《一致性哈希》专题
-
致谢
在我理解STL、建立关于它的培训课程和写这本书的大约两年时间里,我得到了大量帮助。在我所有帮助的来源中,有两个特别重要。 第一个是Mark Rodgers。当我建立它们时,Mark慷慨地自愿检查我的培训材料,而且我从他那里比从其他人那里学到更多关于STL的东西。他也作为本书的技术评论家,再次提供改进了几乎每个条款的观点和见解。 另一个突出的信息源是几个有关C++的Usenet新闻组,特别是comp
-
致谢
致谢 没有Subversion就不可能有(即使有也没什么价值)这本书。所以作者衷心感谢Brian Behlendorf和CollabNet,他们独到的眼光开创了这个充满冒险但雄心勃勃的开源项目;Jim Blandy贡献了Subversion最初的名字和设计—我们爱你,Jim。还有Karl Fogel,一个好朋友和伟大的社区领袖。[1] 感谢O'Reilly和我们的编辑Linda Mui和Tatia
-
致谢
致谢 Rob Pike和Russ Cox,以及很多其他Go团队的核心成员多次仔细阅读了本书的手稿,他们对本书的组织结构和表述用词等给出了很多宝贵的建议。在准备日文版翻译的时候,Yoshiki Shibata更是仔细地审阅了本书的每个部分,及时发现了诸多英文和代码的错误。我们非常感谢本书的每一位审阅者,并感谢对本书给出了重要的建议的Brian Goetz、Corey Kosak、Arnold Rob
-
致谢
《Ruby on Rails 教程》很大程度上归功于我以前写的一本书——RailsSpace,因此以前的合著人 Aurelius Prochazka 也有很大功劳。我要感谢 Aure,他不仅为前一本书做出了贡献,而且也给予了这本书支持。我还要感谢 Debra Williams Cauley,她是 RailsSpace 和这本书的编辑,只要她还带我去玩棒球,我就会继续为她写书。 我要感谢很多 Rub
-
致谢
我要感谢以下人员和组织以这样或那样的方式贡献 Hana: Zach Laine和Matt Calabrese提出了使用函数调用语法做类型计算的原始想法,如BoostCon演示文稿(幻灯片1)(幻灯片2)中所示。 Joel Falcou在我作为Google夏季代码计划的一部分工作期间连续两年指导我,Niall Douglas作为Boost的GSoC管理员,帮助我加入计划,最终让Google获得了令人
-
致谢
本项目由以下贡献者贡献: 文档贡献 贡献者 页面 章节 类型 Bigmoyan keras.io的全部正文 - 翻译 Bigmoyan 深度学习与Keras CNN眼中的世界 翻译 Bigmoyan 深度学习与Keras 花式自动编码器 翻译 Bigmoyan 快速开始 一些基本概念 编写 SCP-173 快速开始 Keras安装和配置指南(Linux) 编写 SCP-173 快速开始 Keras
-
致谢
关于Erlang,已经很难追溯到某个单一起源。许多语言特性都受到了来自计算机科学实验室的朋友及同事的评论的影响并因此而改进,我们在此对他们的帮助和建议表示感谢。我们尤其要感谢Bjarne Däcker——计算机科学实验室的头儿——感谢他的热情支持与鼓励,以及他在该语言的推广过程中的帮助。 许多人对这本书都有所贡献。Richard Ehrenborg编写了第??章中AVL树的代码。Per Hedel
-
致谢
本书以《ubuntu教程》为基础进行扩充,可以看作是《ubuntu教程》的第二版 一些章节,我会在 第 31 章 完美工作站 Archlinux,根据第 29 章 ConTeXt 入门指南中关于 ConTeXt 的内容,取材于《ConTeXt MkIV 学习笔记》,在神秘人士的指导下完成 关于 screen 的内容,由 roylez 担当顾问 mdz hxlReiase niuniu qxzw 木
