《CPU》专题
-
PyTorch使用cpu加载模型运算方式
本文向大家介绍PyTorch使用cpu加载模型运算方式,包括了PyTorch使用cpu加载模型运算方式的使用技巧和注意事项,需要的朋友参考一下 没gpu没cuda支持的时候加载模型到cpu上计算 将 改为 然后删掉所有变量后面的.cuda()方法 以上这篇PyTorch使用cpu加载模型运算方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
PyTorch 随机数生成占用 CPU 过高的解决方法
本文向大家介绍PyTorch 随机数生成占用 CPU 过高的解决方法,包括了PyTorch 随机数生成占用 CPU 过高的解决方法的使用技巧和注意事项,需要的朋友参考一下 PyTorch 随机数生成占用 CPU 过高的问题 今天在使用 pytorch 的过程中,发现 CPU 占用率过高。经过检查,发现是因为先在 CPU 中生成了随机数,然后再调用.to(device)传到 GPU,这样导致效率变得
-
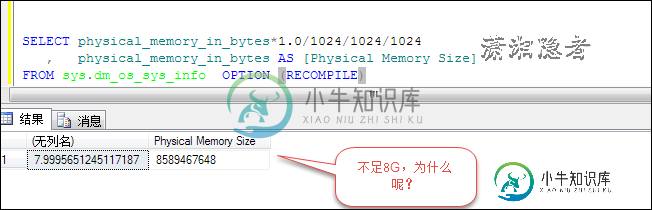 SqlServer如何通过SQL语句获取处理器(CPU)、内存(Memory)、磁盘(Disk)以及操作系统相关信息
SqlServer如何通过SQL语句获取处理器(CPU)、内存(Memory)、磁盘(Disk)以及操作系统相关信息本文向大家介绍SqlServer如何通过SQL语句获取处理器(CPU)、内存(Memory)、磁盘(Disk)以及操作系统相关信息,包括了SqlServer如何通过SQL语句获取处理器(CPU)、内存(Memory)、磁盘(Disk)以及操作系统相关信息的使用技巧和注意事项,需要的朋友参考一下 在SQL SERVER中如何通过SQL语句获取服务器硬件和系统信息呢?下面介绍一下如何通过SQL语句获取
-
 docker CPU限制的实现
docker CPU限制的实现本文向大家介绍docker CPU限制的实现,包括了docker CPU限制的实现的使用技巧和注意事项,需要的朋友参考一下 1、--cpu=<value> 1)指定一个容器可以使用多少可用的CPU资源,但无法让容器始终在一个或某几个CPU上运行 2)例如:如果主机有2个CPU,设置--cpus="1.5",则可以报称容器醉倒 容纳一半的CPU,相当于设置--cpu-
-
MySQL高CPU使用率
问题内容: 关闭。 这个问题是题外话。它当前不接受答案。 想改善这个问题吗? 更新问题,使其成为Stack Overflow 的主题。 7年前关闭。 最近,我的服务器CPU性能一直很高。 CPU平均负载为13.91(1分钟)11.72(5分钟)8.01(15分钟),而我的站点的流量仅略有增加。 运行完最高命令后,我看到MySQL使用的CPU是160%! 最近,我一直在优化表,并切换到持久连接。这会
-
如何在Elasticsearch集群上最大化CPU核心
问题内容: 我必须设置多少个分片和副本才能使用群集中的每个cpu核心(我希望100%的负载,最快的查询结果)? 我想使用Elasticsearch进行聚合。我读到Elasticsearch使用多个cpu核心,但是没有找到关于cpu核心在分片和副本方面的确切细节。 我的观察是,单个分片在查询时使用的内核/线程不超过1个(考虑到一次仅查询一个)。使用副本时,查询1-shard索引的速度不会更快,因为E
-
正则表达式疯狂:java.util.regex.Pattern匹配器进入高CPU循环
问题内容: 注意:我已经看到了这个问题,但是还没有人回答,所以没有太大帮助。奇怪的是,被标记为“可能重复”的问题已被删除(我第一次看到它。) 我们在使用Pattern进行正则表达式验证时遇到问题。这些都没有发生在我们的代码中,整个事情都在Spring Framework和Hibernate的验证中发生。 (Spring 3.2.1,Spring 3.1.1,Hibernate Validation
-
setInterval CPU是否密集?
