《独立部署》专题
-
Java独立代码块
问题内容: 我从事Java已有很长时间了,但是从未遇到过这样的事情。我想知道它的作用以及为什么它不是错误。 我想知道单个块的目的是什么,其中包含对“ doSomething()”的调用。它只是一个基本代码。我遇到的实际代码位于http://www.peterfranza.com/2010/07/15/gwt- scrollpanel-for-touch-screens/ 问题答案: 这是一个(非静
-
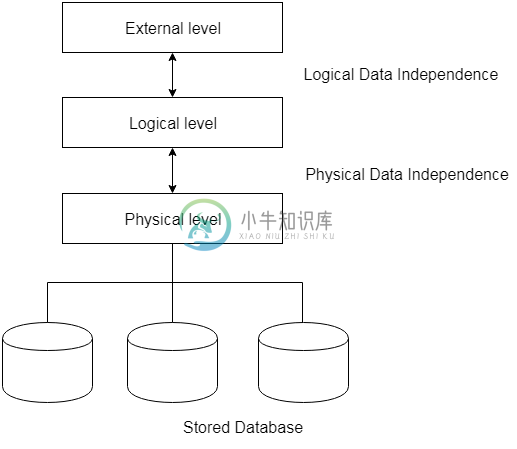 DBMS数据独立性
DBMS数据独立性主要内容:1. 逻辑数据独立性,2. 物理数据独立性可以使用三模式体系结构来解释数据独立性。 数据独立性是指能够在数据库系统的一个级别修改模式而不改变下一个更高级别的模式的特征。 有两种类型的数据独立性: 1. 逻辑数据独立性 逻辑数据独立性是指能够在不必更改外部模式的情况下更改概念模式的特征。 逻辑数据独立性用于将外部级别与概念视图分开。 如果对数据的概念视图进行任何更改,那么数据的用户视图将不会受到影响。 逻辑数据独立性发生在用户界面级别。 2
-
独立Kafka制作人
我正在考虑创建一个独立的Kafka生产者,它作为守护进程运行,通过套接字接收消息,并将其可靠地发送给Kafka。 但是,我决不能是第一个想到这个想法的人。这样做的目的是避免使用PHP或Node编写Kafka生成器,而只是通过套接字将消息从这些语言传递到独立的守护进程,这些语言负责传递,而主应用程序则一直在做自己的事情。 此守护进程应负责在发生中断时进行重试传递,并充当服务器上运行的所有程序的传递点
-
Kafka独立消费者
我是Kafka的新手,我想验证我的设计。下面是我所拥有的。 我有一个生产者发布到一个主题,有一堆容器(部署我的web应用程序的地方),每个容器上都运行着一个消费者。这些消费者不在消费者组中,也不独立地消费消息。每个消费者都应该阅读主题中的所有消息。例如,假设主题m0,m1,m2上有3条消息,那么consumer1到consumerN应该独立地读取m0,m1,m2。每个使用者在处理读取的消息后立即提
-
独立运行Apache Atlas
我正在尝试在Ubuntu上以独立的方式运行Apache地图集 - 这意味着不必设置Solr和/或HBase。我所做的(根据文档:http://atlas.apache.org/0.8.1/InstallationSteps.html)是克隆Git存储库,使用mbadded的HBase和dSolr构建maven项目: 解压缩了 resuting tar.gz 文件并执行了 bin/atlas_sta
-
Single projects(独立项目)
一个项目将会自动生成测试运行。默认位置为:build/reports/androidTests 这非常类似于JUnit的报告所在位置build/reports/tests,其它的报告通常位于build/reports/< plugin >/。 这个路径也可以通过以下方式自定义: android { ... testOptions { reportDir = "$p
-
独立应用程序
现在假设我们想要使用 Spark API 写一个独立的应用程序。我们将通过使用 Scala(用 SBT),Java(用 Maven) 和 Python 写一个简单的应用程序来学习。 我们用 Scala 创建一个非常简单的 Spark 应用程序。如此简单,事实上它的名字叫 SimpleApp.scala: /* SimpleApp.scala */ import org.apache.spark.S
-
M600 的独立使用
即使 M600 与手机断开连接,M600 的部分基本功能仍可继续使用。 在独立模式下,您能: 了解时间、查看日期。 使用 Polar 应用程式进行训练。 如果您的智能手表已经接到Wi-Fi网络,请使用应用程式商店。 使用码表。 使用计时器。 查看您当日的时间表。 设置闹钟。 查看您的步数。 查看您的心率。 更改手表表面。 使用飞行模式。
-
5.15 独立使用ActiveRecord
ActiveRecordPlugin可以独立于java web 环境运行在任何普通的java程序中,使用方式极度简单,相对于web项目只需要手动调用一下其start() 方法即可立即使用。以下是代码示例: public class ActiveRecordTest { public static void main(String[] args) { DruidPlugin dp = n
-
创建独立页面
在本章节中,我们将学习如何为 Docusaurus 创建独立页面(pages)。 这对于创建类似展示页面、练习页面或支持页面等 非经常修改的独立页面 非常有用。 独立页面的功能由 @docusaurus/plugin-content-pages 插件提供。 你可以使用 React 组件或 Markdown 来创建独立页面。 note 独立页面是没有侧边栏的,只有 文档(即 docs 目录下的文件)
-
将war文件部署到weblogic 14.1.1的java独立客户端
早些时候Java独立客户端wlfullclient.jar用于将jar文件部署到weblogic服务器 参考链接:http://middlewaremagic.com/weblogic/?p=483 在将weblogic迁移到14.1.1之后,在类路径中添加了“wls api.jar”或“com.oracle.weblogic.deployment.jar”、“javax.javaee api.j
-
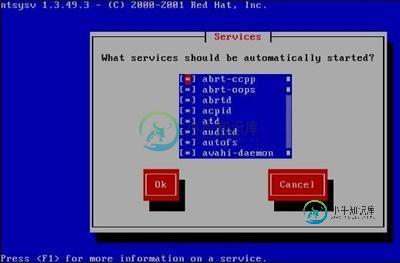 Linux独立服务管理
Linux独立服务管理主要内容:独立服务的启动管理,独立服务的自启动管理我们知道,RPM 包默认安装的服务分为独立的服务和基于 xinetd 的服务,本节来学习独立服务的管理。 独立服务的启动管理 独立的服务要想启动,主要有两种方法。 1) 使用/etc/init.d/目录中的启动脚本来启动独立的服务 既然所有独立服务的启动脚本都存放在 /etc/init.d/ 目录中,那么,调用这些脚本就可以启动独立的服务了。这种启动方式是推荐启动方式,命令格式如下: [root@
-
Apache camel FTP独立程序
你好,我正在尝试编写一个简单的独立java FTP程序,使用Apache Camel从FTP服务器位置下载文件到我的本地机器。当我运行is时,我看到它一直在运行,实际的文件传输并没有发生。可能是什么问题?
-
Spark独立集群调优
应用程序不是那么占用内存,有两个连接和写数据集到目录。同样的代码在spark-shell上运行没有任何失败。 寻找群集调优或任何配置设置,这将减少执行器被杀死。
-
XML声明独立=“是” lxml
问题内容: 我有一个要解析的xml,进行了一些更改并将其保存到新文件中。它有我要保留的声明。当我保存新文件时,我失去了一点。我如何保留它?这是我的代码: 问题答案: 您可以将关键字参数传递给: