《分库分表》专题
-
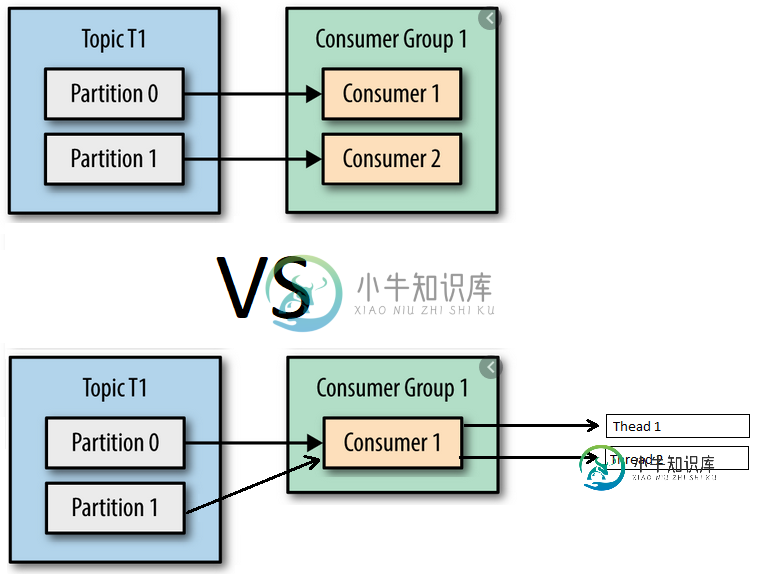 Kafka使用者/分区与线程/分区关系
Kafka使用者/分区与线程/分区关系我对Apache Kafka是新手,我试图理解以下两个方面的区别: 创建属于同一组id的两个使用者,这些使用者来自同一主题的两个分区。 用两个线程创建一个使用者,这些线程来自同一主题的两个分区。 在第一种方法中,我实际上理解的是,每个使用者将只使用与之“相关”的分区的消息,因为这两个使用者属于同一个组。 因此,在下面的示例中,可能会发生一些不同的情况: Thread1使用AAAA和CCCC/Thr
-
在SQL Server中分配行号,但按值分组
问题内容: 我想从表中选择2列,并为每个值分配一个int值。但是,我希望第一列ID对于所有相同的值都相同。 对于第二列,我希望每个值也要编号,但要按第一列进行分区。我已经弄清楚了这部分,但是我无法使第一部分开始工作。 这是我正在使用的测试方案。 当我运行它时,Column2_ID中的值是正确的,但是我希望Column1_ID的值如下。 问题答案: 您只需要使用其他排名功能, http://msdn
-
解析C#中的分部类和分部方法
本文向大家介绍解析C#中的分部类和分部方法,包括了解析C#中的分部类和分部方法的使用技巧和注意事项,需要的朋友参考一下 可以将类或结构、接口或方法的定义拆分到两个或多个源文件中。每个源文件包含类型或方法定义的一部分,编译应用程序时将把所有部分组合起来。 分部类 在以下几种情况下需要拆分类定义: 处理大型项目时,使一个类分布于多个独立文件中可以让多位程序员同时对该类进行处理。 使用自动生成的源时,无
-
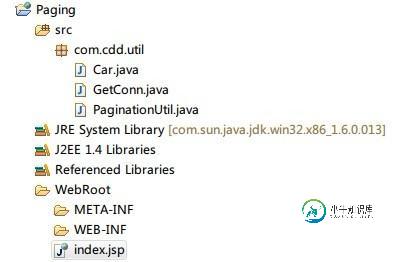 Hibernate框架数据分页技术实例分析
Hibernate框架数据分页技术实例分析本文向大家介绍Hibernate框架数据分页技术实例分析,包括了Hibernate框架数据分页技术实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Hibernate框架数据分页技术。分享给大家供大家参考,具体如下: 1.数据分页机制基本思想: (1)确定记录跨度,即确定每页显示的记录条数,可根据实际情况而定。 (2)获取记录总数,即获取要显示在页面中的总记录数,其目的是根据该数来确
-
如何在ConsumerSekCallback上查找之前分配分区?
