《均衡》专题
-
需要帮助查找平均值
我似乎无法从用户输入的分数中计算出平均分数。我也不能让它停止例外输入大于100或小于0。有人能告诉我我做错了什么吗?谢谢
-
3个长整数的平均值
我有3个非常大的有符号整数。 我想计算它们的截断平均值。预期平均值是,即。 不可能计算为: 注:我读了所有关于2个数字的平均值的问题,但我不知道该技术如何应用于3个数字的平均值。 使用BigInteger将非常容易,但假设我不能使用它。 如果我转换为双精度,那么,当然,我会失去精度: 如果我转换为,它可以工作,但也让我们假设我不能使用它。 问题:有没有一种方法可以仅使用长类型来计算3个非常大整数的
-
如何从ArrayList计算平均值
我试图从购物车(ArrayList)中计算平均值。平均值是指所有产品的总和除以它的数量?,如果我错了请纠正我,也许这就是为什么我的逻辑不太好用。 我试图做一个循环来计算所有乘积的总和,然后除以它的数量。
-
EJB和JX-RS资源均为Bean
就应用程序服务器在运行时创建的对象而言,它们之间的区别是什么 > 使bean同时成为EJB和JAX-RS资源 @无状态 @local @path(“current”) 公共类外观 { @PersistenceContext EntityManager EntityManager; @EJB ... //方法 } 使用两个不同的bean @path(“current”) 公共类外观 { @ejb 私
-
QueryDSL中的平均日期差异
我有一个实体,它有一个表示上次活动的日期对象。我想查询一下平均空闲时间。因此在SQL中,类似于: 我试着这样算了一下差别: 我如何以日期/时间差(以秒为单位)来表示这个平均值?
-
基于键的平均树图值
我有一个treemap存储密钥和值,如下所示: 我需要一些帮助来弥补这方面的差距。有没有更好的办法做到这一点?
-
data.table中唯一值的平均值
我有数据。下表 我想按组查找每列中唯一值的总和。 我尝试了以下内容,它给了我每列中所有值的总和(但不是唯一值)。 然而,我只想找到唯一值的和。 答案应该是这样的- 谢谢
-
火花指数移动平均线
我也看过Pyspark中的加权移动平均线,但我需要一个Spark/Scala的方法,以及10天或30天的均线。 有什么想法吗?
-
Spark Java中的移动平均线
-
带numpy.convolve的加权移动平均
我正在写一个移动平均函数,它使用numpy中的卷积函数,它应该相当于一个(加权移动平均)。当我的权重都相等时(就像在一个简单的算术平均值中一样),它工作得很好: 给予 对这种行为有什么看法吗?
-
求list的平均分并排序
