《拓维信息》专题
-
微信信息查看与设置
1. 小程序基本信息获取 微信服务号名称 微信原始ID 首页 -> 设置 -> 基本设置 微信小程序 APPID 微信小程序 AppSecret (小程序密钥) 首页 -> 开发 -> 开发设置 2. 小程序设置 位置: 首页 -> 开发 -> 开发设置 2.1 服务器域名 需要在小程序中请求小能服务器地址时添加服务域名。如:希望在小能中显示微信用户名称时。 2.2 业务域名 什么时候添加业务域名
-
查找Apache Storm中运行的拓扑jar版本
我有一个运行的storm拓扑开始使用一个打包的JAR。我正在尝试查找拓扑正在运行的jar的版本。据我所知,Storm只会显示正在运行的Storm版本,而不会显示正在运行的拓扑版本。 运行“storm version”命令只给出storm运行的版本,我在storm UI的拓扑部分中没有看到任何指示拓扑版本的内容。 有没有办法让Storm报告这一点,还是我最好的办法设置一个属性文件?理想情况下,这将通
-
如何以编程方式杀死风暴拓扑?
问题内容: 我正在使用Java类向拓扑集群提交拓扑,并且我还计划使用Java类取消拓扑。但是根据storm 文档,以下命令用于终止拓扑,并且没有Java方法(这有正当的理由) 那么从Java类中调用Shell脚本杀死拓扑就可以了吗?还有其他杀死拓扑的方法吗? 另外,如何获取风暴群集中正在运行的拓扑的状态? 问题答案: 要杀死拓扑,您可以尝试以下方法 获取拓扑运行状态
-
apache storm单元测试活动拓扑中的bolt
我有一个storm拓扑,它有一个连接到kafka队列的spout,并将元组转发到我的bolt进行处理。我只想对bolt进行单元测试,而不是中的整个片段。然而,我还想在一个storm拓扑实例中测试bolt,而不仅仅是它的纯功能。原因是bolt实际上将处理后的数据发送到一个cassandra数据库。 所以我实现这一点的一种方法是制作一个测试喷口,将其连接到bolt,并通过测试喷口将测试元组发送到bol
-
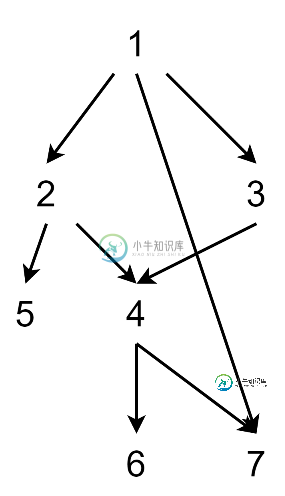 有向无环图分阶段的拓扑排序
有向无环图分阶段的拓扑排序是否有一种算法,在给定一个未加权有向无环图的情况下,将所有节点排序到一组节点列表中,从而 保留拓扑顺序(即,对于所有边
-
Apache Flink Wordcount:流拓扑中未定义运算符
我正在浏览Apache Flink的基本WordCount示例。这是代码: 当我尝试在群集中部署此作业时,请使用: 我得到这个例外: 我不明白为什么,因为我是Flink的新手。请帮助我理解这个问题。谢谢你。 当我尝试直接从IDE运行此代码而不将JAR部署到集群时,它完全可以正常工作。
-
Apache storm拓扑中的Apache kafka偏移量提交
我正在设计一个ApacheStorm拓扑(使用streamparse),它由一个喷口(ApacheKafka喷口)和一个具有并行性的螺栓构建 螺栓分批读取信息。如果批量成功完成,我手动提交apache kafka偏移。 当mysql上的螺栓插入失败时,我不会在Kafka中提交偏移量,但是一些消息已经在喷口发送到螺栓的消息队列中。 应该删除队列中已经存在的消息,因为我无法在不丢失先前失败消息的情况下
-
用Java拓扑套件或GeoTools解析GeoJSON文件
例如,如果您有一个像这样的带有多边形的GeoJSON文件(用于测试的简单文件) 使用像这样的地质工具 这里的问题是多边形p只包含geojson文件的最后一个多边形。如果这个文件有很多多边形,我应该如何解析它? 像这样使用JTS2GEOJSON
