《hbase》专题
-
相关软件介绍/HBase/HBase简述
一、定义 1、该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。 2、HBase是一个分布式的、面向列的开源数据库。 3、HBase在Hadoop之上提供了类似于Bigtable的能力。 4、HBase是Apache的Hadoop项目的子项目。 二、HBase与关系型数据库的区别 1、HBase是一个适合于非结构化数据存储的数据库。 2
-
HBase的 SQL 中间层 —— Phoenix
一、Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可
-
HBase 容灾与备份
一、前言 本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable、Export/Import、Snapshot。分别介绍如下: 二、CopyTable 2.1 简介 CopyTable可以将现有表的数据复制到新表中,具有以下特点: 支持时间区间 、row 区间 、改变表名称 、改变列族名称 、以及是否 Copy 已被删除的数据等功能; 执行命令前,需先创建与原表结构相同的新表
-
HBase 协处理器详解
一、简述 在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求。在这种情况下,协处理器(Coprocessors)应运而生。它允许你将业务计算代码放入在 RegionServer 的协处理器中,将处理好的数据再返回给客户端,这可以极大地降低需要传输的数据量,从而获得性能上的提升。同时
-
HBase 过滤器详解
一、HBase过滤器简介 Hbase 提供了种类丰富的过滤器(filter)来提高数据处理的效率,用户可以通过内置或自定义的过滤器来对数据进行过滤,所有的过滤器都在服务端生效,即谓词下推(predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端,从而减轻网络传输和客户端处理的压力。 二、过滤器基础 2.1 Filter接口和FilterBase抽象类 Filter 接口
-
HBase Java API
一、简述 截至到目前 (2019.04),HBase 有两个主要的版本,分别是 1.x 和 2.x ,两个版本的 Java API 有所不同,1.x 中某些方法在 2.x 中被标识为 @deprecated 过时。所以下面关于 API 的样例,我会分别给出 1.x 和 2.x 两个版本。完整的代码见本仓库: Java API 1.x Examples Java API 2.x Examples 同
-
HBase 常用 Shell 命令
一、基本命令 打开 Hbase Shell: # hbase shell 1.1 获取帮助 # 获取帮助 help # 获取命令的详细信息 help 'status' 1.2 查看服务器状态 status 1.3 查看版本信息 version 二、关于表的操作 2.1 查看所有表 list 2.2 创建表 命令格式: create '表名称', '列族名称 1','列族名称 2','列名
-
HBase 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Regin Server。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。 二、前置条件
-
HBase 基本环境搭建 (Standalone /pseudo-distributed mode)
一、安装前置条件说明 1.1 JDK版本说明 HBase 需要依赖 JDK 环境,同时 HBase 2.0+ 以上版本不再支持 JDK 1.7 ,需要安装 JDK 1.8+ 。JDK 安装方式见本仓库: Linux 环境下 JDK 安装 1.2 Standalone模式和伪集群模式的区别 在 Standalone 模式下,所有守护进程都运行在一个 jvm 进程/实例中; 在伪分布模式下,HBase
-
HBase 系统架构及数据结构
一、基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键。想要访问 HBase Table 中的数据,只有以下三种方式: 通过指定的 Row Key 进行访问; 通过 Row Key 的 range 进行访问,即访问指定范围内的行; 进行全表扫描。 Row Key 可以是任意字符串,存储时数据按照 Row Key 的字典序进
-
Hbase 简介
一、Hadoop的局限 HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。 要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。 但是 Hado
-
Storm 集成 HDFS/HBase
一、Storm集成HDFS 1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用 <repository> 标签指定 CDH 的仓库地址; hadoop-common、hadoop-client、
-
Hive和HBase之间的区别
本文向大家介绍Hive和HBase之间的区别,包括了Hive和HBase之间的区别的使用技巧和注意事项,需要的朋友参考一下 Apache Hive和HBase都是基于Hadoop的大数据技术,它们基本上具有相同的查询大数据的目的。但是,Apache Hive和HBase都在Hadoop之上运行,但它们的功能有所不同。 但是基于功能,我们可以如下区分Hive和HBase- 序号 键 蜂巢 HBase
-
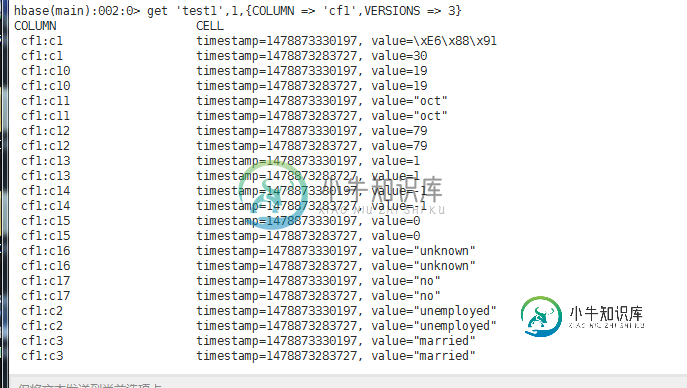 通用MapReduce程序复制HBase表数据
通用MapReduce程序复制HBase表数据本文向大家介绍通用MapReduce程序复制HBase表数据,包括了通用MapReduce程序复制HBase表数据的使用技巧和注意事项,需要的朋友参考一下 编写MR程序,让其可以适合大部分的HBase表数据导入到HBase表数据。其中包括可以设置版本数、可以设置输入表的列导入设置(选取其中某几列)、可以设置输出表的列导出设置(选取其中某几列)。 原始表test1数据如下: 每个row key都有两
-
RDBMS和HBase之间的区别
本文向大家介绍RDBMS和HBase之间的区别,包括了RDBMS和HBase之间的区别的使用技巧和注意事项,需要的朋友参考一下 RDBMS和HBase都是数据库管理系统。RDBMS使用表来表示数据及其关系。HBase是面向列的dbms,它在Hadoop分布式文件系统(HDFS)之上运行。 以下是RDBMS与HBase之间的重要区别。 序号 键 关系数据库管理系统 HBase的 1个 定义 HBas