《万朋数智》专题
-
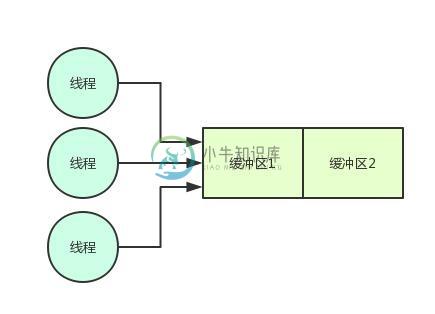 中间件解决百万并发的问题!
中间件解决百万并发的问题!主要内容:一、对Java并发仍停留在理论阶段,二、中间件系统的内核机制:双缓冲机制,三、百万并发的技术挑战,四、内存数据写入的锁机制以及串行化问题,五、内存缓冲分片机制+分段枷锁机制,六、缓冲区写满时的双缓冲交换,七、且慢!刷写磁盘不是会导致锁持有时间过长吗?,八、内存 + 磁盘并行写机制,九、为什么必须要用双缓冲机制?,十、总结这篇文章,给大家聊聊一个百万级并发的中间件系统的内核代码里的锁性能优化。 很多同学都对Java并发编程很感兴趣,学习了很多相关的技术和知识。比如volatile、Ato
-
 万物纵横 测试开发 线上面试
万物纵横 测试开发 线上面试问的我直冒冷汗, 面试官太专业, 招的给的最高11k需要这个水平了么? 1. devops 什么流程:怎么保证开发svn的代码没有问题,回答直接开发换包来跑自动化, 说我们测试没有打通devops吧?之前项目白盒部分都是开发把控的啊? 2. 性能测试的sample怎么用, 断言有什么用 性能测试的怎么去模拟请求,回答间隔时间timer ,问怎么模拟随机时间 3. 用的来性能测试jmeter做的尖峰
-
 Wind(万得) 提前批 | 一面+笔试+hr面
Wind(万得) 提前批 | 一面+笔试+hr面一面 a 面 实习内容? 课程方面问题? 说说在字节的的项目 开发一个项目,React 和 Vue?JS 和 TS,技术选型如何去选,还有一些相关的东西怎么去思考。 b 面 HTTP 五层模型 UDP/TCP,原理,http3的协议是啥,怎么保证稳定? 说说实习,在字节的项目 二面 笔试题,不让往外面发,不过难度不大。 三面(hr面) 家是哪里的,上海base可以接受吗? 预期薪水是多少? 你的专
-
 万德java后端开发提前批面试
万德java后端开发提前批面试一面 一面主要是八股 字符串怎么进行比较的, 实现逻辑是什么 2. 内存溢出可能的原因有哪些,怎么排除与解决 3. mybits 中 $ 和 # 的区别 4. mysql 中 select * from a, b 是什么连接,产生的结果集是什么 5. springboot中的常用的注解有哪些 6. 项目中用到了mongodb,问使用 mongodb 的考虑是什么 二面拷打项目: 为了多掌握点技术,
-
 万物心选 前端实习二面 面经
万物心选 前端实习二面 面经时间:2023.5.30 时长:1h 面试岗位:前端实习 base: 北京 问题 随机问 自我介绍 什么时候开始学习前端 为什么想要学习前端 打算未来的工作是偏前端还是偏后端 怎么考虑为啥去做前端 所以实习经历是Java? 当时考虑就是想要后端? 也就是毕业做前端还是后端考虑不是那么明显?(我其实也纠结,如实相告了) 个人课程是自发想要录制的? 当时为啥要想录制一个课程? 其他项目都是练手的项目吗
-
给定一个1000列100万行的训练数据集,怎么进行降维?
本文向大家介绍给定一个1000列100万行的训练数据集,怎么进行降维?相关面试题,主要包含被问及给定一个1000列100万行的训练数据集,怎么进行降维?时的应答技巧和注意事项,需要的朋友参考一下 对大样本进行抽样使其变为小样本 可以将分类变量和数值变量分开,同时删掉相关联的变量,对于数值变量,可以通过相关性分析来找到相关的特征,对于分类变量可以通过卡方检验来找到 还可以通过PCA降维,获取包含最多
-
如何在Redis中批量删除数十万个带有特殊字符的键
问题内容: 我们有数十万个Redis键的列表,其中包含各种特殊字符,我们希望将其批量删除。 但是,对于以下情况,我似乎找不到答案: 我们有大量的钥匙(数十万个) 键具有各种特殊字符,例如双引号(“),反斜杠(),各种奇怪的Unicode字符等。 我们正在使用Windows Redis-Cli客户端 奖励:理想情况下,我们可以在MULTI / EXEC事务中发出此命令,因此我们也可以自动删除SET和
-
 ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例
ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例本文向大家介绍ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例,包括了ASP.NET MVC5+EF6+EasyUI 后台管理系统(81)-数据筛选(万能查询)实例的使用技巧和注意事项,需要的朋友参考一下 前言 听标题的名字似乎是一个非常牛X复杂的功能,但是实际上它确实是非常复杂的,我们本节将演示如何实现对数据,进行组合查询(数据筛选) 我们都知道Ex
-
重新启动Spark Structured Streaming Job会消耗数百万条Kafka消息并死亡
我们有一个运行在Spark2.3.3上的Spark流应用程序 基本上,它开启了一条Kafka流: 我们尝试: > spark.streaming.backpressure.enabled=true以及spark.streaming.backpressure.initialrate=2000和spark.streaming.kafka.maxratePerpartition=1000和spark.s
-
如何使用数据流在GCS上自动编辑超过10万个文件?
