《持久化》专题
-
持久化
Akka持久化使有状态的actor能留存其内部状态,以便在因JVM崩溃、监管者引起,或在集群中迁移导致的actor启动、重启时恢复它。Akka持久化背后的关键概念是持久化的只是一个actor的内部状态的的变化,而不是直接持久化其当前状态 (除了可选的快照)。这些更改永远只能被附加到存储,没什么是可变的,这使得高事务处理率和高效复制成为可能。有状态actor通过重放保存的变化来恢复,从而使它们可以重
-
JMS持久订户持久消息不会持久化到数据库
我正在使用网络逻辑10.3。我正在尝试配置一个持久订阅,其中包含由 jdbc 存储(在 Oracle DB 中)支持的持久消息。我有一个主题,MDB 正在作为持久订阅者侦听该主题。在场景-1下:如果我发送消息,它会命中MDB。 在场景2中:我挂起了MDB,希望发送到主题的消息只要不被MDB(它是唯一注册的持久订阅者)使用,就会一直存在。但是当我向主题发送消息时,它短暂地出现在那里,然后就消失了(我
-
RDD持久化
Spark通过在操作中将其持久保存在内存中,提供了一种处理数据集的便捷方式。在持久化RDD的同时,每个节点都存储它在内存中计算的任何分区。也可以在该数据集的其他任务中重用它们。 我们可以使用或方法来标记要保留的RDD。Spark的缓存是容错的。在任何情况下,如果RDD的分区丢失,它将使用最初创建它的转换自动重新计算。 存在可用于存储持久RDD的不同存储级别。通过将对象(Scala,Java,Pyt
-
Redis 持久化
Redis 支持持久化,即把数据存储到硬盘中。 Redis 提供了两种持久化方式: RDB 快照(snapshot) - 将存在于某一时刻的所有数据都写入到硬盘中。 只追加文件(append-only file,AOF) - 它会在执行写命令时,将被执行的写命令复制到硬盘中。 这两种持久化方式既可以同时使用,也可以单独使用。 将内存中的数据存储到硬盘的一个主要原因是为了在之后重用数据,或者是为了防
-
4.2 持久化
不要害怕文件系统! Kafka 对消息的存储和缓存严重依赖于文件系统。人们对于“磁盘速度慢”的普遍印象,使得人们对于持久化的架构能够提供强有力的性能产生怀疑。事实上,磁盘的速度比人们预期的要慢的多,也快得多,这取决于人们使用磁盘的方式。而且设计合理的磁盘结构通常可以和网络一样快。 关于磁盘性能的关键事实是,磁盘的吞吐量和过去十年里磁盘的寻址延迟不同。因此,使用6个7200rpm、SATA接口、RA
-
RDD 持久化
Spark 有一个最重要的功能是在内存中_持久化_ (或 缓存)一个数据集。
-
RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中。当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些 数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互使用来说,缓存是一个关键的工具。 你能通过persi
-
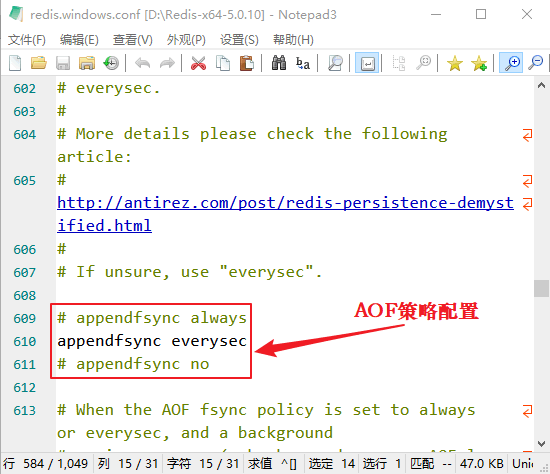 Redis AOF持久化
Redis AOF持久化主要内容:开启AOF持久化,AOF持久化机制,AOF策略配置,AOF和RDB对比AOF 被称为追加模式,或日志模式,是 Redis 提供的另一种持久化策略,它能够存储 Redis 服务器已经执行过的的命令,并且只记录对内存有过修改的命令,这种数据记录方法,被叫做“增量复制”,其默认存储文件为 。 开启AOF持久化 AOF 机制默认处于未开启状态,可以通过修改 Redis 配置文件开启 AOF,如下所示: 1) Windows系统 执行如下操作: 2) Linux系统 执行如下
-
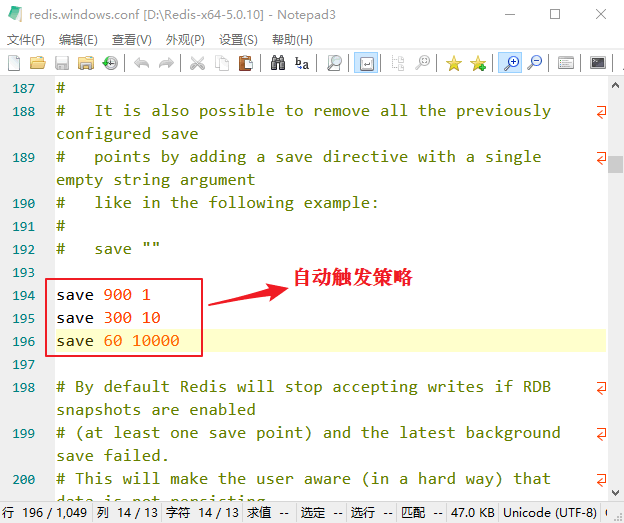 Redis RDB持久化
Redis RDB持久化主要内容:RDB快照模式原理,RDB持久化触发策略,RDB持久化优劣势Redis 是一款基于内存的非关系型数据库,它会将数据全部存储在内存中。但是如果 Redis 服务器出现某些意外情况,比如宕机或者断电等,那么内存中的数据就会全部丢失。因此必须有一种机制能够保证 Redis 储存的数据不会因故障而丢失,这就是 Redis 的数据持久化机制。 数据的持久化存储是 Redis 的重要特性之一,它能够将内存中的数据保存到本地磁盘中,实现对数据的持久存储。这样即使在服务器
-
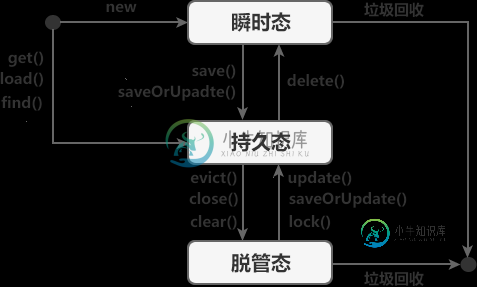 Hibernate持久化类
Hibernate持久化类持久化类(Persistent Object )简称 PO,在 Hibernate 中, PO 是由 POJO(即 java 类或实体类)和 hbm 映射配置组成。 简单点说,持久化类本质上就是一个与数据库表建立了映射关系的普通 Java 类(实体类),例如 User 类与数据库中 user 表通过映射文件 User.hbm.xml 建立了映射关系,此时 User 就是一个持久化类。 持久化类的规
-
EOS 持久化API
C++ API eosio::multi_index 本节介绍eosio::multi_index C ++ API。 该接口实际上是 Boost Multi-Index 容器库的改编版本。 它直接使用boost/multi_index/const_mem_fun类模板进行密钥提取。 它还使用 Boost Hana 库进行元编程。 有关其他概念信息和详细信息,请参阅 www.boost.org 上
-
1.6 持久化(persistence)
Note 本文档翻译自 http://redis.io/topics/persistence 。 这篇文章提供了 Redis 持久化的技术性描述, 推荐所有 Redis 用户阅读。 要更广泛地了解 Redis 持久化, 以及这种持久化所保证的耐久性(durability), 请参考文章 Redis persistence demystified (中文)。 Redis 持久化 Redis 提供了多
-
持久性(Persistence)
EJB 3.0,EJB 2.0中使用的实体bean在很大程度上被持久性机制所取代。 现在,实体bean是一个简单的POJO,它具有与表的映射。 以下是持久性API中的关键角色 - Entity - 表示数据存储记录的持久对象。 可序列化是件好事。 EntityManager - 持久性接口,用于对持久对象(实体)执行添加/删除/更新/查找等数据操作。 它还有助于使用Query接口执行查询。 Per
-
Redis的持久化机制详解—RDB与AOF持久化
主要内容:1 数据持久化,2 RDB(Redis DataBase)快照,2.1 RDB的原理,2.1 RDB的优缺点,2 AOF(append-only file)追加,2.1 AOF的原理,2.2 AOF重写,2.3 AOF的优缺点,3 混合持久化策略详细介绍了Redis的持久化机制,包括RDB与AOF持久化,以及混合持久化。 1 数据持久化 为了重启机器、机器故障、系统故障之后恢复数据,将内存中的数据写入到硬盘里面,这就是持久化,Redis恰好支持数据的持久化,这也是相比于Memcache
-
JPA级联持久化
主要内容:JPA级联持久化示例,输出结果级联持久化用于指定如果实体持久化,则其所有关联的子实体也将被持久化。 以下语法用于执行级联持久性操作 - JPA级联持久化示例 在这个例子中,我们将创建两个相互关联的实体类,但要建立它们之间的依赖关系,我们将执行级联操作。 这个例子包含以下步骤 - 第1步: 在包下创建一个名为的实体类,其中包含属性:,,以及标记为级联规范的类型的对象。 文件: StudentEntity.java - 第2步: