《创作激励计划》专题
-
创建的异常:java。lang.IllegalStateException:无法转发。已作出答复
有人能帮我解决这个问题吗。。。? 这是我的代码行。我正在使用struts 1。x和我在一个JSP中包含了两个JSP。我的代码如下。我已经对它进行了调试,服务器端处理了对“LeftMenu.do”的请求,并成功地返回了,然后出现了下面提到的错误。。。需要你的宝贵反馈。
-
在talend大数据工作岗位上创造历史序列
我有一个在塔伦德创建序列的要求。基本上,记录来自源文件。对于每个源行,我希望创建一个唯一的数字。这就是事情变得复杂的地方。当第二天出现新文件时,talend应该选择最后生成的数字,然后用1递增它。对于EX:今天,最后生成的序列号是100。明天talend应该从100生成序列号。即101,102,103,104....这意味着talend应该保留以前生成的最后一个序列号的历史记录。 谢谢
-
雪花创建或替换表作为无法识别的值
为什么我会得到这个错误消息,尤其是在中唯一的列是varchar数据类型的情况下?
-
第28篇 XML(二)使用DOM创建和操作XML文档
导语 在上一节中我们用手写的方法建立了一个XML文档,并且用DOM的方法对其进行了读取。现在我们使用代码来创建那个XML文档,并且对它实现查找、更新、插入等操作。 环境:Windows Xp + Qt 4.8.4+QtCreator 2.6.2 目录 一、创建文档 二、读取文档 三、添加节点 四、查找、删除、更新操作 正文 一、创建文档 1.新建Qt Gui应用,项目名称为myDom_2,基类为Q
-
流状态计算:累计总和
问题内容: 假设我有一个Java IntStream,是否可以将其转换为具有累积总和的IntStream?例如,以[4、2、6,…]开头的流应转换为[4、6、12,…]。 更笼统地说,应该如何实施有状态流操作?感觉这应该可行: 有一个明显的限制,即它仅适用于顺序流。但是,Stream.map明确需要无状态映射函数。我是否错过了Stream.statefulMap或Stream.cumulative
-
在MySQL中计算运行总计
问题内容: 我有这个MySQL查询: 返回如下内容: 我真正想要的是末尾的另一列显示运行总计: 这可能吗? 问题答案: 也许这对您来说是一个更简单的解决方案,并且可以防止数据库不得不执行大量查询。这仅执行一个查询,然后在一次通过中对结果进行一点数学运算。 这将为您提供一个额外的RT(运行总计)列。不要错过顶部的SET语句来首先初始化运行的total变量,否则您将只获得一列NULL值。
-
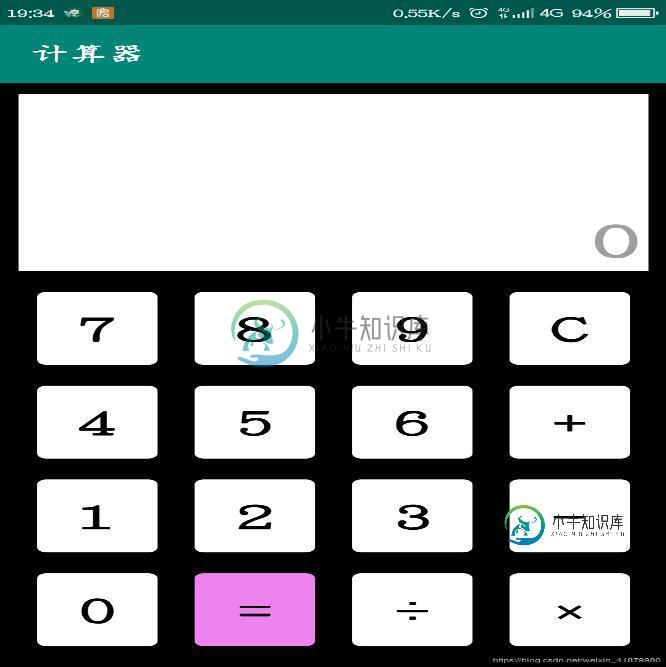 Android studio设计简易计算器
Android studio设计简易计算器本文向大家介绍Android studio设计简易计算器,包括了Android studio设计简易计算器的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Android studio设计简易计算器的具体代码,供大家参考,具体内容如下 效果显示: 第一步,简单的界面布局 string.xml文件 采用的是LinearLayout线性布局,而因为按钮的基本属性相同,所以采用使用样式的方式
-
每天计算/统计mysql结果
问题内容: 可以说我有一个名为’ ‘的mysql表,具有以下值: 我想生成一份报告,说明每天有多少只动物报名(我不在乎一天中的时间)。因此,我从上面的示例表中寻找的最终结果是: 有没有一种方法可以在mysql中执行此操作,或者我需要使用另一种语言(如PHP)来计算总数吗? 任何想法表示赞赏,谢谢 问题答案: 会给您您所追求的。
-
计算MySQL中的运行总计
问题内容: 我有这个MySQL查询: 返回如下内容: 我真正想要的是末尾的另一列以显示运行总计: 这可能吗? 问题答案: 也许对您来说是一个更简单的解决方案,并且可以防止数据库不得不执行大量查询。这仅执行一个查询,然后在一次通过中对结果进行一些数学运算。 这将为您提供一个额外的RT(运行总计)列。不要错过顶部的SET语句来首先初始化运行中的total变量,否则您将只获得一列NULL值。
-
SQL查询按月计算计数
问题内容: 在SQL中按月将一列中的1-12连接到一堆计数的好方法是什么?…在SQL中 最终会像 编辑-基本上是一种获取我的月份列表/表格/任何内容的巧妙方法 问题答案: 许多方法…在上一份工作中对许多应用程序来说对我来说效果很好的一种方法是建立时间表。 然后,您可以将其日期字段放在startstamp和endstamp之间的timeframes表中进行联接。 这样可以很容易地拉出某个时间段或
-
查询计算与编程计算
我正在使用Hibernate作为ORM进行Java EE项目,我已经到了一个阶段,我必须在我的类上执行一些数学计算,比如和、计数、加法和除法。 我有两个解决方案: 选择我的类并在代码中以编程方式应用这些操作 对命名查询进行计算
-
AnyLogic:如何计算累计总和?
我想知道如何计算的累计总和在AnyLogic中。具体地说,我有一个循环事件,每周改变一个参数的值。从这个参数我想计算它收到的值的累计总和,我怎么做呢? 该事件是循环模式的超时。操作是: "name_parameter"=圆形(max(正常(10,200),0));
-
带范围计数的Agg计数
我医生看起来像 我想拥有超过 100个文档在50到100个之间少于100个文档我尝试使用不同的聚合,但我不知道如何在另一个聚合的计数上进行范围聚合 谢谢你的帮助,
-
并行计算列的统计量
在Spark dataframe列中获取最大值的最佳方法 这篇文章展示了如何在表上运行聚合(distinct、min、max),如下所示: null
-
开发设计规范 - Key设计
key的一个格式约定:object-type:id:field。用”:”分隔域,用”.”作为单词间的连接,如”comment:12345:reply.to“。不推荐含义不清的key和特别长的key。 一般的设计方法如下: 1: 把表名转换为key前缀 如, tag: 2: 第2段放置用于区分区key的字段—对应mysql中的主键的列名,如userid 3: 第3段放置主键值,如2,3,4…., a