《CPU》专题
-
TensorFlow的random_poisson仅在CPU上运行
我正在尝试让TensorFlow的函数在我的GPU上运行;假设这个TensorFlow源页面有一个函数,该函数在CPU和GPU上运行时比较的输出,那么这似乎是可能的。但是,在使用代码进行测试时: 我得到了错误: 谢了!
-
什么JVM可以在CPU和GPU上运行?
什么JVM在CPU+GPU上运行? 我知道像Oracle、Zulu、OpenJDK这样的JVM,但没有一个是为了将处理卸载到GPU上而设计的。
-
Windows Server上CPU使用率高的故障排除
我们有基于J2EE的web应用程序。在我们的生产环境中,我们间歇性地面临高CPU使用率(80-90%)。我们无法在QA环境中复制它。 生产环境:Windows 2012 Server(64位)、JDK 1.8(64位) 对于故障排除,我们采用了线程转储。它显示了总共215个线程。 我们如何找到哪些线程导致高CPU使用率? 2016-03-01 11:07:52全线程转储Java热点(TM)64位服
-
CPU使用率低于阈值且存在多个节点-普罗米修斯
我试图在prometheus中创建一个警报规则,以便当标签为agentpool=“worker”的所有节点在过去3分钟内的平均CPU使用率低于30%时,它会发出警报。
-
我如何得到一个豆荚的(毫)核心CPU使用普罗米修斯在库伯内特?
我运行了Kubernetes的自定义设置,并使用Prometheus刮取各种度量。除其他外,我还收集了和度量标准。 我想回答这样一个问题:“在我的部署中,有多少由和定义的CPU资源实际上被pod(及其容器)使用了(毫厘)核?” 有很多可用的量度,但没有这样的量度。也许它可以用秒的CPU使用时间来计算,但我不知道如何计算。 我一直在考虑这是不可能的--直到一个朋友告诉我,她在集群中运行Heapste
-
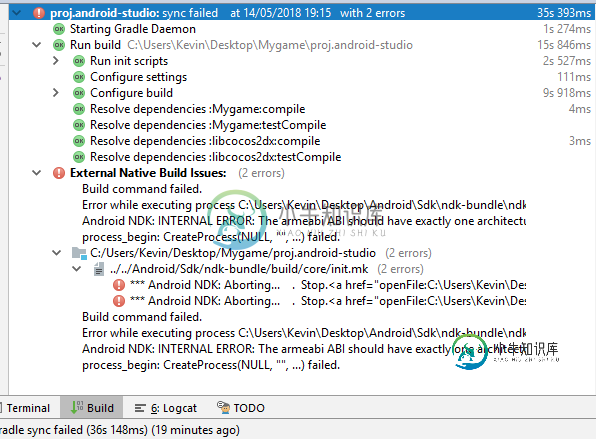 我的NDK项目由于CPU架构相关的问题而无法编译
我的NDK项目由于CPU架构相关的问题而无法编译有人能解释一下为什么我会出现这些错误吗?
