《网易》专题
-
 保护网络免受攻击
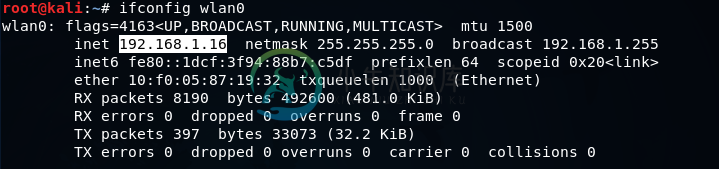
保护网络免受攻击为了防止我们的网络在预连接攻击和获取访问部分中解释的先前攻击破解方法,我们需要访问路由器的设置页面。每个路由器都有一个web页面,我们可以在页面中修改路由器的设置,它通常位于路由器的IP上。首先,获得我们自己的计算机的IP,为此运行命令。如下面的屏幕截图所示,突出显示的部分是计算机的IP: 现在打开浏览器并访问:。对于此示例,计算机的IP为。通常,路由器的IP是子网的第一个IP。目前,它是,我们只
-
 统计网站在线人数
统计网站在线人数主要内容:使用 HttpSessionListener 和 HttpSessionAttributeListener 实现,使用 HttpSessionBindingListener 实现本节我们利用 Servlet 监听器接口,完成一个统计网站在线人数的案例。当一个用户登录后,显示欢迎信息,同时显示出当前在线人数和用户名单。当用户退出登录或 Session 过期时,从在线用户名单中删除该用户,同时将在线人数减 1。 本案例可以通过如下 2 种方案实现: 使用 HttpSessionListen
-
 [实例]抓取网络照片
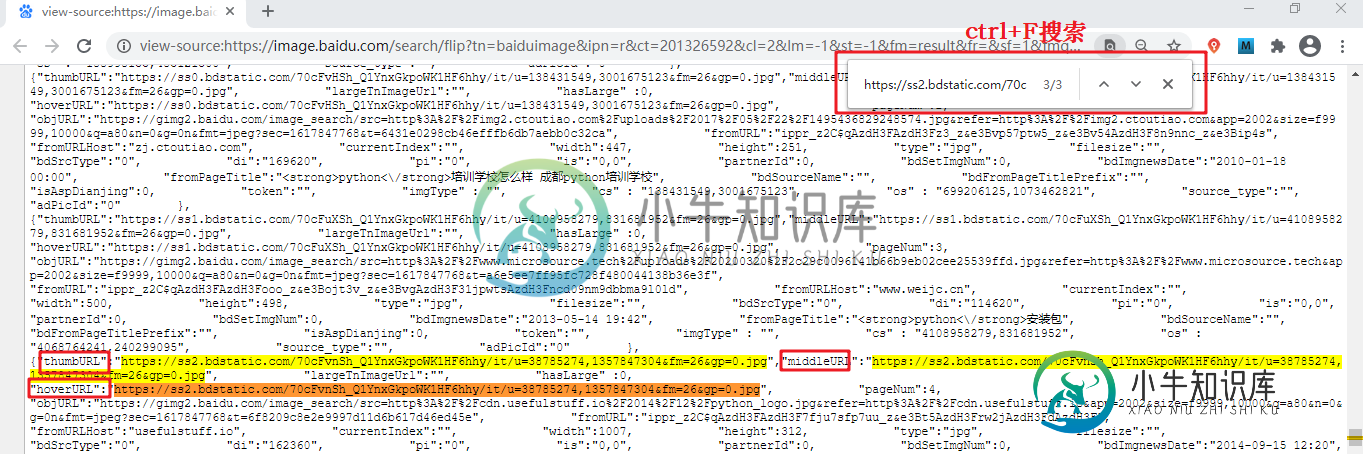
[实例]抓取网络照片主要内容:分析url规律,写正则表达式,编写程序代码本节编写一个快速下载照片的程序,通过百度图片下载您想要的前 60 张图片,并将其保存至相应的目录。本节实战案例是上一节《 Python Request库安装和使用》图片下载案例的延伸。 分析url规律 打开百度图片翻页版( 点击访问),该翻页版网址要妥善保留。其 url 规律如下: 百度为了限制爬虫,将原来的翻页版变为了“瀑布流”浏览形式,也就是通过滚动滑轮自动加载图片,此种方式在一定程度上限制了
-
[实例]爬虫抓取网页
主要内容:导入所需模块,拼接URL地址,向URL发送请求,保存为本地文件,函数式编程修改程序本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块 本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块: 拼接URL地址 定义 URL 变量,拼接 url 地址。代码如下所示:
-
VBA填充网页文本框
我正在尝试用getelementbyclassname()填充这个文本框。值但是不管用。它只有在我使用innertext时才有效,但这不是我想要的,因为它对文本进行了硬编码。我该如何处理这个元素以便向它传递文本呢? VBA:
-
504网关超时nginx/1.10.3(Ubuntu)
我正在尝试使用Nginx在Ubuntu16.4服务器上托管Django1.11应用程序。但是在运行服务器之后,我得到了 *1从上游读取响应标头时上游超时(110:连接超时),客户端:118.179.95.25,服务器:18.136.204.142,REQU$ 2019/07/24 18:13:13[错误]15221#15221:*1从上游读取响应标头时上游超时(110:连接超时),客户端:118.