定义一个int型的一维数组,包含40个元素,用来存储每个学员的成绩,循环产生40个0~100之间的随机整数, (1)将它们存储到一维数组中,然后统计成绩低于平均分的学员的人数,并输出出来。 (2)将这40个成绩按照从高到低的顺序输出出来。 解决(python) #! /usr/bin python #coding:utf-8 from __future__ import division
-
十二、为什么均值重要
在这个课程中,我们已经研究了几个不同的统计量,包括总编译距离,最大值,中位数和平均值。在关于随机性的明确假设下,我们绘制了所有这些统计量的经验分布。有些统计量,比如最大和总变异距离,分布明显偏向一个方向。但是,无论研究对象如何,样本均值的经验分布几乎总是接近钟形。 如果随机样本的性质是真的,不管总体如何,它都能成为一个有力的推理工具,因为我们通常不清楚总体中的数据。大型随机样本的均值分布属于这类性
-
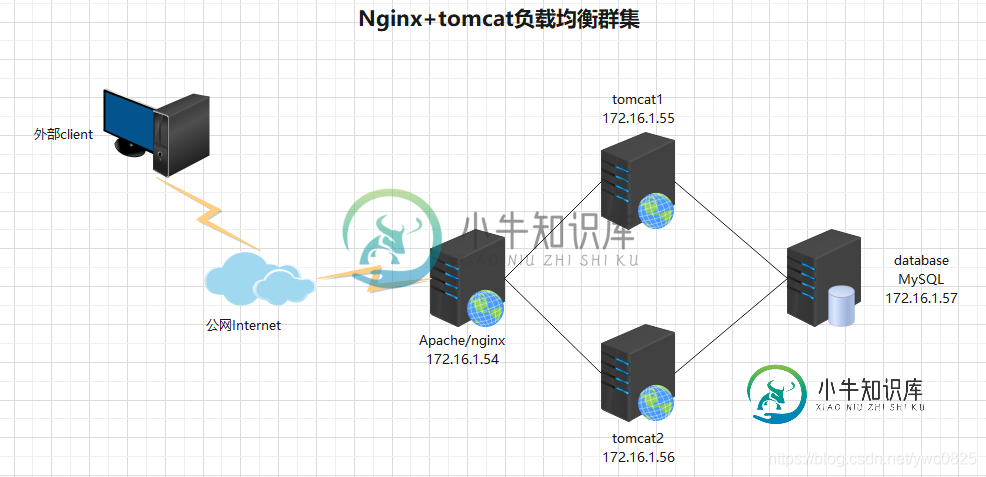 Nginx+tomcat负载均衡集群的实现方法
Nginx+tomcat负载均衡集群的实现方法本文向大家介绍Nginx+tomcat负载均衡集群的实现方法,包括了Nginx+tomcat负载均衡集群的实现方法的使用技巧和注意事项,需要的朋友参考一下 实验环境如下 这里需要准备4台服务器(1台nginx、2台tomcat做负载、一台MySQL做数据存储) 准备软件包如下: 软件包地址连接: 链接: https://pan.baidu.com/s/1Zitt5gO5bDocV_8TgilvRw
-
windows下nginx+tomcat配置负载均衡的方法
本文向大家介绍windows下nginx+tomcat配置负载均衡的方法,包括了windows下nginx+tomcat配置负载均衡的方法的使用技巧和注意事项,需要的朋友参考一下 目标:Nginx做为HttpServer,连接多个tomcat应用实例,进行负载均衡。 注:本例程以一台机器为例子,即同一台机器上装一个nginx和2个Tomcat且安装了JDK1.7。 1、安装Nginx 安装Ngin
-
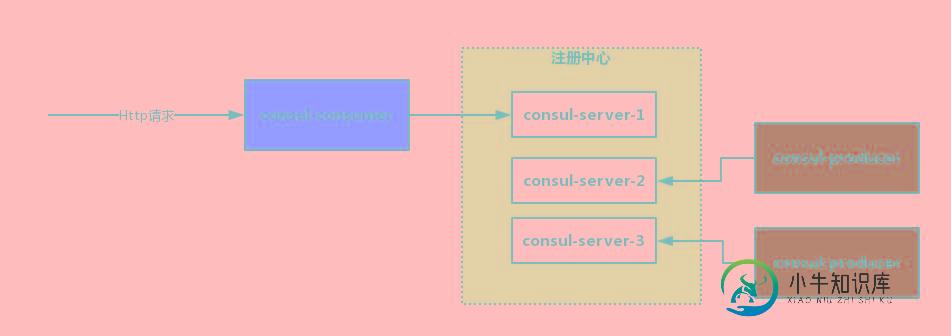 SpringCloud与Consul集成实现负载均衡功能
SpringCloud与Consul集成实现负载均衡功能本文向大家介绍SpringCloud与Consul集成实现负载均衡功能,包括了SpringCloud与Consul集成实现负载均衡功能的使用技巧和注意事项,需要的朋友参考一下 负载均衡(Load Balance,简称LB)是一种服务器或网络设备的集群技术。负载均衡将特定的业务(网络服务、网络流量等)分担给多个服务器或网络设备,从而提高了业务处理能力,保证了业务的高可用性。负载均衡基本概念有:实服务