《缓存穿透》专题
-
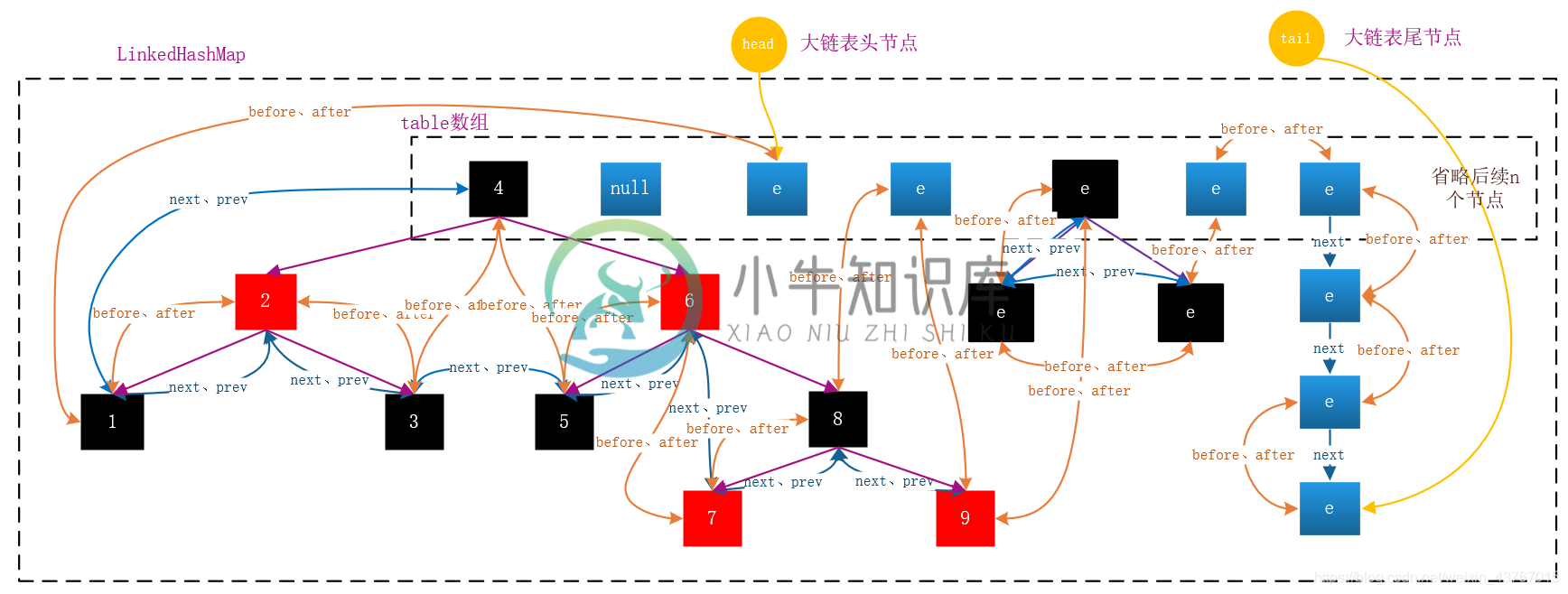 LinkedHashMap解析与LRU缓存实现
LinkedHashMap解析与LRU缓存实现主要内容:1 LinkedHashMap的概述,2 LinkedHashMap的源码解析,2.1 主要类属性,2.2 构造器,2.4 常见API方法,2.5 大链表与迭代顺序的维护,3 LinkedHashMap与LRU缓存,3.1 afterNodeInsertion方法,3.2 removeEldestEntry方法,3.3 LRU缓存实现案例,4 LinkedHashMap的总结本文基于JDK1.8详细介绍了LinkedHashMap的底层原理,它到底是如何保证元素有序的?同时讲解了基于访
-
缓存 - Spring Cache中@CachePut的疑问?
如题,查阅资料得知@CachePut的作用是无论是否存在缓存,否会把方法的返回值更新入缓存,作用是更新缓存,适用于update操作。 假如我写个方法: public int updateUser(User user){},int表示0,1,那这个缓存有什么意义呢?而且执行了update后,@Cacheable的数据会同步更新吗?不更新数据不是就不对了吗? 实际项目中update了以后到底应该怎么做
-
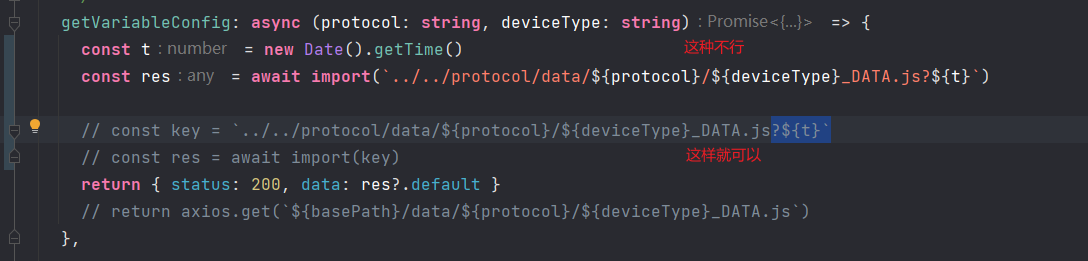 javascript - js import() 如何清除缓存?
