《蓝湖》专题
-
源映射错误:请求失败,状态为404资源URL:http://{mywebsite}/js/app。js源映射URL:bootstrap。js。拉维湖地图
在发布帖子时,我在网络控制台上看到了上述错误。 源地图错误:请求失败,状态404资源URL:超文本传输协议://{mysite}/js/app.js源地图URL:bootstrap.js.map 我的资源/js/app.js是这样的 还有这个网页。js看起来像这样 我的部分工作输出 我的错误是这样的
-
谷歌地图静态地图折线穿过湖泊,河流,山脉
问题内容: 我的程序使用Google Maps的网络服务路线来查找两点之间的路线。结果被解析并存储在变量中。 然后,此变量用于组成google静态地图URL。 解析和URL正常工作。问题是绘制的“路线”穿过湖泊和山脉。 解析功能: 杰森回应: https://maps.googleapis.com/maps/api/directions/json?origin=-22.978823,-43.233
-
无法在Azure数据湖中递归删除文件夹
我想删除Azure Data Lake中的一个文件夹。该文件夹包含子文件夹和文件。这就是我尝试过的: 它给了我以下错误:
-
三角洲湖表的SQL视图
我需要在数据库中创建一个现有的三角洲湖表上的抽象。是否可以在Spark中基于Delta Lake表创建SQL Server类型的SQL视图?
-
Spark dataframe(在Azure Databricks中)保存在数据湖(gen2)上的单个文件中,并重命名该文件
我试图实现与此相同的功能,所以除了我的文件位于Azure Data Lake Gen2,我在Databricks Notebook中使用pyspark之外,将Spark dataframe保存在hdfs位置上的单个文件中。 下面是我用来重命名文件的代码段 1)重命名databricks(pyspark)写入Azure DataLakeGen2的文件是否正确,如果不正确,我还能如何完成?
-
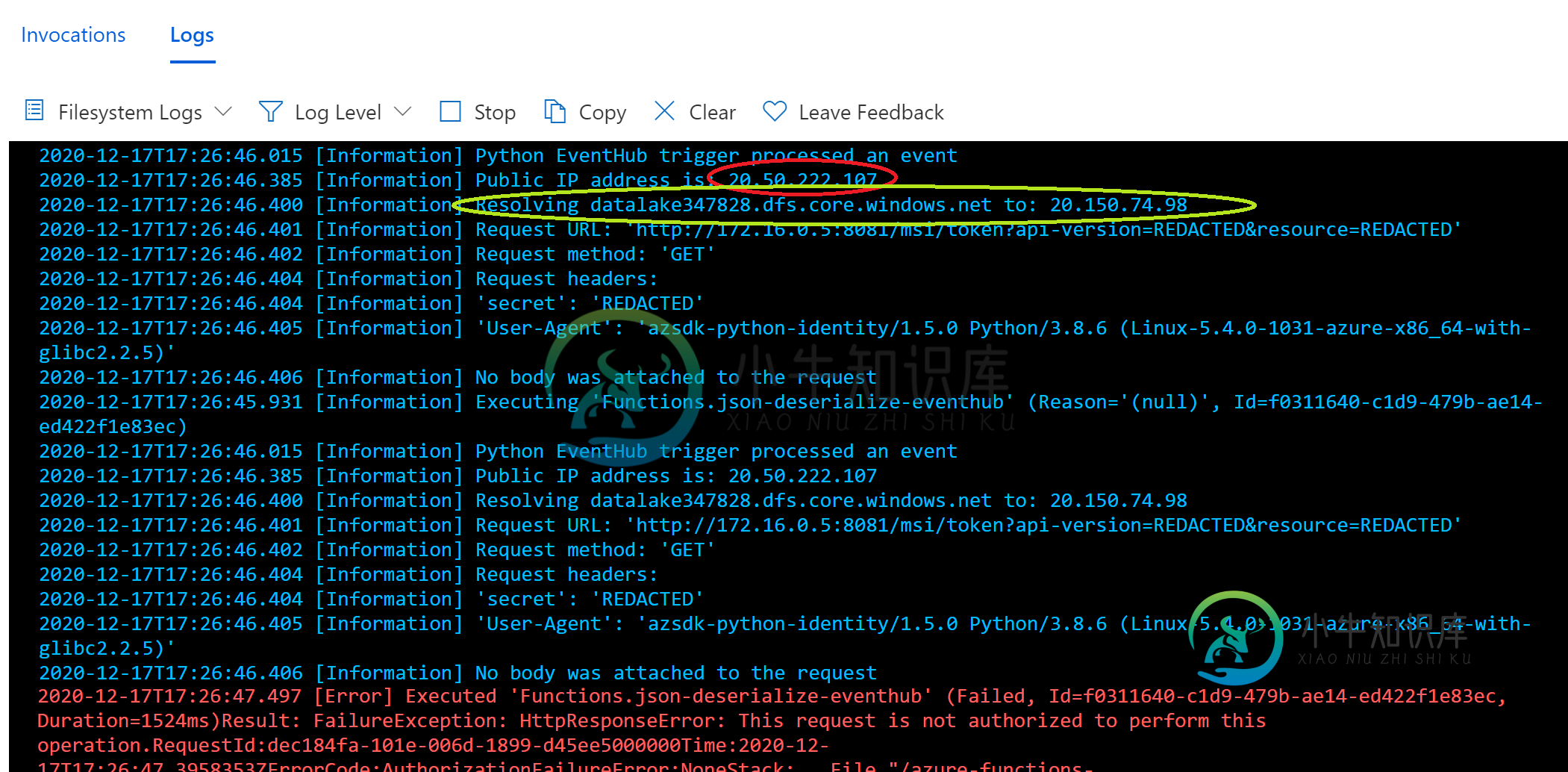 Azure数据湖:此请求未被授权执行此操作