-
Aparapi GPU执行速度比CPU慢
我正在尝试测试Aparapi的性能。我看到过一些博客,其中的结果显示,Aparapi确实在做数据并行操作的同时提高了性能。 但我在测试中没有看到这一点。这里是我所做的,我写了两个程序,一个使用Aparapi,另一个使用普通循环。 方案1:在Aparapi 程序2:使用循环 程序1需要大约330ms,而程序2只需要大约55ms。我是不是做错什么了?我在Aparpai程序中打印出了执行模式,它打印出的
-
JMeter:Perfmon报告显示服务器CPU使用率为100%,但在AWS仪表板上仅为1.5%
-
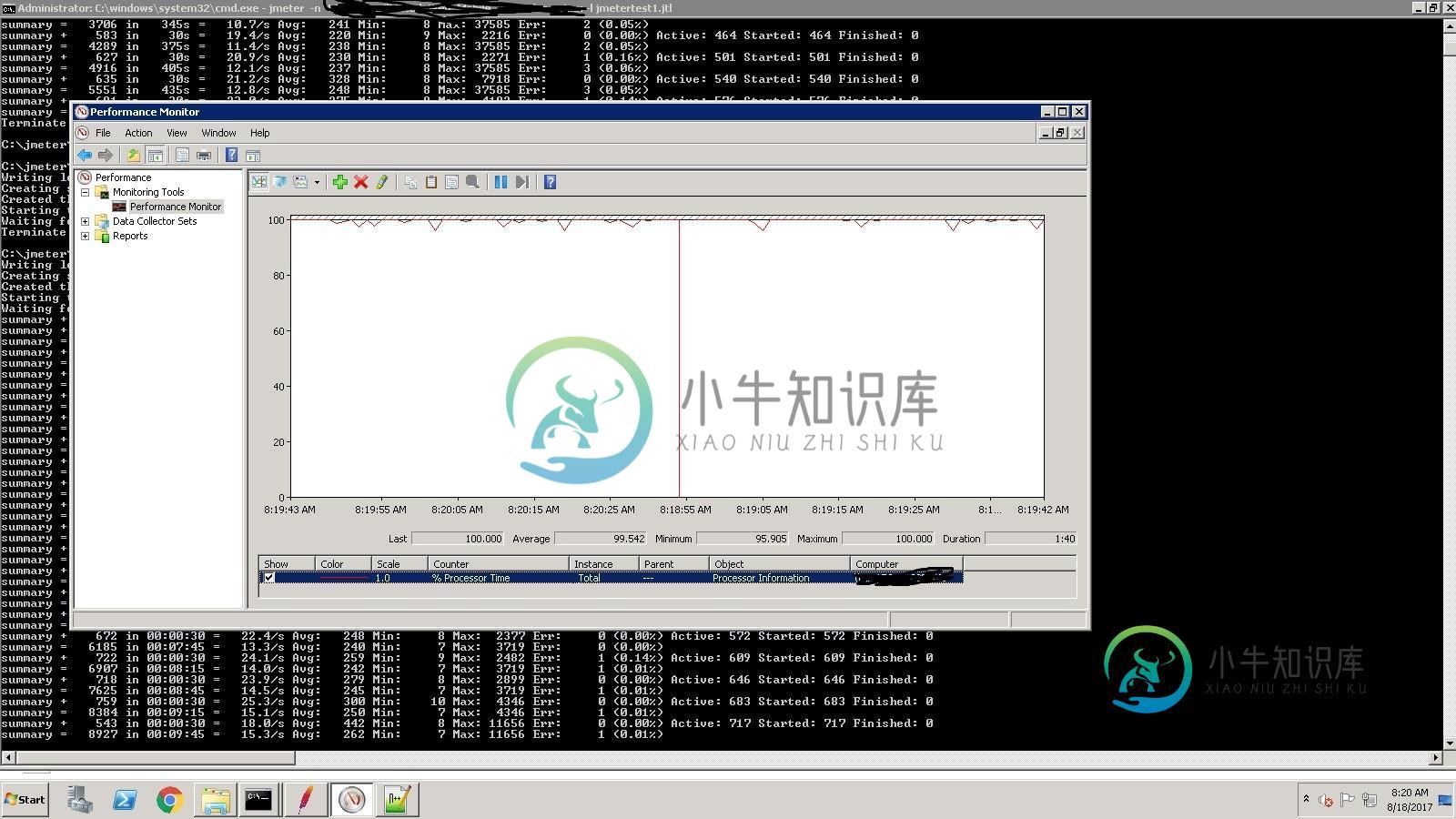 加载发电机(windows)达到100%CPU
加载发电机(windows)达到100%CPU我正在从AWS windows VM运行2250个用户测试,以下是详细信息。 Windows RAM:32GB CPU:8核 一旦测试达到600个并发用户,cpu的利用率将达到100%。为解决此问题而采取的操作(使用Jmeter进行测试) 增加了堆大小(Heap=-xms512m-xmx12288m) 从测试中删除lisners。 从非GUI模式运行测试。 发电机的负荷仍然达到100%。解决这个问
-
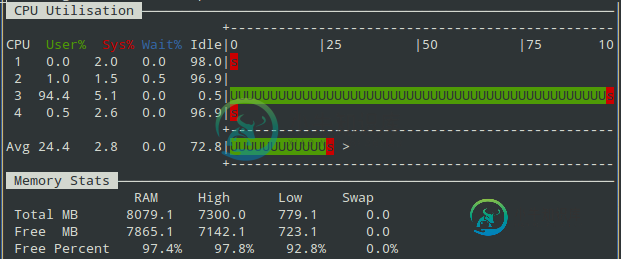 node.js CPU负载平衡
node.js CPU负载平衡我用JMeter创建了测试来测试幽灵博客平台的性能。Ghost是用Node.js编写的,安装在云服务器上,有1GB的内存和1个CPU。 我注意到在400个并发用户之后JMeter得到错误。到400个并发用户的负载是正常的。我决定增加CPU,增加了1个CPU。 但是错误重现并添加了2个CPU,总共4个CPU。问题发生在400个并发用户之后。 我想知道是否有可能平衡CPU之间的负载?
