《hash》专题
-
Java Hashmap从对象键获取值
初学者问题:我有一个hashmap,它将整数数组存储为值。每个值的键是一个由两个整数(坐标)组成的对象。 我的问题是:如何根据对象中的两个坐标(我的“键”)从hashmap检索值? 我的协和类(在Eclipse的一点帮助下): 构建Hashmap: 如果我想访问坐标12,13上的数组,如何检索它?是否需要迭代(我希望不是,我想添加100000个坐标,当然要快速访问)。 我希望这能在某种程度上符合
-
如何使用PHP实现java hashmap?
我使用PHP处理以下输入:sam 99912222 tom 1112222 harry 12299933 sam edward harry第1到第6行是姓名和电话号码。最后三行是搜索查询,如果姓名不在列表中(没有电话号码,打印未找到),否则输出数据。我的代码如下: 例外输出应为sam=99912222未找到harry=12299933输出为sam=99912222未找到未找到。为什么这些功能不起作
-
我可以在HashMap中缓存来自ChannelHandlerContext的通道吗?
如果缓存通道[]而不是缓存ChannelHandlerContext,会有什么不同吗? 以下是实现的步骤和问题: > Netty服务器处理程序从客户端接收消息 因为有其他正在运行的线程来处理用户数据,所以我们需要将此请求放到队列中,并让辅助处理 服务器和客户端之间的多消息交换需要使用相同的连接 每当消息准备好从辅助线程发送到客户端时,最好使用缓存在HashMap中的通道 final Channel
-
如何在HashMap中以迭代id为键存储特定对象
我正在做一个程序。我将用户存储在ArrayList中,所以我有一个UserCollection类作为用户的储存类别。但是鉴于UserCollection被认为是一个数据库,数据库中的每个用户条目都应该有一个唯一的id。最初我有一个userID作为User类中的字段,但现在我试图处理UserCollection中的id部分。如果我使用一个hashmap,其中键将是id,值是User我将如何继续迭代i
-
使用自定义Pair Object作为键访问HashMap值
我是新来Java。我正在写一个二维游戏,我决定使用哈希地图来存储我的地图数据,因为我需要支持我的地图坐标的负索引。这是因为地图的大小可以在游戏过程中增长。 我编写了一个自定义Pair类,用于存储最终的x和y值。我使用这个Pair对象作为我的HashMap的密钥。我的值是自定义Cell类的实例。 我已经声明我的HashMap如下:
-
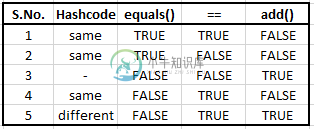 在HashSet中插入对象的条件?
在HashSet中插入对象的条件?请耐心等待,因为我试图引入一个与许多活动线程直接矛盾的新概念。 在HashSet中插入对象的条件是什么? 查看源代码,它会关注: 完整代码位于:HashSet.java 所以,这取决于 哈希码 等于() == 即如果它们是相同的对象。 看看条件4。尽管equals()返回false,但对象会被添加到HashSet。在所有其他情况下,当且仅当equals()返回false时,对象才会被添加。因此,可
-
防止重复对象被添加到ArrayList或HashSet中
所以我的目标是把一个字符串拆分成一个Word对象数组。我只想要一个对象来表示一个英语单词,这意味着在添加到数组之前应该过滤掉重复的单词。我一辈子都不知道为什么我过滤掉重复单词的标准失败了。我已经尝试了ArrayList和HashSet。我的目标是在字符串中计算该单词的实例,但我还没有实现。 我的单词分类是: 这是我当前的输出: 单词集大小:18 |单词列表大小:18 word: the | cou
-
在 Java 中将 ArrayList 添加到 HashSet
我的任务是实现一个蛮力算法来输出一些n的整数[1,2,…, n]的所有排列。但是,我似乎在将ArrayList对象添加到HashSet时遇到了一些问题: 我发现对“nextPer的连续调用确实找到了所有排列,但是我不明白当我将排列添加到HashSet“allPer的排列”时会发生什么。我在n=3的情况下运行时得到的输出是这样的: [[3, 2, 1, 1, 2, 1, 1, 3, 1, 2], [
-
MapmyMap=new HashMap和HashMapmyMap=new HashMap之间有什么区别?[副本]
当我想初始化一个HashMap时,我是Java新手。我可以找到这两个解决方案: 我知道Map是一个接口,HashMap实现了它。但为什么我们这里有两个?他们每个人都有什么好处?
-
 在Java中,即使在“电话号码查询代码”中使用HashMap,也会超过时间限制
在Java中,即使在“电话号码查询代码”中使用HashMap,也会超过时间限制你会得到一本电话簿,里面有人们的名字和电话号码。之后,你会得到一些人的名字作为查询。对于每个查询,打印该人的电话号码。 输入格式 第一行有一个整数,表示通讯录中的条目数。每个条目由两行组成:姓名和相应的电话号码。 在这些之后,将会有一些查询。每个查询将包含一个人的姓名。读取查询直到文件结束。 限制条件:一个人的姓名仅由小写英文字母组成,可能采用“名字姓氏”格式,也可能采用“名字”格式。每个电话号码
-
如何用流API在Java中将Array转换为HashMap
我知道如何使它与每一个,但我希望有它在映射,任何帮助都将不胜感激
-
来自字段字符串concat的Hashcode与自动生成方法的比较
如果我们有如下类: 并且要在或中使用它,则需要实现和 为该类自动生成的是: 但我想知道我们是否应该这样做: 这比自动生成的方法更好还是更差?类似的方法也在其他脚本语言中使用,正如我所见,我想知道生成的散列是更好还是更差(或者没有区别)。 注意:假设字符串concat可以被缓存并因此得到优化,我们将其忽略为性能下降
-
如果Key的哈希码相同但等于方法return false,HashMap如何检索不同的值
我无法理解HashMap的工作模式。请帮助理解它。 假设我们有两个对象Obj1和Obj2,它们的Hashcode都是1212。现在,当我们运行“==”和equals时,它返回false。 现在我使用ValueObj1和Valueobj2作为HashMap中的值,分别具有键Obj2和Obj3。我相信这两个值将保存在与List相同的桶中。 我的问题是HashMap如何为Obj2选择Valueobj2,
-
Hashmaps的问题
我在尝试迭代一个句子时遇到了一个问题,这个句子是用户为我的HashMap中的匹配词输入的。例如,如果用户输入“I is reading with the professor”。教授是关键字。我想扫描用户输入的关键字professor或它在HashMap中的同义词的句子。到目前为止,当我运行我的程序时,代码只是挂起。 下面是我的主要方法: 和我的hashmap方法: Parsefile检查文本文件中
-
如何从Java的HashMap填充列表?
作为我作业的一部分,我们得到了一个我们不能更改的接口,以及一些用来开发我们方法的预定义测试。 界面如下: 我正在运行的特定测试: 以及我需要从测试中创建的方法: 从测试中我可以看出,在方法中,我需要创建并用注册映射中匹配的学生填充它,然后返回列表。 我创建了以下字段:- 我搞不懂的是,如何将注册地图中的数据传递到学生列表中,以使测试中的断言为真。