《缓存穿透》专题
-
redis - 从业务层面理解缓存穿透、缓存击穿、缓存雪崩?
最近在学redis的缓存击穿、缓存穿透和缓存雪崩,由于没有接触过实际业务场景,只明白概念,故希望有大佬可以从业务层面给予详解 ps:尤其是缓存穿透,我看网上大部分说的都是黑客攻击,我想知道,不考虑网络安全的情况下,在正常的业务场景中是否也会出现缓存击穿,希望可以通过业务场景进行解答
-
 Redis的缓存穿透、缓存雪崩、缓存击穿问题的概念与解决办法
Redis的缓存穿透、缓存雪崩、缓存击穿问题的概念与解决办法主要内容:1 缓存穿透,1.1 什么是缓存穿透?,1.2 怎么解决,1.3 Bloom Filter布隆过滤器,2 缓存雪崩,3 缓存击穿,4 缓存预热,5 防止Redis宕机详细介绍了Redis的缓存穿透、缓存雪崩、缓存击穿等问题的概念与解决办法。 1 缓存穿透 1.1 什么是缓存穿透? 缓存穿透是指查询一个在缓存和数据库中一定不存在的数据,按照传统使用缓存流程:由于缓存不命中,接着查询数据库,但是数据库也无法查询出结果,因此也不会将空值写入到缓存中,这将会导致每个这样的查询都会去请求数据库,
-
如何解决 Redis 缓存穿透和缓存雪崩问题?
本文向大家介绍如何解决 Redis 缓存穿透和缓存雪崩问题?相关面试题,主要包含被问及如何解决 Redis 缓存穿透和缓存雪崩问题?时的应答技巧和注意事项,需要的朋友参考一下 缓存雪崩: 由于缓存层承载着大量请求,有效地 保护了存储层,但是如果缓存层由于某些原因不能提供服务,比如 Redis 节点挂掉了,热点 key 全部失效了,在这些情况下,所有的请求都会直接请求到数据库,可能会造成数据库宕机的
-
 Redis缓存穿透和缓存雪崩以及解决方法
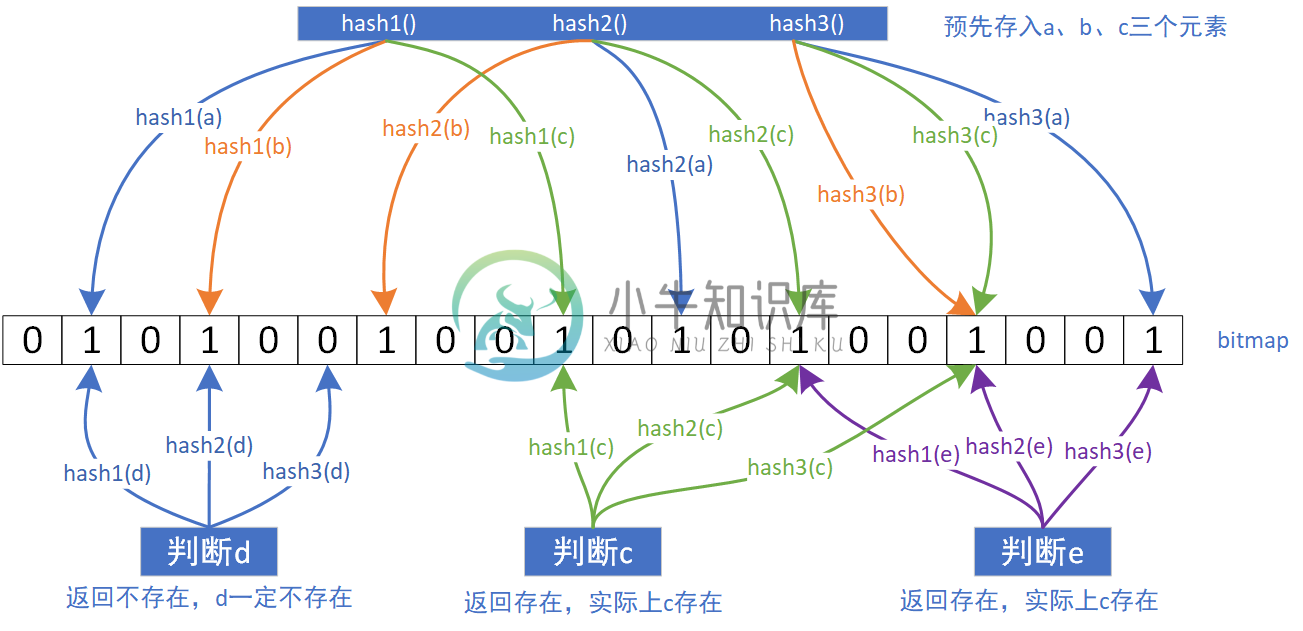
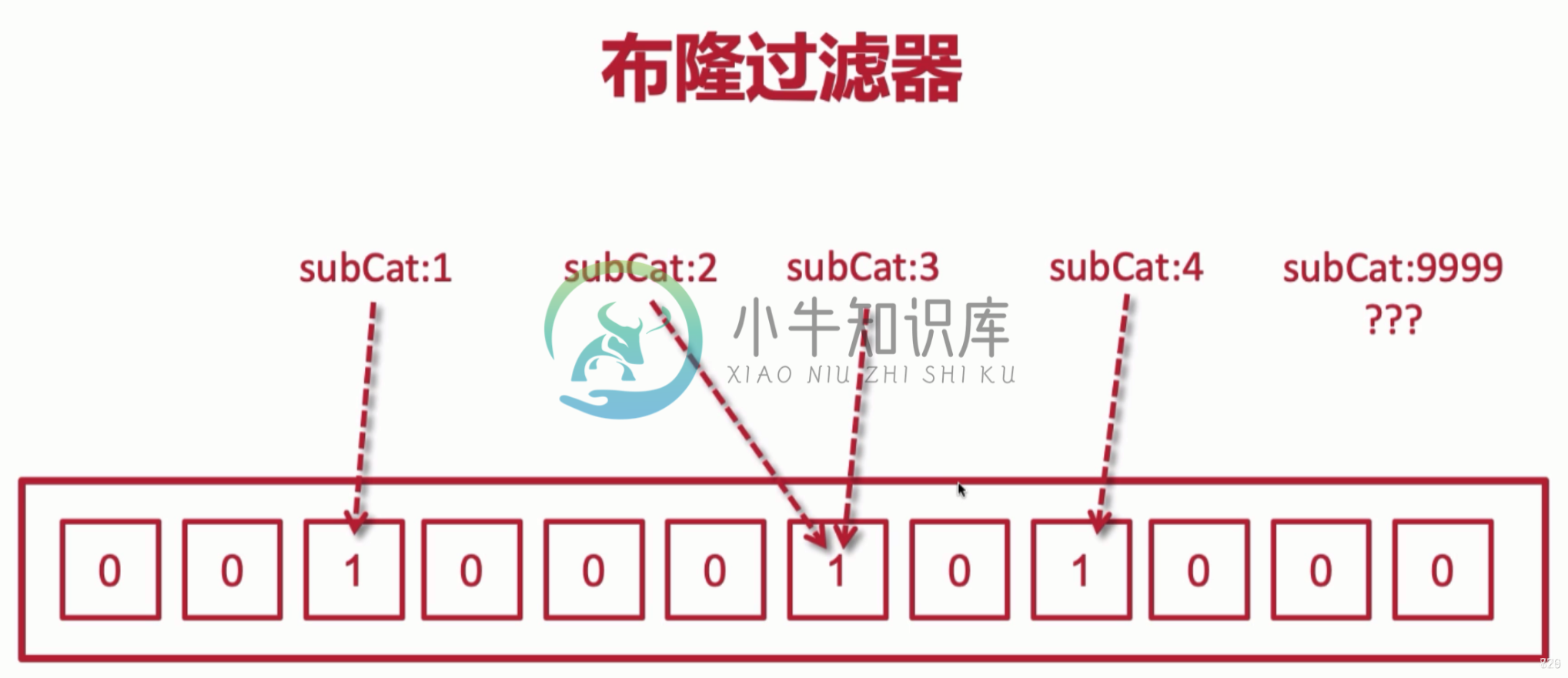
Redis缓存穿透和缓存雪崩以及解决方法Redis缓存穿透以及解决方法 一、缓存穿透 1.当用户查询的key在redis中不存在,对应的id在数据库也不存在,此时被非法用户进行攻击,大量的请求会直接打在db上,造成宕机,从而影响整个系统,这种现象称之为缓存穿透。 2.解决方案一:把空的数据也缓存起来,比如空字符串,空对象,空数组或list,代码如下 3.解决方案二:布隆过滤器 布隆过滤器:判断一个元素是否在一个数组里面,如下图,利用二进
-
什么是缓存穿透?怎么解决?
1、缓存穿透 一般的缓存系统,都是按照key去缓存查询,如果不存在对用的value,就应该去后端系统查找(比如DB数据库)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。 2、怎么解决? 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。 对一定不存在的key进行过滤。可以把所有的可能存在的
-
Redis,什么是缓存穿透?怎么解决?
1、缓存穿透 一般的缓存系统,都是按照key去缓存查询,如果不存在对用的value,就应该去后端系统查找(比如DB数据库)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。 2、怎么解决? 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。 对一定不存在的key进行过滤。可以把所有的可能存在的
-
java - Redis 如何有效防止缓存穿透、击穿和雪崩问题?
Redis怎么解决缓存穿透、击穿、雪崩 想看看大佬是怎么解决的
-
什么是缓存穿透?有哪些解决办法?
本文向大家介绍什么是缓存穿透?有哪些解决办法?相关面试题,主要包含被问及什么是缓存穿透?有哪些解决办法?时的应答技巧和注意事项,需要的朋友参考一下 缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。 解决方案:最简单粗暴的方法如果一个查询返回的数据为空(不管是数据不存在,还是系统故障)
-
缓存 - 二级缓存
当你使用本地(在内存中)缓存时,服务器可以缓存一些信息并快速地检索它,但是其他服务器不能访问这个缓存数据,他们需要到数据库中查询同样的信息。 如果你喜欢使用分布式缓存让其他服务器访问缓存的数据,由于它有一些序列化/反序列化和网络延迟开销,则需要注意:在某些情况下,它可能会降低性能。 缓存需要处理的另一个问题:缓存失效。 There are only two hard things in Compu
-
缓存 - 本地缓存
Serenity 提供一些缓存抽象和实用功能让你更容易地使用本地缓存。 术语 本地(local) 的意思是指在本地内存中缓存项目(因此没有涉及到序列化)。 当你的应用程序在网站群(web farm) 中部署时,本地缓存可能还不够或者有时合适。我们将在 分布式缓存 章节中讨论该场景。
-
缓存 - 分布式缓存
Web 应用程序可能需要为成百上千甚至更多的用户同时提供服务。如果你没有采取必要的措施,在这种负载下,你的网站可能会崩溃或变得没有响应。 假设在主页显示最后 10 条新闻,并且平均每分钟有上千名用户访问此页面。你可能为每个用户通过查询数据库来显示页面视图信息: SELECT TOP 10 Title, NewsDate, Subject, Body FROM News ORDER BY NewsD
-
缓存
一个动态网站的基本权衡点就是,它是动态的。 每次用户请求一个页面,Web服务器将进行所有涵盖数据库查询到模版渲染到业务逻辑的请求,用来创建浏览者需要的页面。从开销处理的角度来看,这比你读取一个现成的标准文件的代价要昂贵的多。 对于大多数网络应用程序,这个开销不是很大的问题。我们的应用不是washingtonpost.com or slashdot.org; 他们只是中小型网站,而且只有那么些流量而
-
缓存
缓存的原则 缓存是一个大型系统中非常重要的一个组成部分。在硬件层面,大部分的计算机硬件都会用缓存来提高速度,比如 CPU 会有多级缓存、RAID 卡也有读写缓存。在软件层面,我们用的数据库就是一个缓存设计非常好的例子,在 SQL 语句的优化、索引设计、磁盘读写的各个地方,都有缓存,建议大家在设计自己的缓存之前,先去了解下 MySQL 里面的各种缓存机制,感兴趣的可以去看下High Performa
-
缓存
缓存是现代高并发应用程序的重要组成部分。即使你的 web 应用程序目前还没有那么高的并发量,但在之后的发展中极有可能会遇到高并发的应用场景,因此从一开始就使用缓存设计程序是一个好主意。 本地缓存 分布式缓存 二级缓存
-
缓存
一、缓存特征 二、缓存位置 三、CDN 四、缓存问题 五、数据分布 六、一致性哈希 七、LRU 参考资料 一、缓存特征 命中率 当某个请求能够通过访问缓存而得到响应时,称为缓存命中。 缓存命中率越高,缓存的利用率也就越高。 最大空间 缓存通常位于内存中,内存的空间通常比磁盘空间小的多,因此缓存的最大空间不可能非常大。 当缓存存放的数据量超过最大空间时,就需要淘汰部分数据来存放新到达的数据。 淘汰策