我得到以下例外 在…上 来自Kafka文献- 寻找虚空(java.lang.String主题,int分区,长偏移量) 执行搜索操作。当从ConsumerSekAware调用时。onPartitionsAssigned(映射、ConsumerSekCallback)或来自ConsumerSekAware。onIdleContainer(Map,ConsumerSekCallback)立即对使用者执
-
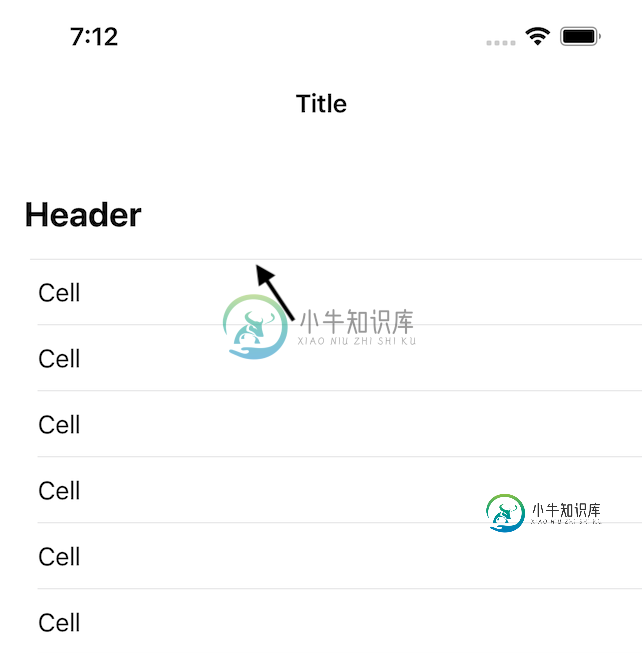 如何删除部分标题分隔符在iOS15
如何删除部分标题分隔符在iOS15在iOS 15中,在节头和第一个单元格之间添加分隔符: 如何隐藏或删除该分隔符? 几点注意事项 标题是从 查看视图调试器时,我可以看到额外的分隔符实际上是第一个单元格的子视图,它现在有一个顶部分隔符和一个底部分隔符。 除了设置更改单元格分隔符的插入外,这是一个完全标准的表视图,没有任何自定义设置
-
仅基于特定分隔符拆分字符串
我正在尝试拆分字段(在某个分隔符“;”)并将结果插入表中。最大值为5个子字符串,由“;”分隔。最多只有5个水果。如果只有水果列,如何拆分字符串以获得单独的水果。如果果数少于5,其余列将返回NA。 我首先创建了新列并将其全部设置为null。我尝试了以下代码,但它不起作用,如果水果比列少,其余列将只取最后一个水果的值而不是null。 是否还有其他信息可用于拆分字符串?
-
如何从谷歌分析转移到Firebase分析?
最近几个月,谷歌发布了一个新的分析替代方案,称为“Firebase Analytics”。 由于该应用程序已经有谷歌分析,我发现一些障碍,我不知道如何最好地处理。 > 以前,“newTracker”函数需要一个属性ID。现在我没有看到它。这是否意味着它不需要一个? 以前,“enableAdvertisingIdCollection”也可以用来收集广告信息。在新的API里找不到。是自动收藏的吗? “
-
如何使用Python将视频分成几部分?
我需要将任何大小的视频文件拆分为最大大小为75 MB的各个部分。我找到了此代码,但它不起作用:
-
Regex匹配用分号分隔的唯一数字
null 无效示例: 关于只有当值是唯一的时,我如何匹配有什么建议吗?
-
流分组后如何聚合分组实体By
我有一个简单的class
-
基于文本分类的Stanford CoreNLP情感分析
但是,我还没能在Stanford CorenLP中找到任何文本分类的注释器。我有什么办法可以实现我的想法。更好的是,有没有更好的方法来实现我想要实现的目标。 提前谢了。
-
 kafka -分区键放入错误分区的消息
kafka -分区键放入错误分区的消息我想知道,在什么情况下,具有相同分区键的消息会进入不同的分区。 我使用下面给出的命令运行了属于同一组的两个消费者在控制台中监听一个主题: 我使用“纳米/Kafka-php”库将消息放入带有键 的主题。当我发送多个这样的消息时,我发现很少有消息转到第二个消费者,而大多数消息都发送给消费者1。 由于我对所有消息使用相同的密钥,因此我希望所有消息都由同一个使用者使用。每个使用者都绑定到每个分区。 我使用
-
Azure DevOps Rest API从特定分支创建分支
我正在寻找一个Azure DevOps Rest API来从现有的分支创建一个新的分支。
-
如何在 Spark 中将分区分配给任务
假设我正在从S3文件夹中读取100个文件。每个文件的大小为10 MB。当我执行<code>df=spark.read时。parquet(s3路径),文件(或更确切地说分区)如何在任务之间分布?E、 g.在这种情况下,<code>df</code>将有100个分区,如果spark有10个任务正在运行以将该文件夹的内容读取到数据帧中,那么这些分区是如何分配给这10个任务的?它是以循环方式进行的,还是每