《拼多多》专题
-
Kafka Conenct HDFS接收器以拼花格式保存数据
使用Kafka Connect HDFS Sink,我能够将avro数据写入Kafka主题并将数据保存在hive/hdfs中。 我正在尝试使用格式类以拼花文件格式保存数据 快速启动hdfs。属性如下 当我将数据发布到Kafka时,表在hive中创建,test\u hdfs\u parquet目录在hdfs中创建,但由于以下异常,Sink无法以parquet格式保存数据
-
如何在拼花架构定义中指定列描述
我正在使用层叠将文本分隔转换为拼花地板 下面是拼花图案: 以下是avro模式: 如何跟踪parquet中avro文件中的“doc”部分?
-
 雪花在拼花地板上不是按柱分割的
雪花在拼花地板上不是按柱分割的关于雪花的新功能--推断模式表函数,我有一个问题。INFER模式函数在parquet文件上执行得很好,并返回正确的数据类型。但是,当parquet文件被分区并存储在S3中时,INFER模式的功能与pyspark Dataframes不同。 在DataFrames中,分区文件夹名称和值作为最后一列读取;在雪花推断模式中有没有一种方法可以达到同样的结果? 示例: 示例:{“AGMT_GID”:1714
-
尝试运行Figma拼写检查器扩展时出错
我已经按照自述文件中概述的说明进行了操作,但是我无法运行Figma的拼写检查扩展。 运行没有问题。然而,当试图运行时,我在控制台收到以下输出:控制台错误。
-
Solr:拼写检查不能与select查询一起工作
http://localhost:8983/solr/prashant1/spell?q=blakc&spellcheck=on&wt=json 结果 但我需要与select查询相同的结果,它不能从SOLR管理中工作。 有没有设置和步骤要做?
-
Spark是否在读取时维护拼花地板分区?
我很难找到这个问题的答案。假设我为拼花地板编写了一个数据框,并且我使用与相结合来获得一个分区良好的拼花地板文件。请参阅下面: 现在,稍后我想读取拼花文件,所以我这样做: 数据帧是否由分区?换句话说,如果拼花地板文件被分区,火花在将其读入火花数据帧时是否会维护该分区。还是随机分区? 同样,这个答案的“为什么”和“为什么不”也会有所帮助。
-
如何理解拼花文件名称的每个部分
案例: 我在代码中找不到镶木地板文件的一些规则。有人可以解释吗? 代码: https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatWriter.scala https://github.com/apache/spa
-
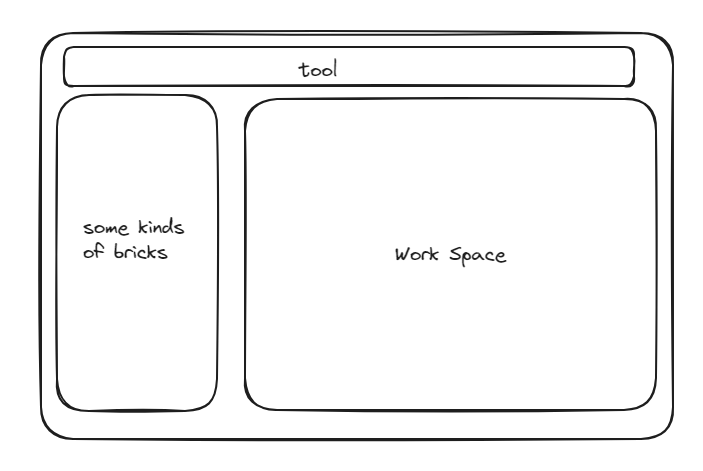 如何开发一款前端的积木拼装软件?
如何开发一款前端的积木拼装软件?如何制作一款积木拼装的软件? 或者说有没有现成的这样一款软件。 左侧积木箱,包括各种积木零件 右侧为工作区 拖拽左侧的积木箱中的零件到工作区进行拼装,零件与零件之间根据种类的不同有不同的拼装方式。 当两个零件靠近的时候,会提示不同的拼装方式,选择其中一个之后,组件按照对应的方式进行拼装。 这里“零件”说的就是一个基础零件吗(从工具箱中拿出来的,而不是一个多个零件组成成的一个新零件)。其实这里的“零
-
使用多对多关系的透视表创建一对多关系
用户表结构:用户 id、名称、用户名、密码、创建时间、更新时间 文章表结构:文章 id、标题、内容、创建时间、更新时间 关系表:文章\用户 id、文章id、用户id处于活动状态、创建时间、更新时间 标签 id、名称、用户id、创建时间、更新时间 透视表项目用户与标记的关系。表:文章\用户\标签 标签号,物品号,用户号 我想连接这些表,以便可以像这样或类似的格式访问 并且应该能够创建/更新smth,
-
一个活动--多个碎片还是多个活动--多个碎片?
我读过很多关于这方面的文章,但也有2012年或更早的文章。 (我只是打算从数据库中读取和插入一些数据。)
-
多维数组中的值求和(选择具有多行的多列)
假设我有5个不同的列,< code>a、b、c、d、e,我选择了多行: 例子: 用户有 3 个帖子,因此它将在查询中选择 3 行。 我想对< code>a的所有行的值求和(当然还有其余的)。 例如 值 = 4 值=10 < code >第3行 值= 1 所以我需要把所有这些加起来得到15。 我知道使用< code>array_sum($ratings)来查找数组的总和,但前提是您选择了一个可以有多
-
1.5.11 关系(1对1,1对多,多对多)在mongoose里如何实现
最好的办法还是写一个真实的项目,从博客项目开始。 了解关系(1对1,1对多)在mongoose里如何实现 UserSchema = new Schema({ ... contacts:[] }); 了解关系(1对1,1对多,多对多)在mongoose里如何实现 ContactSchema = new Schema({ ... owner: { type
-
参数多态性与Ad-hoc多态性
问题内容: 我想了解参数多态性(例如Java / Scala / C ++语言中的通用类/函数的多态性)与Haskell类型系统中的“即席”多态性之间的主要区别。我熟悉第一种语言,但是我从未与Haskell合作。 更确切地说: 例如Java中的类型推断算法与Haskell中的类型推断有何不同? 请给我举一个例子,这种情况可以用Java / Scala编写但不能用Haskell编写(根据这些平台的模
-
与Ruby,Redis和Ohm的多对多关系
问题内容: 我正在尝试使用Ohm在Redis中创建多对多关系。例如,我有如下定义的Book和Author模型: 我想做的是利用Ohm的索引功能来进行以下发现: 使用上面的代码,我得到以下异常:Ohm :: Model :: IndexNotFound:找不到索引:author_id。(尝试查找提供给作者的图书时) 我已尝试按照此处所述构建自定义索引:http : //ohm.keyvalue.or
-
MySQL:很多表还是很多数据库?
问题内容: 对于一个项目,我们有一堆始终具有相同结构且未链接在一起的数据。有两种保存数据的方法: 为每个池创建一个新的数据库(约15-25个表) 在一个数据库中创建所有表,并根据表名称更改池。 对于MySQL来说,哪一个更容易和更快地处理? 编辑: 我对数据库设计没有兴趣,只是对两种可能性中的哪一种更快感到兴趣。 编辑2: 我将尝试使其更加清晰。如前所述,我们将获得数据,其中一些日期很少会属于不同