《thrift》专题
-
Apache Thrift服务自动发现
我想使用apache thrift开发一些本地网络服务。应该有多个服务等待一个主机连接到它们,并独占使用它们,直到主机释放它们。这些服务是用多种语言编写的。 之所以选择使用thrift,是因为我需要一些简单的远程过程调用机制,用于快速且支持多种语言的服务之间的通信。虽然thrift适合RPC,但我需要一些机制来通过一些自动发现机制定位服务TCP地址和端口,然后才能在不硬连接地址的情况下将thrif
-
使用Thrift发送二进制数据的最佳方式
我在c中有一个存储字节的结构,如下所示: 我需要通过节俭将这些数据发送到用C编写的远程服务。我发现了三种方法如何将此结构映射到节俭idl: > 使用二进制键入: 以类型存储数据: 最好的办法是什么?
-
ProtocolBuffers/Thrift是否适用于数据中心之间的通信和消息传递?
目前,我们在多个地理区域拥有数据中心,每个数据中心托管着需要相互通信的不同应用程序和服务。目前,我们正在使用http进行通信,出于性能原因,希望探索其他协议。可以使用ProtocolBuffers或Thrift通过tcp/ip在地理区域之间进行通信吗?如果是这样的话,延迟是否会扼杀协议缓冲区或节俭提供的任何性能提升?是否有其他合适的选择?
-
 python3.7通过thrift操作hbase的示例代码
python3.7通过thrift操作hbase的示例代码本文向大家介绍python3.7通过thrift操作hbase的示例代码,包括了python3.7通过thrift操作hbase的示例代码的使用技巧和注意事项,需要的朋友参考一下 HBase是一个分布式的、面向列的开源数据库,其是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。其数
-
解决Mac安装thrift因bison报错的问题
本文向大家介绍解决Mac安装thrift因bison报错的问题,包括了解决Mac安装thrift因bison报错的问题的使用技巧和注意事项,需要的朋友参考一下 安装thrift时,报错: Bison version 2.5 or higher must be installed on the system! 使用brew install bison 安装新版的bison 已经安装3.0.4版本 但
-
从spark thrift service创建/访问带有s3位置的配置单元外部表时发出问题
我已经使用hadoop-credential API在一个jceks文件中配置了s3密钥(访问密钥和秘密密钥)。用于相同的命令如下: hadoop凭据创建fs.s3a.access.key-provider jceks:/hdfs@nn_hostname/tmp/s3creds_test.jceks 现在,当我试图创建一个位于s3中的外部表时,它失败了,但有以下例外: 如果不存在test_tabl
-
 Spark 2.2查询配置单元表时dataframe NumberFormatException上的Thrift服务器错误
Spark 2.2查询配置单元表时dataframe NumberFormatException上的Thrift服务器错误我有运行Spark2(V2.2)的Hortonworks HDP 2.6.3。我的测试用例非常简单: > 使用一些随机值创建配置单元表。端口10000上的配置单元 在10016打开Spark Thrift服务器 null 我有一个错误: 我怀疑它与列有关,所以我更改为:df.select(“desc”).show() 然后我得到了这个奇怪的结果: 由于某种原因,它返回了列名?! 案例2 直线: 显
-
禁用Cassandra 3中的thrift。x个
在《卡桑德拉3》中是否可以禁用节俭。x? 查看了Cassandra的nodetool disablethrift和start\u rpc设置。然而,yaml是否可以停止从Cassandra库运送libthrift jar? 如果移除jar,则无法启动Cassandra,因为存在NoClassDefFoundError异常。 错误[主]CassandraDaemon。java:749-启动java时
-
无法启动spark thriftserver(spark的hive-site.xml未覆盖默认值)
背景: Centos7 Hadoop-2.7.3 spark-2.0.1-bin-hadoop2.7 apache-hive-2.1.0-bin(仅用于启动由配置单元启动的转移服务--service转移服务) 配置了HADOOP_HOME、SPARK_HOME和HIVE_HOME等 MySQL 5.7.16 已将mysql-connector-java-5.1.40-bin.jar放入hive/l
-
Apache Thrift中的对称加密(AES)
我有两个应用程序使用Thrift进行交互。他们共享相同的密钥,我需要加密他们的消息。使用对称算法(例如AES)是有意义的,但我还没有找到任何库来实现这一点。因此,我做了一项研究,并看到以下选项: 我可以使用内置的SSL支持,建立安全连接,并使用我的密钥作为身份验证令牌。它需要安装证书除了他们已经有的秘密密钥,但我不需要实现任何东西,除了检查从客户端接收的秘密密钥与本地存储的秘密密钥相同。 到目前为
-
Android上的Thrift客户端
我是android开发新手,希望创建一个应用程序,其中包含一个thrift客户端,该客户端正在我的网络上使用thrift服务器。我已经得到了thrift定义文件和thrift编译器生成的java代码。 > 我可以直接使用类似于此的自动生成函数吗 对我的服务进行异步调用以便我遵循android最佳实践?或者使用这个功能会以任何方式阻止我的应用程序,或者在android上还有其他方式比这个更好吗? 我
-
如何在Thrift服务器上查看pyspark临时表?
-
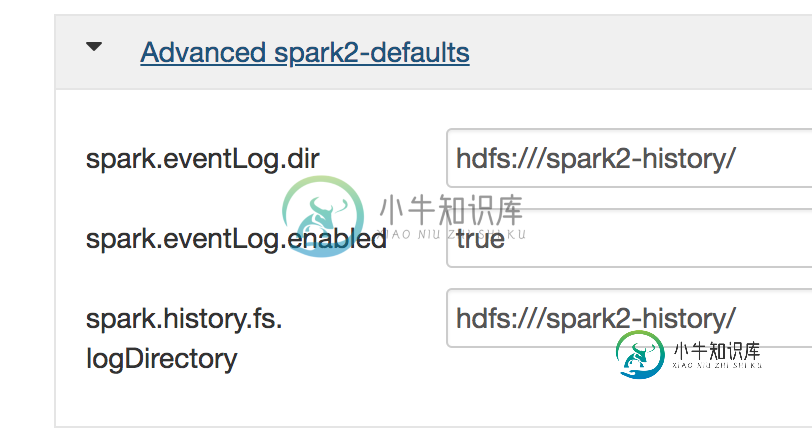 对Spark Thrift服务器的直线查询在Spark History UI中没有显示任何内容
对Spark Thrift服务器的直线查询在Spark History UI中没有显示任何内容我刚刚在端口10016(默认)上用Hive和Spark Thrift服务器构建了一个Hortonworks集群,并通过beeline to STS测试了SELECT语句 https://spark.apache.org/docs/1.6.0/sql-programming-guide.html#running-the-theft-jdbcodbc-server 我可以得到结果,一切都很好。但我的问
-
无法使用JDBC连接到Spark thriftserver
我将DataGrip配置为使用spark安装文件夹中的JDBC库。
-
Spark(2.2):使用结构化流反序列化来自Kafka的Thrift记录
我是火花的新手。我使用结构化流从Kafka读取数据。 我可以在Scala中使用此代码读取数据: 我在值列中的数据是Thrift记录。Streaming api以二进制格式提供数据。我看到了将数据转换为string或json的示例,但我找不到任何关于如何将数据反序列化为Thrift的示例。 我如何才能实现这一点?