《线性表》专题
-
屬性
屬性將值跟特定的類別、結構或列舉關聯。儲存屬性儲存常數或變數作為實例的一部分,計算屬性計算(而不是儲存)一個值。計算屬性可以用於類別、結構和列舉裡,儲存屬性只能用於類別和結構。 儲存屬性和計算屬性通常用於特定型別的實例,但是,屬性也可以直接用於型別本身,這種屬性稱為型別屬性。 另外,還可以定義屬性監視器來監控屬性值的變化,以此來觸發一個自定義的操作。屬性監視器可以添加到自己寫的儲存屬性上,也可以添
-
性能
如何分析一个由SQLAlchemy支持的应用程序? 查询分析 代码性能测试 执行缓慢 结果获取慢 - 核心 结果获取慢度-ORM 我用ORM插入了400000行,速度非常慢! 如何分析一个由SQLAlchemy支持的应用程序? 寻找性能问题通常涉及两种策略。一个是查询分析,另一个是代码分析。 查询分析 有时只是简单的SQL日志记录(通过python的日志记录模块或通过 echo=True 争论 c
-
特性
Graph::Easy 支持非常多的特性,下面是一些大致介绍。 Unicode Graph::Easy 对Unicode输入和输出有着完整的支持: [ العربية ] -- link --> [ 日本語 ] --> [ 中文 ] -- كوردي --> [ English ] 上面的例子包含了日文,中文,库尔德语,和一些其他的字符;下面是使用Graph::Easy输出的HTML格式的输出(这
-
性能
Perl 让你干想干的事,包括很慢或内存消耗这样的事。此处将告诉你如何避免。 使用 while 而非 for 来迭代整个文件 代替读取文件的所有行并使用 for 处理数组,使用 while 一次仅读取一行。 这两个循环的功能相同: for ( <> ) { # do something } while ( <> ) { # do something } 差异是 for 将整个文
-
性能
开发者经常询问优化 Electron 应用程序性能的策略。 软件工程师、用户和框架开发者并不总是就“性能”的含义达成单一定义。 此文档概述了Electron 维护者最喜欢的减少内存使用、 CPU 负载以及磁盘资源使用的方式。以确保您的应用程序能够响应用户输入并尽快完成操作。 此外,我们希望所有的性能策略都能保持您应用的高标准安全。 关于如何使用 JavaScript构建高性能网站的技巧和方法通常也
-
在go lang中是否在amqp.Dial具有线程安全性时每次创建连接
问题内容: 正如RabbitMQ文档中提到的那样,建立tcp连接非常昂贵。因此,针对该渠道概念进行了介绍。现在我遇到了这个例子。在每次发布消息时,它都会创建连接。 。它不应该一次全局声明,并且应该有故障转移机制,以防连接像单例对象那样被关闭。如果amqp.Dial是线程安全的,我想应该是 编辑的问题: 我以以下方式处理连接错误。我在其中侦听频道并在出错时创建新的连接。但是当我杀死现有的连接并尝试发
-
空的synced(this){}是否对线程之间的内存可见性有任何意义?
问题内容: 我在关于StackOverflow的评论中阅读了这篇文章: 但是,如果您想安全起见,可以在@PostConstruct的末尾添加简单的synced(this){} [方法] [请注意变量不是可变的] 我在想,只有在块中执行写入和读取操作,或者至少读取是易失性操作 时,才会 强制执行 before-before。 引用的句子正确吗?空块是否将当前方法中所有更改的变量刷新到“常规可见”内存
-
如何在javascript中从一个线性箭头函数返回匿名对象?[副本]
我最近切换到es6,开始在我的代码中使用箭头函数。在重构过程中,我遇到了以下代码 我把上面的代码改成了这个- 但是我从上面的代码得到错误。我不知道这里出了什么问题?我知道如果没有代码块,那么箭头函数提供了隐式返回。 但不知道如何返回空对象或匿名对象与一些属性初始化? 编辑: 如果我这样做有什么错?只是出于好奇。
-
如何使用pyomo建模框架在ipopt中使用(/安装)pardiso线性求解器?
我正在使用pyomo和python开发一个优化模型(python 3-我在windows上使用anaconda管理包)。我需要使用非线性求解器ipopt。似乎ipopt(腮腺炎或ma27)使用的默认线性解算器相对较慢且不可线程化,我希望将pardiso解算器用于ipopt的线性部分。它似乎有两个版本:MKL intel pardiso版本和“独立”版本-我对其中任何一个都没意见。-但我没有设法使用
-
为什么点区域四叉树搜索(用于碰撞检测)是线性时间?
完全创建四叉树后,为什么比较操作(用于对象的冲突检测)需要线性的时间?节点按区域/象限递归地拆分,搜索将向下扫描树,删除不在搜索坐标内的路径,最终在冲突节点的范围内找到或没有找到目标节点。每个操作都在比较一个划分的分区,这看起来像时间,而不是。
-
为什么java 5中的volatile不能确保从另一个线程的可见性?
根据: http://www.ibm.com/developerworks/library/j-jtp03304/ 在新的内存模型下,当线程A写入易失性变量V,线程B从V读取时,在写入V时对A可见的任何变量值现在都保证对B可见 互联网上的许多地方声明以下代码永远不应该打印“错误”: 当为1时,所有线程的应为1。 然而,我有时会打印“错误”。这怎么可能呢?