Azure数据湖:此请求未被授权执行此操作此问题不是此请求的重复,未授权执行此操作。Azure blobClient 我想从Azure函数访问Azure数据湖。我使用托管标识,并在我的数据湖IAM选项卡中为该功能分配了一个“所有者”角色。一切工作,但只有当我允许“所有网络”在我的数据湖。当我切换到“选定的网络”时,我会得到“此请求未被授权执行此操作”,尽管我将我的Azure函数的所有出站IP地址添加到了我的数据湖的防火墙规则中。 我在Az
-
从Synapse笔记本覆盖Azure数据湖Gen 2中的文件引发异常
作为从Azure Database ricks迁移到Azure Synapse Analytics Notebook的一部分,我面临下面解释的问题。 使用以下命令从Azure Datalake Storage Gen 2读取CSV文件并将其分配给pyspark dataframe。 处理完此文件后,我们需要覆盖它,并使用以下命令。 它的作用是,删除路径"csvFilePath"上的现有文件,然后失
-
无法使用Azure数据块访问已装载的Azure数据湖存储
我正在使用Azure数据库。使用Microsoft学习网站上指定的文档,我设法将BLOB存储(ADLS Gen2)挂载到我的数据库。 但是,当我尝试列出已装入的存储的内容时,我收到以下错误: 我已经检查了权限,我的Service主体被分配了角色“STORAGE BLOB DATA CONTRIBUTOR”,它允许对我的存储容器进行R/W访问。 任何人都知道我错过了哪个部分来使它工作?将不胜感激。
-
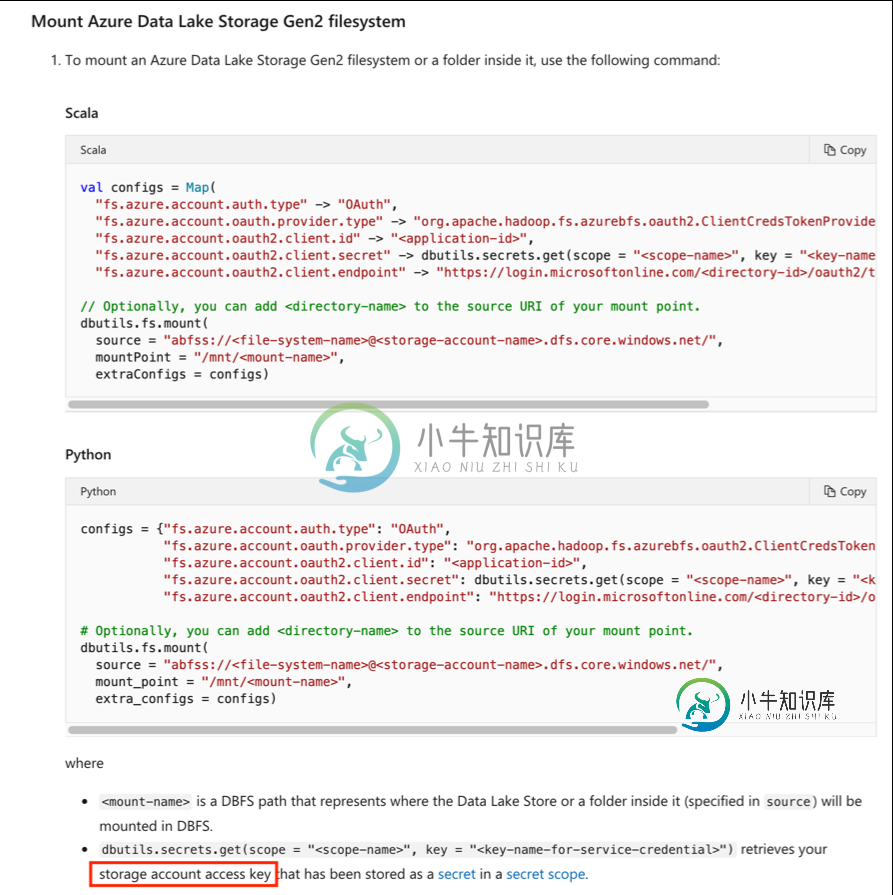 Azure数据块通过服务主体访问Azure数据湖存储Gen2
Azure数据块通过服务主体访问Azure数据湖存储Gen2那么,如果仍然需要存储帐户访问密钥,服务帐户的目的是什么 还有一个主要问题-是否可以完全删除存储帐户访问密钥并仅使用服务主体?
-
在 Azure 数据湖 Gen1 中解压缩文件而不将文件移动到 Azure 数据砖文件系统的简单且最佳的方法是什么?
解压Azure数据湖Gen1中的文件而不将文件移动到Azure Database ricks文件系统的最佳方法是什么?目前,我们使用Azure数据库进行计算,storage.We有将数据移动到DBFS的限制。 已在 DBFS 中挂载 ADLS,但不确定如何继续
-
