《lambda》专题
-
我可以从多个SQS触发相同的AWS lambda吗?
我想从多个SQS队列中触发一个lambda函数。lambda将进行的大部分处理都是相同的,只是一个小步骤将基于表名。我不想为此保留两个单独的lambda。拥有相同/多个lambda的利弊是什么?
-
AWS lambda函数对具有相同时间戳的同一事件多次触发
我将AWS S3触发器配置为带有PUT操作的lambda函数。 每2分钟上载100KB大小的.txt文件。 有时S3会以相同的事件和时间触发lambda两次。 触发器1: 触发器2: 我怎样才能避免这种情况呢?
-
带触发器的AWS Lambda创建函数
我可以从AWS SDK创建lambda函数: 但是我如何指定这个函数应该在S3上传时触发呢?
-
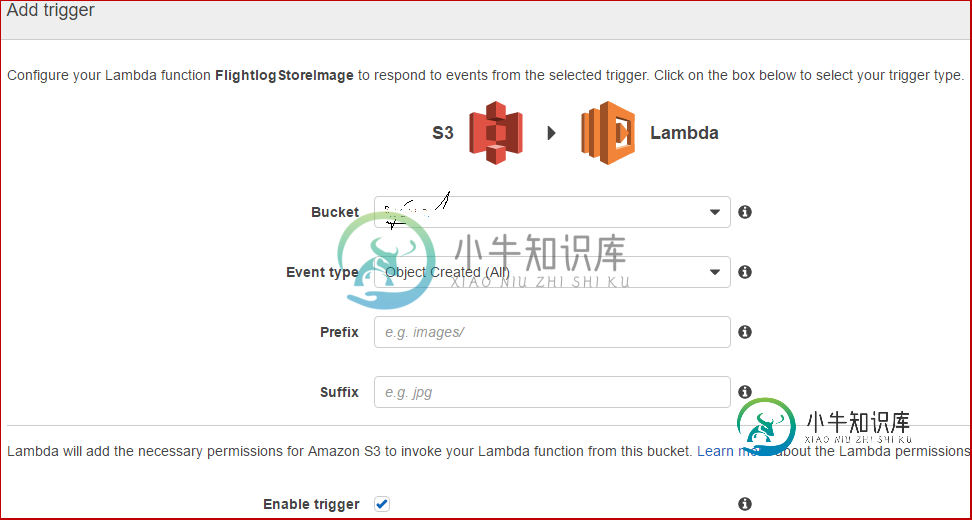 如何使用AWS CLI向AWS Lambda函数添加触发器?
如何使用AWS CLI向AWS Lambda函数添加触发器? -
aws lambda函数从s3获取getObject时访问被拒绝
我在Lambda函数上收到来自S3 AWS服务的acccess denied错误。 这是代码: 这是CloudWatch上的错误: 这是堆栈错误: 没有关于S3的任何其他描述或信息,桶权限允许每个人、放置、列表和删除。 我可以做什么来访问S3桶? PS:在Lambda事件属性上,主体是正确的,并且具有管理特权。
-
aws lambda函数为单个事件多次触发
我正在使用aws lambda函数将一个桶中上传的wav文件转换为mp3格式,然后将文件移动到另一个桶中。它工作正常。但触发有个问题。当我上传小的wav文件时,lambda函数被调用一次。但是当我上传一个大尺寸的wav文件时,这个功能会被触发多次。 我已经谷歌了这个问题,发现它是无状态的,所以它会被多次调用(不确定这个触发器是针对多次上传还是同一个上传)。 https://aws.amazon.c
-
如何使用lambda函数从AWS3获取文本文件的内容?
我想知道是否可以为AWS设置一个lambda函数,每当一个新的文本文件上传到s3 bucket时就会触发这个函数。在函数中,我想获取文本文件的内容,并以某种方式对其进行处理。我在想这有没有可能...? 例如,如果我上传了foo.txt,内容为foobarbaz,我希望在lambda函数中使用foobarbaz,这样我就可以用它来做一些事情。我知道我可以从getObject获取元数据,或者类似的方法
-
如何将Haskell编译成非类型化的lambda演算(或GHC核)?