我在Google云存储上有超过10万个包含JSON对象的文件,我想创建一个镜像来维护文件系统结构,但从文件内容中删除一些字段。 我试图在谷歌云数据流上使用Apache Beam,但它拆分了所有文件,我不能再维护结构了。我正在使用。 我的结构类似于<code>reports/YYYY/MM/DD/ 如何使数据流不拆分文件并使用相同的目录和文件结构输出它们? 或者,是否有更好的系统对大量文件进行此类编
-
如何使用Java从DB2数据库中高效地检索200万条记录?
-
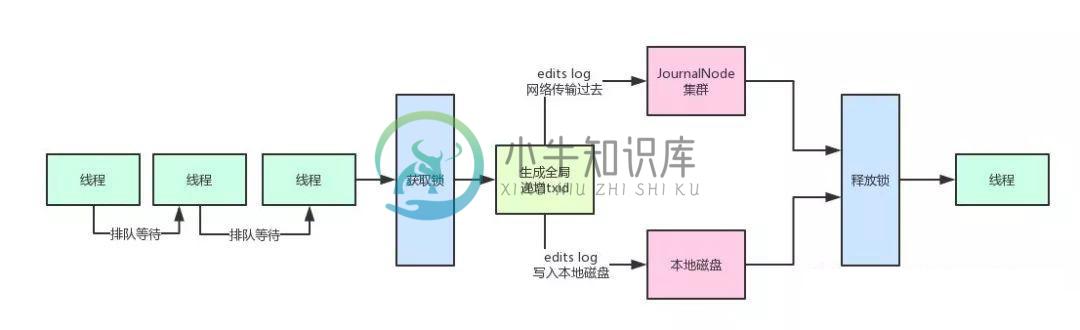 放几十亿数据的系统还能抗每秒上万并发,牛不牛?
放几十亿数据的系统还能抗每秒上万并发,牛不牛?主要内容:一、写在前面,二、问题源起,三、HDFS优雅的解决方案,(1)分段加锁机制 + 内存双缓冲机制,(2)多线程并发吞吐量的百倍优化,(3)缓冲数据批量刷磁盘 + 网络的优化,四、总结一、写在前面 上篇文章我们已经初步给大家解释了Hadoop HDFS的整体架构原理,相信大家都有了一定的认识和了解。 如果没看过上篇文章的同学可以看一下:《兄弟们给我10分钟,带你了解一下大数据技术的入门原理和架构设计!》这篇文章。 本文我们来看看,如果大量客户端对NameNode发起高并发(比如每秒上千次)
-
将具有数百万条记录的表从一个数据库复制到另一个数据库-Spring Boot Spring JDBC
在一个小例子中,我们必须将数以百万计的记录从teradata数据库复制到Oracle DB。 环境:Spring Boot Spring JDBC(jdbcTemplate)Spring REST Spring调度程序Maven Oracle Teradata 使用Spring JDBC的batchUpdate将数据插入目标数据库Oracle。 在源数据库的SQL查询中使用teradata的“前1
-
 Android仿微信朋友圈点击加号添加图片功能
Android仿微信朋友圈点击加号添加图片功能本文向大家介绍Android仿微信朋友圈点击加号添加图片功能,包括了Android仿微信朋友圈点击加号添加图片功能的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了类似微信朋友圈,点击+号图片,可以加图片功能,供大家参考,具体内容如下 xml: NinePhotoView.java Measure 我们的子View三个一排,而且都是正方形,所以我们上面通过循环很好去得到所有子View的
-
可能的gcc错误,而成为模板专门化的朋友
在SO上回答另一个问题时,我遇到了一个有点可疑的gcc编译器错误。令人不快的片段是 谁的最后一行给出了著名的警告 好友声明'