-
Java-为什么这个基本的滴答类会占用这么多cpu?
详细信息:对于我开发的很多程序,我使用此代码(或一些轻微的变体)每隔一段时间“勾选”一个方法,设置为可变tps(如果设置为32,则每秒调用该方法滴答32次)。它非常重要,所以我不能从我的代码中删除它,因为动画和其他各种部分会损坏。 不幸的是,它似乎使用了大量的cpu,原因我不知道。不久前,我在考虑使用thread.sleep()来解决这个问题,但根据这篇文章;它相当不准确,这使得它不可行,因为这需
-
CPU缓存:两个地址之间的距离是否需要小于8字节才能具有缓存优势?
这似乎是一个奇怪的问题... 假设缓存线的大小为64字节。此外,假设L1、L2、L3具有相同的缓存线大小(这篇文章说Intel Core i7就是这样)。 内存上有两个对象,,它们的(物理)地址相隔N个字节。为简单起见,让我们假设在缓存边界上,也就是说,它的地址是64的整数倍。 1) 如果 2)如果 我的问题是,如果 改写-加载时,让t表示获取的时间,t(N=70)是否比t(N=999999)小得
-
Intel SandyBridge系列CPU流水线程序的去优化
我已经绞尽脑汁了一个星期,想完成这个任务,我希望这里有人能引导我走上正确的道路。我先从教官的指示说起: 你的作业与我们的第一个实验作业相反,我们的第一个实验作业是优化一个素数程序。你在这份作业中的目的是使程序悲观,即使它运行得更慢。这两个都是CPU密集型程序。在我们的实验室电脑上运行需要几秒钟的时间。您不能更改算法。 若要解除程序的优化,请使用您对Intel i7管道运行方式的了解。想象一下重新排
-
如何提高单核cpu反应式编程的性能
我有一个连接到第三方服务并将结果返回给客户端的应用程序。在内部,应用程序向第三方服务发出GET请求并获取结果。我已经使用Reactor和reactive代码在重负载下扩展应用程序。这是一个SpringBoot项目,它运行嵌入式Tomcat并依赖于Web客户端(被动netty向第三方发出请求)。不知何故,CPU利用率和响应时间都比阻塞模式差。硬件设置在Kubernetes中运行单核。 该项目建立在库
-
Spring云网关:RHEL上的高CPU利用率:可以从epoll切换到NIO
如下文所述,我们看到部署在RHEL上的spring cloud gateway应用程序的cpu利用率很高。详细信息可在以下链接中获得 根据@SpencerGibb给出的建议,已经尝试使用最新版本的gateway和boot,但在PST期间仍然看到高cpu利用率。似乎大部分的利用是由反应堆“ePoll”线程完成的。 是否有任何反应堆/网管优化可以尝试来提高性能?似乎除了“ePoll”之外,还有使用NI