《文件系统》专题
-
C语言实现学生信息管理系统(多文件)
本文向大家介绍C语言实现学生信息管理系统(多文件),包括了C语言实现学生信息管理系统(多文件)的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了C语言实现学生信息管理系统的具体代码,供大家参考,具体内容如下 elemtype.h elemtype.cpp main.cpp 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
可以在任何操作系统上运行JAR文件吗?
问题内容: 是否可以在任何操作系统(例如Windows,Linux,Mac OS X)上执行JAR文件?我想构建一个要在Linux,Windows和Mac OS X上运行的简单应用程序。JAR文件可以在安装了Java的任何操作系统上运行吗? 问题答案: Jar文件可在存在JVM的任何OS上运行。
-
无法保存到S3,错误为“java.io.ioException:scheme:s3a没有文件系统”
我试图将一些测试数据从我的本地笔记本电脑上用Java保存到S3上,得到以下错误: 下面是我的代码 我搜索了一下,但没有得到答案。有什么想法吗?提前道谢。 更新: null
-
我如何检查失败的'Docker构建‘的文件系统?
我试图为我们的开发过程构建一个新的Docker映像,使用安装一堆Perl模块,作为各种项目的基础映像。 在开发Dockerfile时,返回一个失败代码,因为某些模块安装不干净。 我很确定我需要获得来安装更多的东西。
-
正确的文件。在Jenkins系统和Jenkins构建中编码
我在Jenkins上设置编码属性时遇到了问题。 在master的test Jenkins“System Info”页面上显示和。相同的值显示在从服务器的“系统信息”页面上。slave配置中的字段不包括,但正如我所写的,系统信息中的编码是可以的。当我使用withMaven方法在从服务器上运行流水线脚本时,日志中有。 所有服务器,包括主服务器和从服务器,测试和生产,都是CentOS 8。在这两个环境中
-
用Java模拟SFTP、FTP、FTPS、本地文件系统服务器
我需要在Java中测试FTP/FTPS/SFTP/本地文件系统协议。 谢谢, 维贾伊·布尔雷
-
从Mac系统上的控制台导航到jdk文件夹
我不熟悉Mac系统。我想在Mac终端上使用命令导航到java jdk目录。类似于windows命令行上的。 我尝试了来获得路径,但要找到路径是一个挑战 $(/usr/libexec/java_home) /Library/Java/JavaVirtualMachines/jdk-12.0.1。jdk/目录/家庭系统名称:$
-
使用Heroku临时文件系统作为Ehcache磁盘存储
正如 Heroku Dyno 临时文件系统文档所解释的那样,当 dyno 停止或重新启动时,文件系统将被丢弃。这意味着它不能用作永久(磁盘)存储。 我的用例是我想使用Ehcache缓存一些参考数据。我在考虑使用一些(有限的)堆内存以获得最佳性能,如果它不足以回退到磁盘存储。使用Ehcache,这可以在每个缓存的基础上进行很好的配置,例如在堆内存中存储最多1000个条目,例如在磁盘上存储25MB。
-
"系统找不到文件C:\编程数据\Oracle\Java\javapath\java.exe"
我使用的是Windows 8的JDK 8u25,我的Java安装遇到了问题。我可以很好地运行< code>javac,但是运行< code>java会产生以下错误消息: 我如何解决这个问题? 我认为问题与我的环境变量有关。 我设置的重要变量是: < Li > < code > JAVA _ HOME –< code > C:\ Program Files \ JAVA \ JDK 1 . 8 .