问题内容: 我在某处读到setInterval占用大量CPU的信息。我创建了一个使用setInterval的脚本,并监视了CPU使用率,但没有发现任何变化。我想知道是否有什么我想念的。 代码要做的是每100毫秒检查一次URL中的哈希值(#后面的内容)是否更改,如果更改了,请使用AJAX加载页面。如果未更改,则什么都不会发生。会不会有CPU问题。 问题答案: 我认为不会从本质上引起您严重的性能问题。
-
预测SJF进程的CPU突发时间
主要内容:1. 静态技术,进程类型,动态技术SJF算法是最好的调度算法之一,因为它提供了最大的吞吐量和最少的等待时间,但是该算法的问题是,CPU的突发时间无法预先知道。 我们可以估算某个进程的CPU爆发时间。 有多种技术可用于假定进程的CPU突发时间。假设需要准确以便最佳地利用算法。 有以下技术用于假定某个进程的CPU爆发时间。 1. 静态技术 进程大小 可以根据其大小预测进程的爆发时间。 如果有两个进程和,并且旧进程的实际突发时间为20秒
-
 操作系统CPU调度
操作系统CPU调度主要内容:进程控制块中保存了什么?,为什么需要调度?在像MS DOS这样的单编程系统中,当进程等待任何I/O操作完成时,CPU仍然是空闲的。 这是一个开销,因为它浪费时间并导致饥饿问题。 但是,在多程序系统中,CPU在进程的等待时间内不会保持空闲状态,而是开始执行其他进程。 操作系统必须定义CPU将被给予哪个进程。 在多程序系统中,操作系统调度CPU上的进程以获得最大的利用率,此过程称为CPU调度。 操作系统使用各种调度算法来调度过程。 这是短期调
-
为什么Python在更多CPU/核心上的并行化规模如此之小?
我试图在Python3.8中使用更多可用的内核,通过并行化(通过joblib)来加快计算速度,但观察到它的扩展性很差。 我编写了一个小脚本来测试和演示稍后可以找到的行为。脚本(请参阅后面的内容)设计成有一个完全独立的任务,使用NumPy和Pandas对虚拟操作进行一些迭代。没有任务的输入和输出,没有磁盘或其他I/O,也没有任何通信或共享内存,只是简单的CPU和RAM使用。除了对当前时间的偶尔请求之
-
每个JVM或每个CPU核的线程数
基于每个JVM的CPU核数创建线程与在多个JVM上运行的线程在CPU核数上创建线程数,条件是所有JVM运行在共享同一CPU的一个物理系统上有何不同?换句话说,一个并行运行8个线程的多线程Java程序vs在共享同一CPU的8个不同JVM上运行的同一多线程程序? 下面我给出了一些我发现的用线程实现并行处理的方法,但是我不能理解它们之间的本质区别? 方法一:线程周期性地查询数据库更改,并行地启动(长时间
-
有什么方法可以在32位x86中使用MOV移动2个字节而不会导致模式切换或cpu停顿?
如果我想把2个无符号字节从内存移到32位寄存器中,我可以用指令而不是模式切换吗? 我注意到,您可以使用和指令来完成此操作。例如,使用,编码将16位移动到32位寄存器。不过,这是一个3个循环的指令。 或者,我想我可以将4个字节移动到寄存器中,然后以某种方式CMP其中的两个字节。 在32位x86上检索和比较16位数据的最快策略是什么?请注意,我主要是在执行32位操作,所以我不能切换到16位模式并停留在
-
您可以使用task.run将CPU绑定的工作移到后台线程[重复]
从msdn中, 您可以使用task.run将CPU绑定的工作移到后台线程。 我的问题是,还有其他选择吗?如果我想使用关键字,我必须返回Task,因此我必须使用 上面的代码不是唯一可以使用的选项吗?如果没有,你能展示其他选择吗?如果我不使用task.run,为什么我需要异步/await?
-
Kafka经纪人的高CPU使用率
我们正在使用带有 5 个代理的 Apache Kafka 2.2 版本。我们每天收到 50 数百万个事件,但我们达到了高 kafka CPU 使用率。我们使用默认的生产者/消费者/代理设置。 我对表演有一些疑问; 我们有不同的kafka流应用程序,它们进行聚合或连接操作以携带丰富的消息。我们所有的kafka-流应用程序都包含以下设置: < li >恰好一次:true < li >最小同步副本:3