《并查集》专题
-
Sql Server忽略varchar列上的索引,并在从Java查询时进行表扫描
问题:我有一个SQL Server表,有一个varchar列和数百万行,它被索引。在SQL Server查询工具中运行查询很快,因为它使用索引。当我从JavaJDBCPreparedStatement运行查询时,需要花费很多分钟,调查显示SQLServer会进行表扫描。如何解决此问题?
-
Python 正则表达式查找 HTML 标签并将其替换为特定属性值
我正在尝试用python编写一个正则表达式,它可以找到src属性等于特定值的所有img标签..我试着写下面的 下面是我得到的输出
-
正则表达式查找子字符串并将其包装在标记中-Java[duplicate]
我正在尝试编写一个代码,它可以找到以下格式的所有单词 在“symbols”中的字母数字字符,以:symbols结尾。我的目标是,一旦找到这些字符,就去掉“字符,并将整个字符串包装在标记中。因此在代码运行之后,上面的文本将如下所示, 所以我认为查找此类文本以进行包装的正则表达式如下所示(为Java格式), 通过使用下面的代码,我应该能够迭代所有的匹配。 所以我可能做错了。 现在我已经用一个强标签包装
-
使用ArrayList查找并报告文件中最长单词出现的所有行号
该程序提供输入命令行参数,这些参数是文本文件的名称,并返回基本统计信息,如字符数、单词数和行数、平均字长、每个字母的数量和字长。 我有一切工作,除了这个:查找和报告使用数组列表跟踪行号文件中最长的单词出现的所有行号,因为我们不知道最长的单词有多少次出现。如果有两个或两个以上长度相同的单词,那么只跟踪第一个。我该怎么做呢?
-
如何检查arrayList中的项是否已经存在,并在Java中添加计数?
假设我有一个类,该类用于一个名为的数组列表。 项目的名称和数量将存储在此数组列表中。即将添加到此arrayList中的项目已存在,但数量不同。如何通过绕过现有名称的名称,只向现有名称添加数量来避免重复? 这是我的代码,我还没有完成:它应该从数据文件中读取 要求的所需经费; 作为程序输入的数据文件将由包含三个命令之一的行组成。第一个命令是add,后面跟着数量和商品名称,用逗号分隔。这将添加到购物清单
-
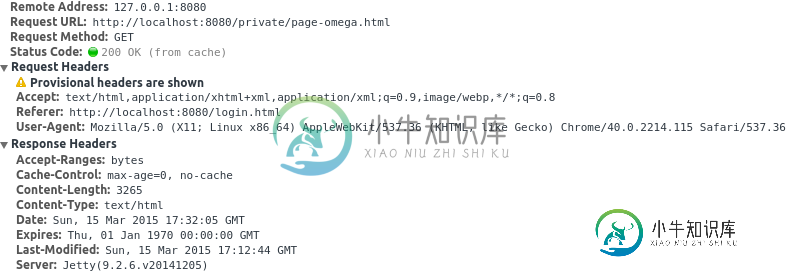 “cache-control:max-age=0,no-cache”但是浏览器绕过服务器查询(并命中cache)?
“cache-control:max-age=0,no-cache”但是浏览器绕过服务器查询(并命中cache)?我用的是Chrome40(所以一些漂亮和现代的东西)。 在所有页面上都设置了no-cache-所以我希望浏览器只在首先检查服务器并得到响应时才使用其缓存中的某些内容。 然而,在按下后退按钮时,浏览器会愉快地点击自己的缓存,而无需与服务器进行检查。 我认为我可以使用作为的一个轻量级替代方案,在这里我不希望用户通过后退按钮看到陈旧的数据(但是数据是无价值的,因此可以缓存)。 我对的理解是浏览器必须始终
-
检查列表是否包含包含字符串的元素并获取该元素
在寻找这个问题的答案时,我也遇到过类似的利用LINQ的方法,但是我还不能完全理解它们(并因此实现它们),因为我对它还不熟悉。基本上,我想说的是: 检查列表的任何元素是否包含特定字符串。 如果是,则获取该元素。 老实说,我不知道该如何着手做那件事。我能想出的是这个(当然不工作): 我知道为什么它不起作用: 不返回,因为它将检查列表的整个元素是否与我指定的字符串匹配 不会找到匹配项,因为它将再次检查与
-
查询,本机查询,命名查询和类型查询之间的区别
问题内容: 查询,本机查询,命名查询和类型查询之间有什么区别?“独立”查询是否存在,还是只是缩写?在我看来,本机查询是用简单sql编写的查询,而命名查询与实体(hibernate映射)有关。有人可以简要解释一下吗? 问题答案: 询问 查询是指JPQL / HQL查询,其语法类似于通常用于执行DML语句(CRUD操作)的SQL。 在JPA中,您可以使用创建查询。您可以查看API以获得更多详细信息。
-
 详解MySql基本查询、连接查询、子查询、正则表达查询
详解MySql基本查询、连接查询、子查询、正则表达查询本文向大家介绍详解MySql基本查询、连接查询、子查询、正则表达查询,包括了详解MySql基本查询、连接查询、子查询、正则表达查询的使用技巧和注意事项,需要的朋友参考一下 查询数据指从数据库中获取所需要的数据。查询数据是数据库操作中最常用,也是最重要的操作。用户可以根据自己对数据的需求,使用不同的查询方式。通过不同的查询方式,可以获得不同的数据。MySQL中是使用SELECT语句来查询数据的。在这
-
Java中ArrayList的交集和并集
问题内容: 有什么方法可以这样做吗?我一直在寻找,但找不到任何东西。 另一个问题:我需要这些方法,以便可以过滤文件。有些是AND过滤器,有些是OR过滤器(类似于集合论),因此我需要根据所有文件以及保存这些文件的unite / intersects ArrayLists进行过滤。 我是否应该使用其他数据结构来保存文件?还有其他什么可以提供更好的运行时间吗? 问题答案: 这是不使用任何第三方库的简单实
-
SQL Server while循环并集全部
问题内容: 我正在尝试执行以下代码。这是我必须编写的实际代码的简化示例,因此我知道以这种方式循环是没有用的。但是,我需要在SQL Server中查找并合并select语句。当我尝试运行此查询时,出现错误: 关键字“ END”附近的语法不正确。 有任何想法吗? 问题答案: 您需要将第二组设置为UNION。while循环不会保留在选定的集合上,下次再知道它。您要完成的工作基本上是从mytable中选择
-
从集合中获取并行流
问题内容: 它是纠正与Java 8,你需要执行下面的代码确实获得从平行流Collection? 从CollectionAPI: 默认Stream parallelStream() 返回一个可能与此流作为其源的并行Stream。此方法允许返回顺序流。 从BaseStreamAPI: S parallel() 返回并行的等效流。可能由于流已经是并行的,或者因为基础流的状态被修改为并行而返回自身。 我需
-
从集合中获取并行流
在Java8中,您需要执行以下代码才能从中获得并行流,这是否正确? 来自API: 默认流parallelStream()
-
 并行压缩收集器算法
并行压缩收集器算法我有两个问题。其中一个会把话题弄得乱七八糟:) 1)我遇到了一个问题,即无法找到关于不同垃圾收集器在Hotspot中如何工作的完整信息。但我不是在谈论垃圾收集器工作的一般描述(我们在互联网上有很多这样的信息),我是在谈论具体的算法。我找到了这本白皮书(Java HotSpot虚拟机中的内存管理)http://www.oracle.com/technetwork/Java/javase/tech/m
-
提交内容并集成发布
DaoCloud 文档后台 DaoCloud 文档采用 Grav CMS,内容通过 Markdown 格式写作,并在 GitHub 上完成版本管理、协作开发等工作。 创建本地环境 下载 Grav 主程序 把 ZIP 包解压缩到您的 weboot 目录, (例如 ~/www/grav-core/) 下载 并解压缩,或者直接克隆, 把 daocloud-docs 覆盖 grav-core 的 user