《同花顺》专题
-
尝试使用茉莉花和角质时出错
问题内容: 当我尝试使用 $ httpBackend.flush();时 我收到错误 TypeError:$ browser.cookies不是一个函数。 我找不到有关这种错误和解决方案的任何信息。 角度:1.3.15 茉莉花:2.3.4 问题答案: 我相信您在版本中使用的是角度模拟,而您的代码使用的是angular 。请检查您是否在为应用程序中实现的版本使用模拟程序。同样,提供您的茉莉花测试配置
-
数据源用完时如何停止火花流
我有一个spark流媒体作业,它每5秒钟读取一次Kafka,对传入的数据进行一些转换,然后写入文件系统。 这实际上不需要是一个流式作业,实际上,我只想每天运行一次,将消息排入文件系统。但我不知道如何停止这项工作。 如果我向streamingContext传递超时。等待终止,它不会停止进程,它所做的只是导致进程在流上迭代时产生错误(请参见下面的错误) 实现我所要做的事情的最佳方式是什么 这是Pyth
-
在pyspark中编写拼花时放下分区列
我有一个带有日期列的数据框架。我已将其解析为年、月、日列。我想对这些列进行分区,但我不希望这些列保留在拼花文件中。 下面是我对数据进行分区和写入的方法: 这将正确创建拼花文件,包括嵌套的文件夹结构。但是,我不希望在拼花文件中包含年、月或日列。
-
我可以在Java MessageFormat中转义花括号吗?
问题内容: 我想在Java MessageFormat中输出一些花括号。例如,我知道以下内容不起作用: 有没有一种方法可以逃避“ return {2}”周围的花括号? 问题答案: 您可以将它们放在单引号内,例如 有关更多详细信息,请参见此处。
-
Kafka-从JSON记录到S3中的拼花文件
如果我错了,请纠正我。。拼花文件是自描述的,这意味着它包含正确的模式。 我想使用S3接收器融合连接器(特别是因为它正确处理了S3的精确一次语义)从我们的Kafka中读取JSON记录,然后在s3中创建拼花文件(按事件时间分区)。我们的JSON记录没有嵌入模式。 我知道它还不被支持,但我对拼花地板和AVRO也有一些问题。 由于我们的JSON记录中没有嵌入模式,这意味着连接器任务必须从它自己的JSON字
-
奴隶丢失,加入火花的速度很慢
-
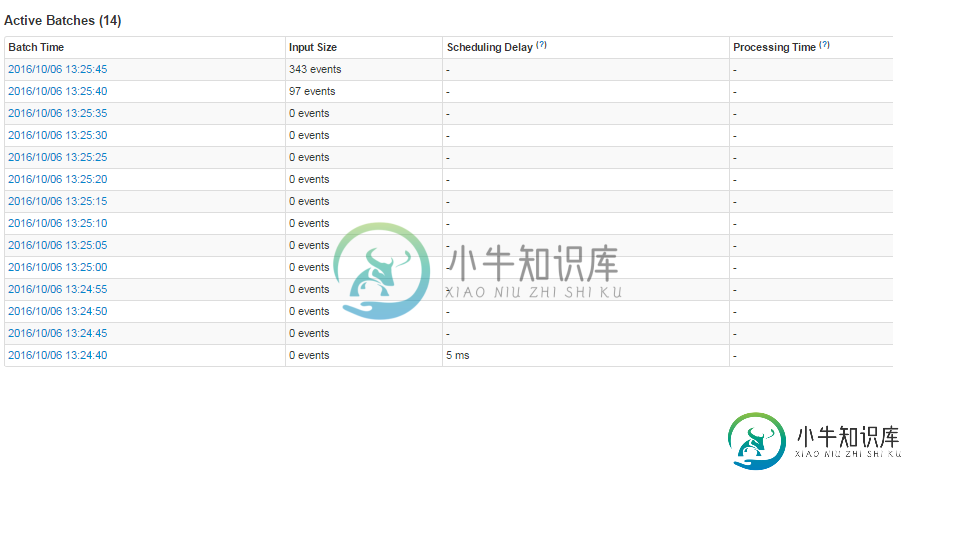 火花流与Kafka-从检查点重新启动
火花流与Kafka-从检查点重新启动我们正在构建一个使用Spark Streaming和Kafka的容错系统,并且正在测试Spark Streaming的检查点,以便在Spark作业因任何原因崩溃时可以重新启动它。下面是我们的spark过程的样子: Spark Streaming每5秒运行一次(幻灯片间隔),从Kafka读取数据 Kafka每秒大约接收80条消息 我们想要实现的是一个设置,在这个设置中,我们可以关闭spark流作业(
-
MongoDB查询检索数据花费太多时间
我收集了300万份文件,索引如下: {ts:1},{u\u id:1} 请注意,这是两个单独的升序索引,而不是复合索引。 当我运行此查询时: db.collection.find({u_id:'user'})。排序({ts:-1})。跳过(0)。限制(1) 需要100毫秒。我有以下日志: 2017-04-15T06:42:01.147 0000 I命令[conn783]查询。集合查询:{order
-
错误火花流中重载的方法值createDirectStream
在调用参数化版本的CreateStream时,我也会遇到类似的错误。 你知道有什么问题吗?
-
Vertx客户端正在花时间检查故障
我有一个要求,我通过Vertx客户端将一个微服务连接到其他微服务。在代码中,我正在检查另一个微服务是否关闭,然后在失败时它应该创建一些JsonObject,其中solrError为键,失败消息为值。如果有solr错误,我的意思是如果其他微服务关闭,通过负载平衡调用solr,那么它应该会抛出一些错误响应。但是Vertx客户端需要一些时间来检查失败,当条件被检查时,jsonject中没有solrErr
-
在火花scalaGroupByKey($"coll")和GroupBy($"coll")之间的区别
当我使用DF的列名作为参数时,与使用和有什么根本区别? 哪一个是省时的,每一个的确切含义是什么?当我通过一些例子时,请有人详细解释一下,但这是令人困惑的。
-
火花2。x数据帧或数据集?[副本]
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
并行化步骤中的火花内存错误
我们正在使用最新的Spark构建。我们有一个非常大的元组列表(8亿)作为输入。我们使用具有主节点和多个工作节点的docker容器运行Pyspark程序。驱动程序用于运行程序并连接到主机。 运行程序时,在sc.parallelize(tuplelist)行,程序要么退出并显示java堆错误消息,要么完全退出而不出错。我们不使用任何Hadoop HDFS层,也不使用纱线。 到目前为止,我们已经考虑了这
-
火花-如何从时间戳中提取小时?
请帮助理解为什么不提取为8:15am? W3C日期和时间格式 示例1994-11-05T08:15:30-05:00对应于美国东部标准时间1994年11月5日上午8:15:30。 用于格式化和解析的日期时间模式
-
在火花scala中使用结构创建模式
我是scala新手,尝试从元素数组中创建自定义模式,以读取基于新自定义模式的文件。 我正在从json文件中读取数组,并使用爆炸方法为列数组中的每个元素创建了一个数据框。 获得的输出为: 现在,对于上面列出的所有值,我尝试使用下面的代码动态创建val模式 上面的问题是,我能够在struct中获取数据类型,但我也希望仅为数据类型decimal获取(scale和preicion),其限制条件为max a