-
在Apache storm中提交字数拓扑时出错
这是我尝试运行的基本wordcount拓扑。但我收到的错误是“信息组织”。阿帕奇。暴风雨动物园管理员。服务器SessionTrackerImpl-SessionTrackerImpl已退出循环!'。有人能帮我吗?? 当我移除集群时。shutdown(),在我按下cntrl c之前,tweets会一直出现。wordcount也不会显示##
-
将Storm-wordCount拓扑转换为使用Kafka喷口
我是Storm和Kafka的新手,我可以在一段时间后在本地虚拟机上安装它们。我目前有一个有效的wordCount拓扑,从dropBox文本文件中提取句子: 现在我想升级我的喷口,使用Kafka的文本,以便在拓扑结构中提交到我的下一个螺栓。我试图在git中遵循许多文章和代码,但没有任何成功。例如:这个Kafka喷口。谁能帮助我,给我一些方向,以便实现新的spout.java文件?谢谢你!
-
hyperledger fabric:以图形方式发现网络拓扑
我刚开始使用Hyperledger面料。我正在寻找一个工具,将演示图形化的整个网络及其运作。 有没有现有的项目这样做? null
-
Kafka流处理器api允许多集群拓扑?
使用kafka processor API(不是DSL)读取源主题并写入目标主题,对于单个kafka集群设置(也就是说,如果源主题和目标主题都驻留在同一集群上)来说工作很好,但是当源主题和目标主题驻留在不同的kafka集群上时,我将获得目标处理器上下文的NullPointerException 我们如何使用kafka streams处理器API从一个集群中的一个主题写到另一个集群中的另一个主题?
-
Section-1 Traverse 第1节 遍历 - TopologicalSort 拓扑排序
问题 对有向图 G 进行拓扑排序。 解法 拓扑排序可以通过应用深度优先搜索来解决。 对于有向图 G 中的每个节点 i ,都进行一次深度优先搜索,由于DFS的特性,每递归一次都尝试让节点 i 走的更远,直到终点。因此从节点 i 出发DFS所经过的节点数量可看作是节点 i 到终点的距离 d 。然后按照距离 d 对所有节点进行排序即可得到拓扑排序。其中将终点到自己的距离作为 1 。 下面以有向图 G 作
-
Java N维数组
问题内容: 我需要有一个n维字段,其中n基于构造函数的输入。但是我什至不确定这是否可行。是吗? 问题答案: 快速的解决方案:你可以用非通用近似它的的…要深,因为你需要。但是,使用快速可能会很尴尬。 另一种需要更多工作的选择可能是使用基础平面数组表示形式来实现您自己的类型,在其中您内部计算索引,并为访问器方法提供vararg参数。我不确定它是否完全可行,但可能值得一试… 粗略的示例(未经测试,没有溢
-
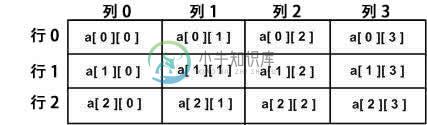 C#多维数组
C#多维数组主要内容:1、二维数组,2、初始化二维数组,3、访问二维数组种的元素C# 中同样支持多维数组(也可称为矩形数组),它可以是二维的,也可以是三维的,多维数组中的数据以类似表格(行、列)的形式存储,因此也被称为矩阵。 要创建多维数组,我们需要在声明数组的方括号内添加逗号,例如: int[,] arr=new int[3,3]; // 声明一个二维数组 int[,,] arr=new int[3,3,3]; // 声明一个三维数组 1、二维数组