-
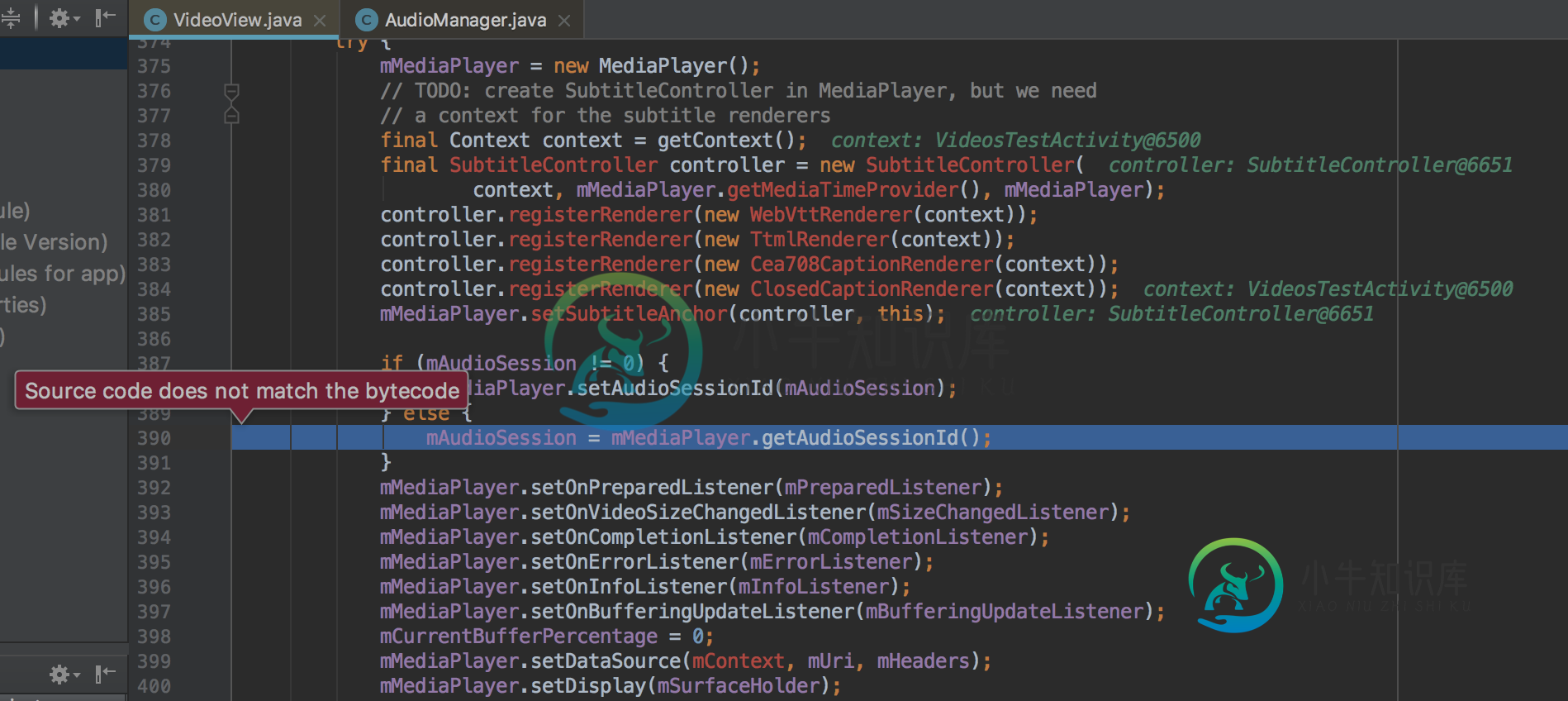 华为系统文件“源代码与字节码不匹配”
华为系统文件“源代码与字节码不匹配”我们正在调试我们的一个应用程序的问题,该问题只影响华为设备。为了调试它,我们购买了P20 Lite Ane-LX1。我们在代码中放置了一些断点,并正在调查整个堆栈跟踪。该设备安装了Android8.0,我们在Android Studio下载了相同的SDK。 当我们将设备附加到调试器并试图调查堆栈跟踪时,系统源文件中会出现以下错误: 在使用堆栈跟踪之后,我们可以确认源文件确实与设备上安装的文件不一致
-
Spring mvc属性-java.io.FileNotFoundExc0019:config.properties(系统找不到指定的文件)
我已经创建了一个属性文件,并试图在我的SpringDAO类文件中访问它,但是得到了“java.io.FileNotFoundException:config.properties(系统找不到指定的文件)”。我尝试了不同的方案将文件放在不同的文件夹/位置,但遇到了相同的问题。谁能帮我一下吗。以下是代码和结构细节, 在道课上,, 我试图把config.properties文件放在src/main/Re
-
非HDFS文件系统上的Hadoop/Yarn和任务并行化
我实例化了一个Hadoop2.4.1集群,并且发现运行的MapReduce应用程序的并行化程度将不同,这取决于输入数据所在的文件系统类型。 使用HDFS,MapReduce作业将生成足够的容器,以最大限度地利用所有可用内存。例如,一个具有172GB内存的3节点集群,每个map任务分配2GB,将创建大约86个应用程序容器。 在不是HDFS的文件系统上(比如NFS或在我的用例中是并行文件系统),Map
-
如何在nfs文件系统中存储apache flink检查点
我正在使用Apache Flink 1.10.0从RabbitMQ拉数据流,现在我在内存中使用默认检查点配置。现在为了在任务管理器重启时恢复,我需要在文件系统中存储状态和检查点,所有演示都应该使用“hdfs://namenode: 4000/......”,但是现在我没有HDFS集群,我的Apache Flink在kubernetes中运行集群,如何将我的检查点存储在文件系统中? 我阅读了Apac
-
6.2 path/filepath — 兼容操作系统的文件路径操作
path/filepath 包涉及到路径操作时,路径分隔符使用 os.PathSeparator。不同系统,路径表示方式有所不同,比如 Unix 和 Windows 差别很大。本包能够处理所有的文件路径,不管是什么系统。 注意,路径操作函数并不会校验路径是否真实存在。 解析路径名字符串 Dir() 和 Base() 函数将一个路径名字符串分解成目录和文件名两部分。(注意一般情况,这些函数与 Uni
-
使用系统默认应用程序管理文件或 URL
shell模块提供与 桌面集成 相关的功能,如点击url时调用默认浏览器 进程: 主进程, 渲染进程 使用默认浏览器打开链接: 1 const {shell} = require('electron') 2 shell.openExternal('https://github.com') Copied! 方法 shell.showItemInFolder(fullPath) 用途:判断是否在文件