-
致谢
写作本书所耗用的时间是我原来设想的四倍,而在写作期间,无论我身在何处,总感觉到脑袋上仿佛悬挂着一台大三角钢琴。没有以下众人的帮助,我便不可能完成本书的写作而仍然保持精神正常的状态。 本书的编辑,O'Reilly出版社的Andy Oram是一个作家梦寐以求的编辑。他不但谙熟自由软件行业(书中的许多题目是他建议的),而且具有一种非凡的才能,那就是知道对方想说什么,而且帮助对方找到最佳的表达方式。能与A
-
由以下原因导致的Java错误:Java。lang.ClassNotFoundException:com。科达哈尔。韵律学。JmxReporter[重复]
我正在运行JavaSpring Boot并收到此错误。怎么解决?我们在运行时看到它。我试图搜索github和谷歌,没有看到任何决议。
-
第一章:可靠性、可扩展性、可维护性
互联网做得太棒了,以至于大多数人将它看作像太平洋这样的自然资源,而不是什么人工产物。上一次出现这种大规模且无差错的技术, 你还记得是什么时候吗? ——阿兰·凯在接受Dobb博士杂志采访时说(2012年) [TOC] 现今很多应用程序都是 数据密集型(data-intensive) 的,而非 计算密集型(compute-intensive) 的。因此CPU很少成为这类应用的瓶颈,更大的问题通常来自数
-
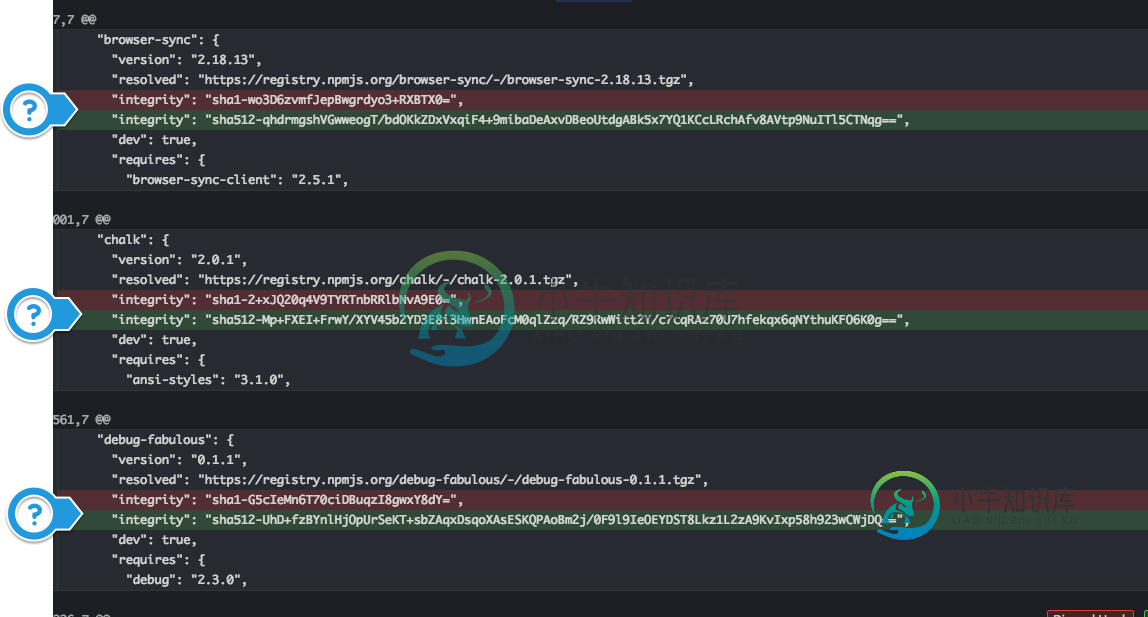 为什么包裹锁上了。json是否将完整性哈希从sha1更改为sha512?
为什么包裹锁上了。json是否将完整性哈希从sha1更改为sha512?我刚刚生成了一个新的npm锁文件,包锁。json,作为我典型工作流程的一部分。但我注意到,这次所有完整性哈希都从sha1更改为sha512。这里发生了什么?
-
维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?
本文向大家介绍维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?相关面试题,主要包含被问及维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?时的应答技巧和注意事项,需要的朋友参考一下 答:我是这样做的,尽可能使用约束,如check,主键,外键,非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据
-
何时计算python对象的哈希值,为什么-1的哈希值不同?
问题内容: 从这个问题出发,我很想知道何时 计算 python对象的哈希值? 在某个实例的时间 第一次叫 每次都被调用,或者 我还有其他机会吗? 这可能会根据对象的类型而有所不同吗? 为什么其他整数等于其哈希值呢? 问题答案: 通常可以在每次使用哈希时进行计算,因为您可以很容易地检查一下自己(请参阅下文)。当然,任何特定对象都可以自由缓存其哈希。例如,CPython字符串执行此操作,但元组不执行此
-
在DynamoDB中查询(使用哈希和范围主键)而不提供哈希键
我必须经常在那里做两件事:1。给定一个category#域,获取所有匹配项。2.给定grouptype#groupname,获取所有匹配项。 这两种操作都相当频繁,所以我不想使用扫描。在DynamoDB中有没有一种有效的方法可以做到这一点?是否有更好的方法来设计模式(更多的表、辅助索引等)?任何建议都是有帮助的。有人建议使用全局辅助索引,但我的问题是,我能否将主表的范围键作为GSI的哈希键?我知道