-
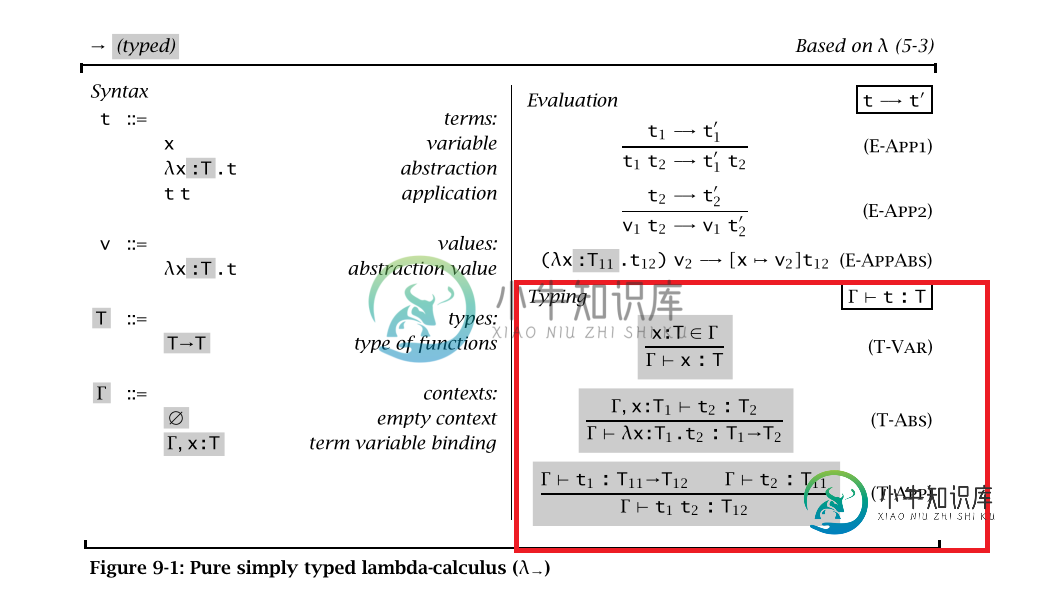 Haskell用于Lambda演算,类型推断
Haskell用于Lambda演算,类型推断我在Haskell编程中的冒险并不都是史诗般的。我正在实现简单的Lambda演算,我很高兴完成了、以及,希望它们是正确的。剩下的是,就像红色框中定义的那样(在下图中),我正在为此寻找指导。 如果我说错了请指正, (1)但是我发现返回给定变量的类型。Haskell中的什么构造返回?我知道在中是,但我正在寻找一个在下工作的。 (3)对于(T-APP)和(T-ABS),我假设我分别对和应用程序应用了替换
-
用java8 lambda函数替换All
给定以下变量 我想使用以下代码将占位符${name}替换为值“joe”(这不起作用) 但是,如果我按照“老式”的方式来做,一切都运行得很完美: )我一定漏了点什么
-
在哪里标记 lambda 表达式异步?
我有这个代码: ……Resharper的检查抱怨道,“因为没有等待此调用,所以在调用完成之前继续执行当前方法。请考虑将‘wait’运算符应用于调用结果”(在注释行)。 所以,我在它前面加了一个“等待”,但当然,我也需要在某个地方加一个“异步”——但在哪里呢?
-
从文法中生成随机术语(简单类型化的lambda演算)
我的第二个问题是,我知道有许多可用于Java和Python等语言的基准测试,但我试图为lambda演算寻找类似的基准测试,但没有找到任何东西。是否有机会为STLC或非类型化的lambda演算提供基准测试?
-
Lambda演算Haskell的Beta转换
其中是用于定义替换的函数。 然而,当我试图使用beta约简来约简表达式时,我得到了一个非穷举模式错误,我不明白为什么。我能做的修复它是在底部添加一个额外的大小写,如下所示: 但是,如果我这样做了,那么lambda表达式根本不会被缩减,这意味着函数的输入和输出是相同的。 如果使用第一个函数而不添加最后一个大小写,则为非穷尽模式 或完全相同的表达式App(ABS1(ABS2(VAR1)))(VAR3)
-
为什么 LambdaMetafactory 在使用自定义函数接口时会失败(但函数工作正常)?
鉴于: 为什么和工作,而抛出以下异常? java.lang.AbstractMethodError:接收器类test case $ $ Lambda $ 233/0x 0000000800d 21d 88未定义或继承接口MyBuilder1的已解析方法“abstract Java . lang . object apply(Java . lang . string)”的实现。 假设构造函数接受一个
-
从LambdaMetafactory创建BiConsumer
我正在尝试通过LambdaMetafactory动态创建BiConsumer类型的方法引用。我试图应用 https://www.cuba-platform.com/blog/think-twice-before-using-reflection/ 上的两种方法 - createVoidHandlerLambda和这里的Create BiConsumer作为字段设置器,而不反映Holger的答案。