《搜索树》专题
-
YouTube API 搜索中缺少结果
我正在调用YouTube API,截至上周,它不再始终如一地在特定频道上查找最新发布的视频。 我正在使用文档中实际的“尝试这个API”窗口(这里有一个已经输入参数的链接): https://developers.google.com/youtube/v3/docs/search/list?apix_params={"part":"snippet "," channelId ":" uci8e 0
-
YouTubeAPI v3搜索PublishedAfter Tag with Formine=true
目前,我正在处理一个项目,该项目需要为Oauth 2登录用户返回不公开的视频。因为我试图获得不公开的视频,所以我必须使用ForMine变量。所以我得到的是 https://content.googleapis.com/youtube/v3/search?part =片段 它工作正常。但是,我想做一个增量加载。这需要仅在特定时间后发布视频。一旦我添加发布后参数“发布后=1970-01-01T00:0
-
查询dynamodb进行文本搜索?
我正在寻找优化Dynamodb操作,即删除扫描和使用查询快速获取数据。 表数据: 我必须使用项目名称进行项目搜索。现在,我们扫描整张桌子。 然后,如果itemOwners包含搜索用户的用户ID,我们将过滤items结果。 我想知道是否有更好的方法使用dynamodb进行搜索查询?
-
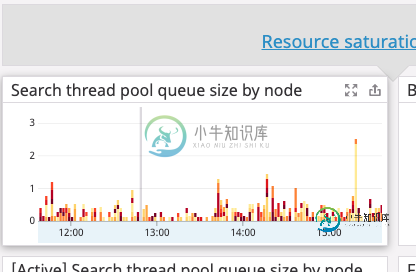 了解elasticsearch的搜索线程池
了解elasticsearch的搜索线程池我使用Datadog与elasticsearch的集成来监控ES集群,它在仪表板上显示的一个重要指标是活动和等待搜索线程的数量。参考这个ES文档,我知道搜索线程在ES中的一个请求队列上工作,该队列的固定大小为1000。 如图所示,我看到很多等待线程,但这里没有解释拒绝队列异常。所以这意味着ES没有拒绝请求,但搜索线程仍然无法足够快地执行请求,因此最终处于等待状态很长一段时间。 问题 搜索请求队列的
-
 灵活的搜索问题SAP Hybris
灵活的搜索问题SAP Hybris我对灵活的查询有问题。这是我的疑问: 这是我执行时的错误: 有人能帮我吗?谢谢。
-
弹性搜索+LogStash无法连接
我试图使用docker容器创建一个弹性搜索安装。我只使用Elastic.io提供者的映像。 我不知道为什么,但logstash告诉我,他无法连接到带有此错误消息的ElasticSearch实例: 如果logstash真的得到了我的设置,有人能告诉我为什么他使用了一个坏的主机事件吗?
-
搜索没有主键的记录
我有一个spring实体类,如下所示。 具有相应的getter和setter。 我已经为这个表访问编写了一个Spring Data JPA存储库,如下所示。 但我想使用value读取所有记录。但不是主键。所以我想知道如何实现这一点。 有人能帮我一下吗。
-
如何在PhpStom中搜索文件?
> Eclipse 具有此功能,您可以在其中搜索文件夹中的任何文件。PhpStorm 中是否有这样的功能? 是否有缩进的快捷方式,如何自定义? 谷歌了一下,但没有结果。
-
搜索android Gradle的依赖关系
我在找一个android gradle Dependancie。 网站http://gradleplease.appspot.com/似乎停止工作。 有类似的网站吗? 否则,搜索特定库的提示?
-
弹性搜索多项滤波器
我对Elasticsearch相当陌生,所以这是我的问题。我想用elasticsearch做一个搜索查询,想用多个术语过滤。 如果我想搜索用户'Tom',那么我希望获得用户'is active=1'、'is private=0'和'is owner=1'的所有匹配项。 这是我的搜索查询 谢谢你的帮助!!
-
 Inner join mysql性能搜索产品
Inner join mysql性能搜索产品我有两张桌子: 现在,如果有人正在寻找关键字“car”,它会看看下面的表词: 这样的单词非常快。 问题是,当我想用这个词得到独一无二的产品时。这些表与words.id和products_words.word连接。 我使用了以下SQL: 我不明白它为什么要看1799211行?我需要告诉MySql先看words表,选择F.E。10个ID和给我带来独特的产品与这些ID的Word。 我做错了什么? 谢谢你
-
弹性搜索ignore_above设置使用
如果弹性文档中提到长度超过上面的ignore_设置的字符串将不会被索引或存储,请任何人帮助解释关于上述ignore的疑问。对于字符串数组,上面的ignore_将分别应用于每个数组元素,长度大于上面的ignore_的字符串元素将不会被索引或存储。 这是否意味着,如果我添加的数据长于长度,那么它将不允许在ES中发布数据 https://www.elastic.co/guide/en/elasticse
-
在excel列中搜索字符串
我的问题 当我搜索时,它会按要求返回,但当我搜索时,它会返回,为什么会出现这种情况,以及如何修复它?
-
搜索并删除单个单词
我想从文件。 示例: 我想给我们一种动态命令,因为我不必每次为每个用户手动输入。 我试过了 但这并没有达到预期的效果。
-
弹性搜索子集滤波器
我有一个关于书籍的数据集,每本书都可以是一种或多种语言的。每个用户都注册为拥有一种或多种语言。 当用户搜索书籍时,我只想返回那些他们理解所有语言的书籍。 例如,系统中有以下两本书: 如果John被注册为懂英语、德语、法语和意大利语,那么他的查询结果永远不应该包括Book B。 我的系统目前是使用Apache Solr编写的,最后我编写了一个插件来执行子集操作(如果记录的语言是用户语言的子集,则该记