-
网络连接丢失错误
我正在尝试从macos上使用swift开发的应用程序连接到realm object server 当我尝试连接时,会出现“网络连接丢失”错误,但我可以从浏览器中毫无问题地打开领域服务器。。顺便说一句,这个问题最近发生了,它在几周前工作正常 这里,用户总是,错误描述是 这发生在本地服务器和一个托管在数字海洋 服务器版本1.8。3. xcode控制台日志 2018-01-15 12:46:07.077
-
发布后未加载网站
我有一个网站,我已经使用了很长时间,没有任何问题。我做了一些改进来提高性能,包括将数据存储在缓存中,以及改变网站与数据库的交互方式。然而,自从将网站发布到它的位置后,现在每当我试图加载它时,它都返回一个空白页。 每当我尝试加载它时,我都会收到来自该站点的错误电子邮件,显示“外部组件已引发异常”的异常消息。我有几个地方可以发送错误电子邮件,它们都在触发,每个地方提供的堆栈跟踪略有不同,如下所示。 堆
-
 发布没有roslyn的网站
发布没有roslyn的网站我正在尝试使用Visual Studio 2015和. NET 4.5.1创建Web应用程序。当我发布网站时,Visual Studio会创建名为的文件夹。 我知道它是用来动态编译代码的,但不幸的是我的主机提供商不允许我在他们的服务器上执行编译器。 如何像以前版本的Visual Studio那样在没有的情况下发布网站? 编辑:我在尝试访问我的网站时遇到了这个错误。 似乎IIS试图执行< code>
-
用Python模拟网页[重复]
我正在努力解决的问题是如何从requests.get()调用将数据插入到响应对象中。我已经看了一页又一页的如何嘲笑的例子,但没有一个清晰简单的解释如何做到这一点。 我只需要这么做。我有一个来自原始网站的html文件,我希望响应数据来自该文件,而不是网站。 有什么想法吗? 然后我意识到我不需要嘲笑任何东西,从而更加简化了事情。我更改了get_html(),以检查app.testing标志是否为tru
-
无法登录Jsoup的网站,
我正在尝试使用jsoup登录一个网站,我很确定我正在解析所有需要解析的东西,我只是不知道出了什么问题。 我用这个做参考:http://cs.harding.edu/fmccown/android/Logging-into-Pipeline.pdf 以下是我的AsycntTask doInBackground中的代码: 但问题是,当我登录时,它不包含页面的文档,它包含一个错误页面的文档,该页面只显示
-
Chrome网络驱动程序-Python
当我完成自动化后,Chrome Web驱动程序仍在后台运行,是否可以自动关闭它,而无需通过任务管理器执行?
-
504网关超时介质庙
/etc/httpd/conf.d/fcgid.conf 我有...见下文 我已经尽力做到最好了。为了测试这一点,我只是运行下面的函数。 在与支持人员聊天后,我被告知需要编辑nginx.conf,并被转到以下帖子http://blog.secaserver.com/2011/10/nginx-gateway-time-out/ 在服务器设置中找不到任何值。client_header_timeout
-
如何允许ASP的CORS。网
我试图从JS/Ajax向我的WebAPI发出请求时遇到了问题。在我的解决方案中,我有一个发布在srv02:2400上的Web API,我的网站发布在srv02:2300上 当我导航到页面时http://srv02:2300/all-请求。aspx,页面加载正常,除了应该来自我的API的数据 我得到了一个错误: 但是,如果我把url超文本传输协议://srv02:2400/api/请求/查找/1粘贴
-
 星网锐捷一面c++(25min)
星网锐捷一面c++(25min)之前笔试写的不好 四个编程都不太会 通知面试很意外 面试官秃头 压迫感很强 1.自我介绍 2.数组和链表区别 分别什么情况使用 3.有哪几种链表 讲讲区别和特点 4.堆和栈的区别 5.什么时候会栈溢出 6.判断回文串,参数一个字符串一个长度,函数怎么写,讲下思路 7.冒泡排序过程 8.冒泡排序时间复杂度和空间复杂度 9.快排,堆排时间复杂度 10.有几种时间复杂度 11.tcp和udp区别 12.