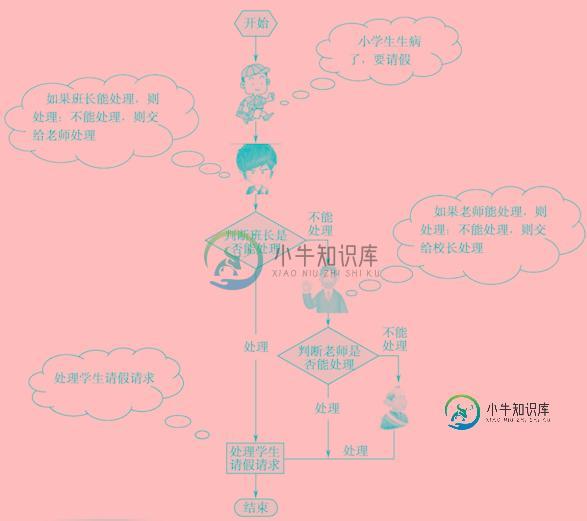 Java使用责任链模式处理学生请假问题详解
Java使用责任链模式处理学生请假问题详解本文向大家介绍Java使用责任链模式处理学生请假问题详解,包括了Java使用责任链模式处理学生请假问题详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java使用责任链模式处理学生请假问题。分享给大家供大家参考,具体如下: 一. 模式定义 在责任链模式中,很多对象由每一个对象对其下家的引用而连接起来,形成一条链。客户端应用请求在这个链上进行传递,直到链上的某一个对象决定处理此请求。发出
-
向点击事件监听器添加“返回假”有什么作用?
问题内容: 很多次,我在HTML页面中都看到过这样的链接: 在那里的作用是什么? 另外,我通常不会在按钮中看到它。 在任何地方都指定了吗?在w3.org的某些规格中? 问题答案: 事件处理程序的返回值确定默认浏览器行为是否也应发生。在单击链接的情况下,将在链接之后,但是区别最明显的是表单提交处理程序,如果用户输入信息有误,您可以在其中取消表单提交。 我不相信对此有W3C规范。像这样的所有古代Jav
-
我可以假设long int的大小始终为4个字节吗?
问题内容: 是否总是真的(这是我的理解是对的代名词)是个字节? 我可以依靠吗?如果不是这样,那么对于基于POSIX的操作系统是否正确? 问题答案: 除了之外,标准没有关于任何整数类型的确切大小。通常,在32位系统上为32位,在64位系统上为64位。 但是,该标准并未指定 最小 尺寸。从C标准的 5.2.4.2.1节开始: 1 以下给出的值应被适合用于预处理指令的常量表达式代替。此外,除了和之外,以
-
 易语言假死无响应采用处理事件解决办法
易语言假死无响应采用处理事件解决办法本文向大家介绍易语言假死无响应采用处理事件解决办法,包括了易语言假死无响应采用处理事件解决办法的使用技巧和注意事项,需要的朋友参考一下 处理事件() 一个比较简单的理解是:让程序反应过来 这个函数一般是用在延时前面或后面,如果不用的话程序很容易形成假死,造成程序无响应 如下图,虽然这个程序还在运行,但是界面上东西是显示不了的,比如标签,编辑框,画板,会有一个圆圈转啊转 加了处理事件() 就可以避免
-
sqlplus无法在windows上假脱机名称以点开头的文件
我正在使用一些windows脚本,这些脚本涉及使用sqlplus后台处理文件。我不断收到错误: 我能够将问题限制在一个相当小的范围内:在windows中,我无法假脱机一些名称以点开头的文件。在windows cmd中,我输入了sqlplus 然后尝试了以下命令: 很奇怪,只有<代码>。测试失败。但这正是我所需要的。我在Linux中尝试了相同的命令,没有问题。我在windows上使用sqlplus
-
在跳过假期+乔达时间的同时计算结束日期
问题内容: 我想计算事件的 结束日期 (和时间)。我知道 开始日期 和 持续时间 (以分钟为单位)。但: 我不得不跳过假期-非经常性情况 我必须跳过周末-经常性的情况 我 不必 计算工作时间(例如:从8:00 am到5:00 pm)-经常出现的情况,但粒度要细一些 是否有使用Joda时间库实现这些情况的简单方法? 问题答案: Jodatime将为您提供帮助-我要说很多-但您需要自己编写逻辑,一个循
-
在Spring Boot中使用假客户端同时进行Rest API调用
假设我有2个微服务A和B。现在对于服务A上的特定请求,A需要对B进行多个相同API的API调用(使用不同的参数)。最初,我使用模拟客户端在微服务之间进行Rest调用[隐式支持负载平衡、服务发现和添加端口元数据等来自模拟客户端]。 这种方法的问题是,调用是同步的,并且需要大量时间。如何/使用什么来触发多个请求并以非阻塞和异步的方式等待响应? TIA!
-
在安排quartz计划程序时设置周末或假日策略
我们正在使用quartz来调度批处理作业。我们正在尝试使用周末或假日策略来触发工作。看看quartz的实现,使用日历实现周末策略是很容易的,但是对于假日的实现。如果在创建工作之前提前定义了假日,那么在自定义日历中与周末一起处理就很容易了。但是,如果可以动态地创建假日,并且在运行时应用策略,我认为如果我们通过重写getNextTimeAfter方法在CronTrigger中处理这一点会更好。但那不起
-
partitioningBy必须生成一个包含真与假条目的地图吗?
partitioningBy收集器将谓词应用于流中的每个元素,并生成一个从布尔值到流中满足或不满足谓词的元素列表的映射。例如: 正如在PartitionBy的目的是什么中所讨论的,观察到的行为是PartitionBy总是返回一个包含true和false条目的映射。例如。: 这种行为真的是在某个地方指定的吗?Javadoc只说: 返回一个收集器,该收集器根据谓词对输入元素进行分区,并将它们组织到
-
如何修复 CORS 错误以提供虚假开发数据 [重复]
有没有办法避免我遇到的CORS错误? 我正在写一门关于d3的课程。我希望学生能够将JSON、CSV和其他数据加载到他们的网页。他们被指示在本地打开他们的html页面,通过右键单击并使用打开 这是提供给学生的虚假数据,仅用于开发目的。有什么方法可以改变github上dev文件的设置吗?或者有什么方法可以在本地实现? 谢谢艾玛
-
Firebase电子邮件验证总是返回假用户未验证。ios
我正在实施firebase电子邮件验证,但是当用户收到电子邮件时,它会重定向到应用程序,这很好。当我尝试使用经过验证的电子邮件 始终返回 false。以下是我的代码: