《流程》专题
-
增加内存流容量
我试图从SSRS服务器读取报告,问题是我的内存流不能超过65536字节。 到目前为止,我已经尝试过使用内存流,但尚未成功设置其容量,然后再阅读报告本身 上面的MemoryStream必须在我读取文件之前增加它的容量。 我试过在我的应用程序中玩。配置,但我不知道从哪里开始设置内存流的字节容量
-
火花流口水-性能
我在Scala/Spark中有一个批处理作业,它根据一些输入动态创建Drools规则,然后评估规则。我还有一个与要插入到规则引擎的事实相对应的输入。 到目前为止,我正在一个接一个地插入事实,然后触发关于这个事实的所有规则。我正在使用执行此操作。 seqOp运算符的定义如下: 以下是生成的规则的示例: 对于同一RDD,该批次花了20分钟来评估3K规则,但花了10小时来评估10K规则! 我想知道根据事
-
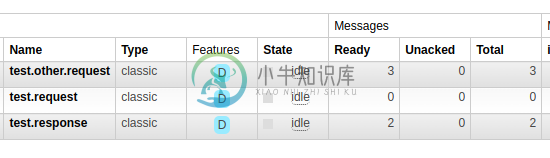 Spring云流:StreamBridge和事务
Spring云流:StreamBridge和事务我希望有一个Spring云流侦听器处理有关其中发送的所有消息的完整事务。或者,即使之后有异常,也会提交函数中使用StreamBridge手动发送的所有消息。 这是我的lib版本: 我的Spring云流形态: 我的测试java代码: 要运行的测试类: 我还添加了TransactionManager: 在最后的这个示例中,我的兔子队列中有: 或者我应该只有两条消息test.other.request.
-
GRPC异步响应流C#
如何从处理程序外部为RPC生成流响应值?(特别是,从I观察者)我目前正在执行以下操作,但这会产生跨线程问题,因为在RPC处理程序之间共享... 这段代码感觉不对劲...但是我看不到从RPC处理程序之外创建的共享源流式传输RPC响应的任何其他方式。
-
JavagRPC服务器流模型
我正在通过以下示例寻找一个用于服务器端流的客户端侦听器示例-https://grpc.io/docs/languages/java/basics/ 我已经按照文档-https://github.com/grpc/grpc/blob/master/doc/keepalive.md 所有的例子都表明,当向服务器发出请求时,服务器将作为异步或一元模型响应,或者客户端可以与新请求聊天。每次请求都必须发送到
-
每个数组流的AssertEquals
我有一个自定义对象数组。我想循环遍历每个元素,并检查该自定义对象类型为String的特定字段。我想断言等于预期值的值。但是我不能准备这份声明。请帮忙。 我的代码:
-
连续合并和blob流
在我的代码(Javascript)中,我使用了套接字。io将base64数据从代理传输到客户端,以建立视频通话功能。为此,每5秒或10秒,我将使用mediaRecorder录制视频,并将其发送到base64中的客户端,该客户端将每10秒转换为blob。 问题:所以,我想知道我可以在每10秒合并一个新的Blob,同时播放视频吗? 我已经尝试使用createObjectURL(blob),但这不起作用
-
Drools流模式负模式
我对Drools中的流模式有一个问题。我在用这个规则 如果我发送MetaMessage,我希望规则在指定的10秒后执行,但不会附加任何内容。如果我发送新的MetaMessage,10秒后,规则将执行。 编辑:如果我改变规则并去掉not,它就像一个符咒 我不知道我做错了什么。 这就是我创建KieBase的方式 编辑2每次在Kafka队列中插入新的元消息时,我都会使用fireAllRules()触发规
-
与熊猫一起漂流
我正在读一个带有如下浮点数的CSV: 并导入到数据框中,然后将此数据框写入新位置 现在,此
-
JavaScript中的简单节流
我正在寻找一个简单的JavaScript节流阀。我知道像lodash和下划线这样的库都有它,但只有一个函数包含这些库中的任何一个都是多余的。 我还检查了jQuery是否有类似的函数-找不到。 我发现了一个工作油门,下面是代码: 这样做的问题是:在油门时间完成后,它会再次触发该功能。所以让我们假设我做了一个油门,每10秒在键盘上按下一次——如果我按下2次键盘,当10秒完成时,它仍然会按下第二个键盘。
-
持续火花流输出
我正在从一个消息应用程序收集数据,我目前正在使用Flume,它每天发送大约5000万条记录 我希望使用Kafka,使用Spark Streaming从Kafka消费并将其持久化到hadoop并使用impala进行查询 我尝试的每种方法都有问题。。 方法1-将RDD另存为parquet,将外部配置单元parquet表指向parquet目录 问题是finalParquet.saveAsParquetF
-
Spring云流配置选项
大家好,我完全是Spring Cloud Streams框架的新手。 在用于Kafka Streams的spring cloud stream文档中,我可以看到在示例中使用的应用程序yaml/properties文件中引用了前缀为spring.cloud.stream.function.definition等的属性。 我知道Cloud streams使用Cloud函数,但是Cloud stream
-
Spring云流内部通道
我开始开发一个spring cloud stream项目。我已通过@Streamlistener注释成功接收到来自Kafka的消息。在将消息发送到任何输出通道之前,我必须通过调用externalservice或DB调用来转换有效负载。我不想从同一个streamlistener方法调用外部服务或DB方法。我的问题是,我们能否在Spring云流中创建内部通道(如Spring集成DSL流)?
-
Apache Flink中的流预测
是否可以在Apache Flink中使用已经成批训练的模型对dataStream进行预测? 支持向量机的预测功能需要一个数据集作为输入,而不需要一个数据集。 不幸的是,我不知道如何使用FlatpMap/Map函数使其工作。 我是这样训练SVM模型的: val svm2=SVM() svm2.setseed(1) svm2.fit(trainLV) val testVD=testlv.map(lv=
-
优化java 8流操作
我在这里使用的所有方法几乎都是O(1)复杂度,比较器也不太费力,所以这不应该是问题,有什么我可能不知道的东西可以帮助我优化这个流操作吗?也许我用的入口集可以避免...?因为这可能是这里最贵的手术... 编辑1:也许我应该解释一下这个方法背后的想法。它的主要目的是对地图aux进行排序,并返回一个带有排序键的列表(键也被修改了,但这不是主要目的)