《集合》专题
-
web3.providers - 服务提供器集合对象
返回当前有效的通信服务提供器。 调用: web3.providers web3.eth.providers web3.shh.providers web3.bzz.providers ... 返回值: Object, 参见以下服务提供器对象: Object - HttpProvider: HTTP服务提供器已经被弃用,因为它不支持订阅。 Object - WebsocketProvider: W
-
使用 Java 集合类型(Using Java Collection Types)
除了Python的内置数据类型之外,Jython还可以通过导入java.util package来使用Java集合类。 以下代码描述了下面给出的类 - 带有add()的Java ArrayList对象 remove() ArrayList类的get()和set()方法。 import java.util.ArrayList as ArrayList arr = ArrayList() arr.ad
-
14 Python 数据类型详细篇:集合
这节课是数据类型篇最后一节了,这节课我们来讲下集合数据类型,集合这个数据类型很特殊,到底是个怎么特殊法,下面我们一起来看下: 1. 简介 1.1 定义 集合是一个无序、不重复的序列,集合中所有的元素放在 {} 中间,并用逗号分开,例如: {1, 2, 3},一个包含 3 个整数的列表 {‘a’, ‘b’, ‘c’},一个包含 3 个字符串的列表 1.2 集合与列表的区别 在 Python 中,集合
-
选择表或集合映射(步骤二)
这个步骤,在默认情况下,只有源和目标之间含有相同名的表或集合会在列表中映射。如果你不想同步某些表或集合,只需从下拉式列表手动禁用它们。 相同名的键和字段也会映射。你可以在“键映射”和“字段映射”列中更改映射。
-
选择表或集合映射(步骤二)
这个步骤,在默认情况下,只有源和目标之间含有相同名的表或集合会在列表中映射。如果你不想同步某些表或集合,只需从下拉式菜单手动禁用它们。 相同名的键和字段也会映射。你可以在“键映射”和“字段映射”列中更改映射。
-
选择表或集合映射(步骤二)
这个步骤,在默认情况下,只有源和目标之间含有相同名的表或集合会在列表中映射。如果你不想同步某些表或集合,只需从下拉式列表手动禁用它们。 相同名的键和字段也会映射。你可以在“键映射”和“字段映射”列中更改映射。
-
 快手前端|24秋招|面试合集
快手前端|24秋招|面试合集一面:70min 自我介绍 性能优化的两个问题,度量的手段?性能优化的方法中提升最大的方法是什么? 实习遇到的最大的挑战是什么,给你带来最深印象的是什么 平时用到的git操作 对懒加载的原理有了解吗 选课系统项目体积优化的方法 Electron的应用场景?现在给你一个场景,你要怎么用electron去设计他们之间的交互 给一个小白讲明白electron是什么,你会怎么讲 Electron有代表性的
-
Java 字符串文字池是对字符串对象的引用集合,还是对象的集合
问题内容: 阅读了SCJP Tip Line的作者Corey McGlone在javaranch网站上的文章后,我都感到困惑。从字面上看是Strings,由Kathy Sierra(javaranch的联合创始人)和Bert Bates共同编写的《 SCJP Java 6程序员指南》。 我将尝试引用Corey先生和Kathy Sierra女士对String Literal Pool的引用。 1.根
-
在Sagemaker中使用测试集拟合模型时,是否有方法接收测试集的预测?
我正在使用Sagemaker训练一个模型,特别是DeepAR图像,并将训练集和测试集作为功能的输入。示例代码: 我在培训结束时看到了一些测试结果指标,但我想得到实际的预测来进行分析。测试结果指标示例: 我发现最好的方法是根本不上传测试集,而是单独运行作业来获取测试预测。关于估计器,文档含糊其辞: S3保存训练结果的位置(模型工件和输出文件) 不知道其中包括什么。有没有办法得到测试集的预测?提前谢谢
-
将基于Eclipse / cdt的构建集成到持续集成中
问题内容: 我必须使用CDT,mingw和cdt管理的构建功能(没有外部makefiles或构建环境)来重用当前在eclipse中开发的主要C ++项目。该项目本身由许多子项目组成。 我想将该构建集成到一个连续集成服务器(即jenkins)中,因此必须能够自动化无头构建。 到目前为止,我设法签出了该项目(从jenkins轻松完成),并使用以下命令使用eclipse以无头模式构建它: 但是还不够:
-
JBOSS独立HornetQ组播集群在集群中抛出循环
18:38:14,391警告[org.hornetq.core.server.cluster.impl.clusterConnectionImpl](Thread-4(HornetQ-client-global-threads-20937207))MessageFlow RecordImpl[nodeid=3AFB4E60-Ed20-11E1-831C-109add44C09e,connector
-
 阿里巴巴集成数据采集前端社招面经
阿里巴巴集成数据采集前端社招面经(全程30分钟) 问我做过的项目,并介绍做过的项目 问如何封装一个表单项(暴露value和onChange,其他的就是一些设计细节什么的) hook和高阶组件各解决了什么问题,有什么优势 JS如何判断一个实例是数组实例(我说了instanceof和prototype.construct) JS数组元素去重(new Set,Object key) 如何遍历Object(Object.keys, fo
-
如何将数据随机分为训练集和测试集?
问题内容: 我有一个很大的数据集,想将其分为训练(50%)和测试集(50%)。 假设我有100个示例存储了输入文件,每一行包含一个示例。我需要选择50条线作为训练集和50条线测试集。 我的想法是首先生成一个长度为100(值范围从1到100)的随机列表,然后将前50个元素用作50个训练示例的行号。与测试集相同。 这可以在Matlab中轻松实现 但是如何在Python中完成此功能?我是Python的新
-
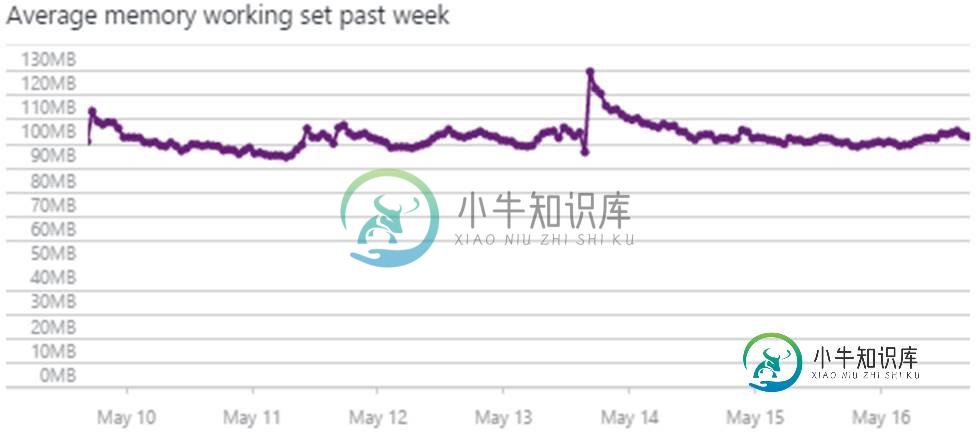 Azure中的平均内存工作集和内存工作集
Azure中的平均内存工作集和内存工作集我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示: 现在,我有三个问题: > 如何找出我的服务的专用最大内存是多少?一旦达到限制会发生什么? 内存工作集是进程中的线程最近接
-
如何有效查询数据集中的连续日期集?
问题内容: 我有一个表,每个月的每月(一年中的每个月)包含1条记录。我需要确定给定月份的站点是否至少有15个连续记录,并且我需要知道该连续天数的开始和结束日期。我可以在存储过程中执行此操作,但我希望可以在单个查询中完成此操作。我正在处理一个相当大的数据集,每月至少有3000万条记录。 结果示例: 感谢您的帮助! 问题答案: 这是有关如何执行此查询的示例: 然后查询: 结果: 问候,罗布。