《创作激励计划》专题
-
PHP面向对象程序设计(OOP)之方法重写(override)操作示例
本文向大家介绍PHP面向对象程序设计(OOP)之方法重写(override)操作示例,包括了PHP面向对象程序设计(OOP)之方法重写(override)操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP面向对象程序设计(OOP)之方法重写(override)操作。分享给大家供大家参考,具体如下: 因为PHP是弱类型的语言, 所以在方法的参数中本身就可以接收不同类型的数据,又因
-
如何制作主屏幕。java运行由scene builder设计的应用程序?
我试图通过使用场景生成器来构建一个简单的场景。但是我没有main.java文件来运行代码!我不明白怎么了! 这是我的FXMLDocumentController。java文件: 这里是fxml文件:sample。fxml 而且是主要的。JAVA 当我运行此代码时,它显示错误和未能构建:异常在应用程序启动方法
-
我如何使命令java版本的工作在我的计算机与Windows8.1?
问题 我在我的计算机上安装了Java9和Windows8.1,按照Internet上的说明配置系统变量,和命令在命令提示符下工作。 然后我不得不改为Java10,所以我安装了系统变量,更改了系统变量,但是现在只有工作,当我尝试使用时,会出现错误。 我需要Java工作,这样我就可以跟随一些在线课程,我不想被卡住,因为我的安装有问题。 有关Java安装的信息 我使用了从Oracle网站上获得的JDK-
-
如何访问从外部Flink作业计算的状态?(不知道其id)
我是Flink的新手,目前正在测试用例框架,该用例包含丰富来自Kafka的事务,并具有许多历史特征(例如,相同源和相同目标之间过去的事务数),然后使用机器学习模型对该事务进行评分。 目前,功能都保留在Flink状态中,同一个工作是对丰富的事务进行评分。但是我想将特征计算工作与评分工作分开,我不知道如何做到这一点。 > 我曾想过直接查询RocksDB,但也许有更简单的方法? 对Flink来说,将这项
-
使用Windows DOM和TXMLDocument验证XML:在某些计算机上不起作用
我有一些Delphi代码来读取和验证基于XSD文档的XML文件。我正在使用Windows DOM(TMXLDocument)。本文解释了底层逻辑。 它在某些计算机上工作(例如,对有问题的标记抛出异常)。但在较新的计算机上,它不会引发任何异常。 Windows中是否有需要更改才能使其正常工作的设置?或者有人知道用于验证XML的本机Delphi组件吗? XSD文件:http://www.nemsis.
-
如何从Oozie触发的流图减少作业输出Hadoop EL计数器?
我正在使用Oozie触发一个流式MapReduce作业,我想为此收集以下Hadoop EL常量: map_in:Hadoop映射器输入记录计数器名称。 map_out:Hadoop映射器输出记录计数器名称。 reduce_in:Hadoop reducer输入记录计数器名称。 reduce_out:Hadoop reducer输入记录计数器名称。 我看到这些可以使用 ${hadoop:counte
-
如何在JMeter Webdriver采样器中计算两种不同操作的时间
我想在JMeter webdriver采样器中记录两个不同动作的时间。我面临的问题是,这是记录相同的时间为两个。这是我的代码。 wds.log.info(“设备的基线提交开始时间”+“${DeviceName}”+“:-”+wds.SampleResult.GetStartTime()) wds.log.info(“设备的基线提交结束时间”+“${DeviceName}”+“:-”+wds.Sam
-
操作系统 - 计算机常见的高进制为什么是 8 、16 呢?
为什么没有 3 4 5 6 32 64 进制呢? 或者说为什么选用 8 和 16 这两个特殊的数字呢?
-
借助这些提示和技巧在 Adobe XD 中更快地设计和创建原型。
借助这些提示和技巧在 Adobe XD 中更快地设计和创建原型。 下列技巧可以在您使用 Adobe XD 的过程中为您提供帮助。 一般提示和技巧 在设计时,应考虑使用“重复网格”工具(在属性检查器中),而不是复制粘贴项目组。 要复制一个形状,可以采用以下办法:选择该形状,按住 Option 键(在 Mac 上)或 Alt 键(在 Windows 上)拖出它的一个新副本。 在 Mac 上,可以使用“
-
计算每个数据帧行中的发生次数,然后创建最频繁的列
我试图比较一个数据帧(500000x3)行中的三个浮点值,我希望这三个值是相同的,或者至少是其中的两个。我想在假设它们并非完全不同的情况下选择出现最多的值。我目前尝试的玩具示例如下所示: 然后我考虑循环计数,并为每个计数选择最高值,但这非常缓慢,而且感觉不舒服。我也试过: 为了保持计算结果为真的行,并对那些不为真的行做一些处理,但我在真实的行中有1000个NaN值,显然是。有什么建议吗?
-
Java:创建一个简单的泛型方法,在应用过滤器后进行计数
-
Rest API设计:如何为具有多个子资源的发布资源创建restful API?
我们是一个电子商务网站,希望创建API给我们的客户提供一个接口,通过这个API发送产品相关信息。我们目前需要3种类型的产品信息: 基本细节:如价格、颜色等 映像:产品映像 评论:该产品的评论 方法1:允许客户端通过单个API发送所有信息。 方法2:为所有子资源创建不同的API。 方法3:使用层次URI为所有子资源创建不同的API。
-
Azure Database ricks:为谁在什么时刻运行了什么查询创建审计跟踪
我们有一个审计需求,可以洞察Azure Databricks中谁在什么时候执行了什么查询。Azure Databricks / Spark UI / Jobs选项卡已经列出了执行的Spark作业,包括完成的查询和提交的时间。但是它不包括谁执行了查询。 是否有我们可以与Azure Databricks一起使用的API来查询UI中显示的这些Spark作业详细信息?(Databricks REST AP
-
在Java中使用mutator和accessor方法并创建对象计算数字的平均值
我的任务是创建一个类来对一系列数字进行计数、求和和平均。AverageCalculator类的规格如下: null 这是我的主要方法: 但是,当我尝试创建新对象(AverageCalculator average=new AverageCalculator(90);)时,有一个错误,说它是未定义的。如何创建此对象并成功传递其值?
-
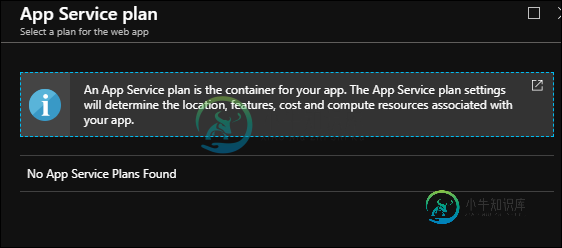 尝试更改Azure应用服务计划时找不到应用服务计划
尝试更改Azure应用服务计划时找不到应用服务计划我正在尝试更改其中一个Azure应用服务的Azure应用服务计划,以下是我得到的。它无法搜索我刚刚创建的应用服务计划。 Azure应用服务的当前应用服务计划和我想要更改为存在于同一位置和同一资源组中的计划。这两个计划的唯一区别是定价层。现有计划恰好在“标准:2小”中,我刚刚创建的计划在“标准:1小”中。对于这两个计划,我都选择定价层为“标准1”,因此不确定这是如何在定价层名称中添加数字1和2的。