json 文件演变为三角洲湖的动态模式
我正在建立一个Azure Databricks delta-lake,并且正在努力将我的json数据加载到delta-lake中。json中有100多种不同的文件格式。全部储存在数据湖中。 现在,我试图避免编写100个不同的python笔记本,而是构建一个元数据驱动的笔记本,它应该能够处理所有不同的json格式。 我能够得到进入三角洲湖的第一批数据,到目前为止一切顺利。问题是当我加载到特定delt
-
三角洲湖恢复问题(数据块)
我正在使用Azure数据块,并在ADLS Gen2上创建了一个delta表。 我已经创建了4个版本的三角洲湖。 我试图用下面的命令恢复到版本2。 有人能告诉我为什么我不能恢复到旧版本吗?现在发生如下错误。
-
 EMR和S3上的三角洲湖(OSS)表-真空需要很长时间,没有工作
EMR和S3上的三角洲湖(OSS)表-真空需要很长时间,没有工作我正在使用开源版本将大量数据写入Databricks Delta lake,该版本在AWS EMR上运行,S3作为存储层。我正在使用EMRFS。 为了提高性能,我每隔一段时间就会压缩和清空表: 我已经阅读了这篇文章火花:作业之间的长延迟,这似乎表明它可能与镶木地板有关?但是我在增量端没有看到任何选项来调整任何参数。
-
将Azure application Insight日志文件导出到Azure数据湖存储
我可以通过azure application insight跟踪我的应用程序日志文件,还可以导出xls表http://dailydotnettips.com/2015/12/04/export-application-insights-data-to-excel-its-just-a-single-click/,但我需要将我的所有日志文件存储到azure data lake storage中,以便
-
三角洲湖畔蜂巢桌
我是火花三角洲湖的新手。我正在创建三角洲表顶部的配置单元表。我有必要的jars delta-core-shaded-assembly2.11-0.1.0.jar,hive-delta2.11-0.1.0.jar;在配置单元类路径中。设置以下属性。 但是在创建表时 两个表的架构匹配。堆栈详细信息:Spark:2.4.4Hive:1.2.1 任何帮助都是非常感谢的。提前谢了。