javascript - js import() 如何清除缓存?js import() 如何清除缓存?我有个需求需要动态导入一些js脚本,使用import()导入默认会有缓存,会有很大影响,如何才能实现每次导入的时候清除缓存? 加时间戳的方式其实我刚开始也试了,但使用的第一种方式,这种就会报错,但是我改成方式二,就可以,真奇怪,没有大佬能解释一下这个原因?使用的是vite
-
服务工作者和透明缓存更新
我试图安装一个简单的ServiceWorker,但旧的,Django Web应用程序。我开始使用Chrome团队的示例读取缓存示例 这很好,但并不理想,因为如果需要,我想更新缓存。根据阅读此处所有其他服务人员的答案,有两种推荐方法。 > 使用一些服务器端逻辑来知道您显示的内容何时更新,然后更新您的服务辅助角色以更改所述内容。例如,这就是sw-preache所做的。 只要在需要更新资源时更新serv
-
在可缓存方法类强制转换异常中调用Spring可缓存方法
我正在尝试使用Spring Cacheable,但我得到一个类强制转换异常 例外情况是,
-
Spring缓存抽象VS接口VS key param(“为缓存操作返回null key”错误)
. 请注意,IAddItMethod不是指定@Cacheable的方法。我们可以有没有@Cacheable注释的其他实现(例如MethodImplThree)。 我们有一个简单的beans.xml: 有什么我忘了具体说明的吗?配置?注释? 提前感谢!
-
在Linux中,缓冲区与缓存之间有什么区别?
问题内容: 对我而言,尚不清楚两个Linux内存概念和之间有什么区别。 缓冲区的策略是先进先出 缓存的策略是“最近最少使用”。 我对吗? 特别是,我正在查看两个命令:和 问题答案: “缓冲区”表示RAM的多少部分专用于缓存磁盘块。“缓存”类似于“缓冲区”,只是这次它缓存文件读取中的页面。 引用自: https://web.archive.org/web/20110207101856/http://
-
在Redis缓存中存储多个版本的数据
问题内容: 我有一些产品数据需要在Redis缓存中存储多个版本。数据是JSON序列化的。获取纯(基本)数据的过程非常昂贵,将其自定义为不同版本的过程也很昂贵,因此我想缓存所有版本以尽可能进行优化。假设自定义基于单个参数,我可以将该参数用作缓存键的一部分。 我计划用来检索产品数据的过程是这样的: 一切都很好,但是我现在正在尝试找出在基础数据源发生更改时使缓存数据无效的最佳方法。如果基本产品信息发生变
-
PHP基于文件存储实现缓存的方法
本文向大家介绍PHP基于文件存储实现缓存的方法,包括了PHP基于文件存储实现缓存的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP基于文件存储实现缓存的方法。分享给大家供大家参考。具体如下: 在一些数据库数据记录较大,但是服务器有限的时候,可能一条MySQL查询就会好几百毫秒,一个简单的页面一般也有十几条查询,这个时候也个页面加载下来基本要好几秒了,如果并发量高的话服务器基本就瘫
-
在Redis缓存中存储多个版本的数据
我有一些需要在Redis缓存中存储多个版本的产品数据。数据是JSON序列化的。获取普通(基本)数据的过程是昂贵的,将其定制成不同版本的过程也是昂贵的,因此我希望缓存所有版本以尽可能优化。假设定制是基于一个参数的,我可以使用该参数作为缓存键的一部分。 我计划用于检索产品数据的过程如下所示: 所有这些工作都很好,但我现在正在尝试找出当底层数据源更改时使缓存数据无效的最佳方法。如果基本产品信息发生变化,
-
将对象保存在缓存中的最佳实践
null 将整个object1作为完整的JSON存储在my key下。 将object2与它自己的键一起存储在我的object1序列化中,以将object2键作为引用,并且当从缓存中拉回时,也通过它的键拉出object2。 我觉得选项1是最好的实践,也是最有效的,但我有第二个想法,将大的嵌套对象存储在on键下。
-
Spark SQL:“order by”提高了缓存内存占用率
我有两个场景,其中我有分区 中,读取的输入数据为6.2 GB,缓存的对象为15.1 GB。 案例1: 从 读取的输入数据为 6.2 GB,缓存的对象为 5.5 GB。 对此行为有任何解释或代码参考吗?
-
如何使服务工作者从API缓存数据,并在需要时更新缓存
我将React应用程序转换为PWA,它的工作部分正常。 我遵循了本教程:https://medium.com/@toricpope/transform-a-react-app-to-a-progressive-web-app-pwa-dea336bd96e6 然而,本文只展示了如何缓存静态数据,我还需要存储来自服务器的数据,我可以按照本文第一个答案的说明来做:如何将API中的数据缓存到React
-
Docker如何知道在构建期间何时使用缓存,何时不使用缓存?
问题内容: 我对Docker的层缓存表现出色感到惊讶,但我也想知道它如何确定是否可以使用缓存的层。 让我们以这些构建步骤为例: 例如,它如何知道可以使用缓存的层,但可以为其创建新层呢? 问题答案: 在Dockerfile最佳实践构建缓存部分中相当详尽地解释了构建缓存过程。 * 从缓存中已存在的基本映像开始,将下一条指令与从该基本映像派生的所有子映像进行比较,以查看是否其中一个是使用完全相同的指令构
-
基于Spring boot的REST服务,使用hazelcast的Spring缓存无法处理缓存错误
我使用Spring boot和hazelcast作为我的REST缓存服务。 我在服务层(API)使用带有自定义密钥生成器的spring@cacable注释进行缓存。除了从自定义键生成器函数中抛出RuntimeException之外,其他一切都可以正常工作,它不是由我添加到处理错误场景中的自定义错误类处理的。 扩展组织的自定义错误类(CacheErrorHandler)。springframewor