-
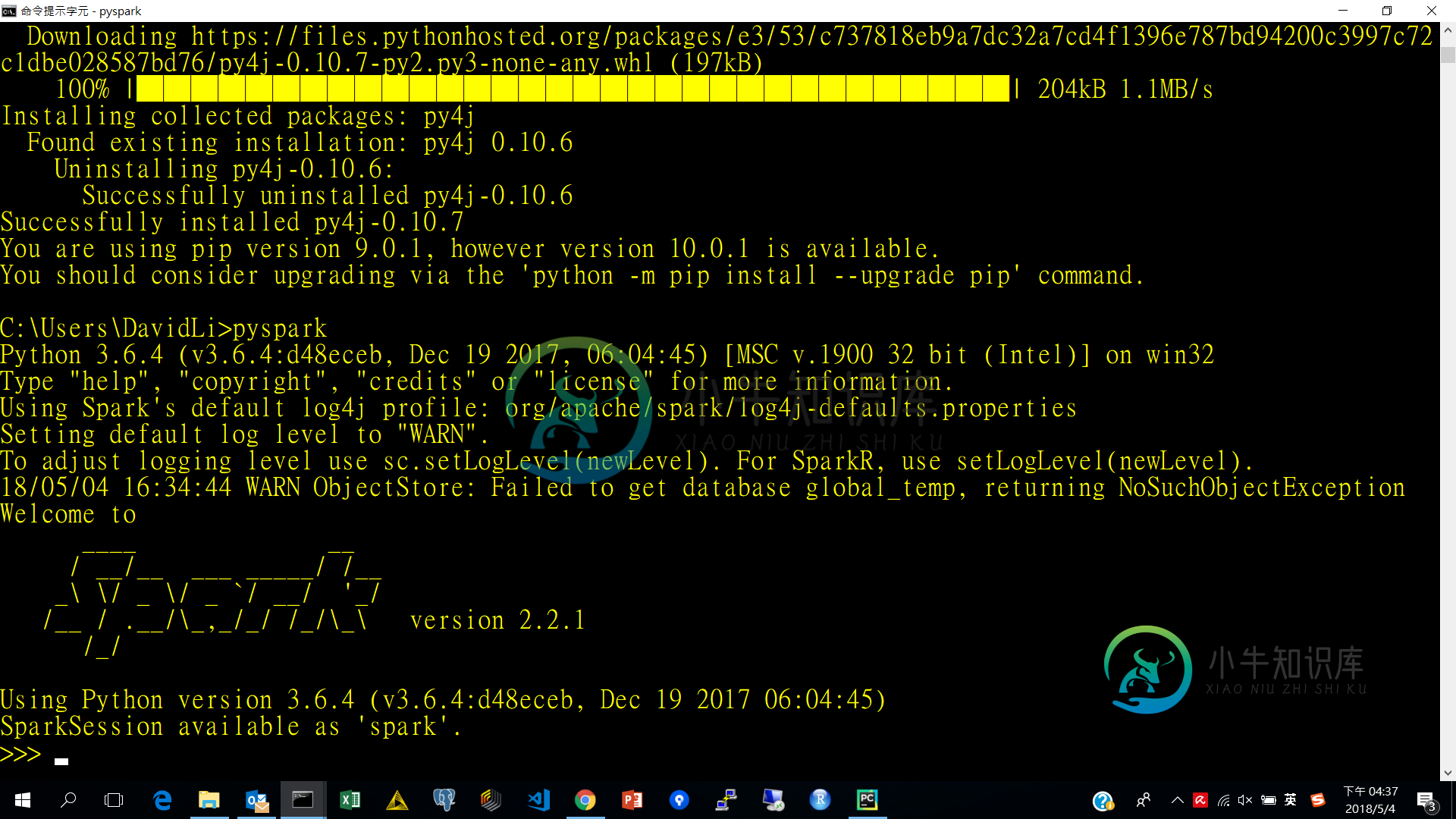 pyspark-py4j.protocol.py4jJavaerror,在我的win10笔记本电脑上运行spark线性回归模型时
pyspark-py4j.protocol.py4jJavaerror,在我的win10笔记本电脑上运行spark线性回归模型时我尝试在我的win10笔记本电脑上运行PySpark脚本,该脚本正在用PySpark和Spark MLlib建立线性回归模型, 我的代码如下: 我有如下错误消息:
-
具有Lambda表达式的线程
问题内容: 我在线路42和43的误差:, 未处理的异常类型InterruptedException的 。如果我尝试快速修复,它将使用catch Exception 创建try catch ,它将具有相同的错误,并且将尝试以相同的方式修复它,并继续用try catch包围它。 问题答案: 您已创建一个函数接口,该函数接口的方法声明为引发,这是一个已检查的异常。但是,你叫一个lambda表达式作为参数
-
matplotlib中是否有线型列表?
问题内容: 我正在写一个脚本,将做一些绘图。我希望它绘制几个数据系列,每个数据系列都有其独特的线条样式(不是颜色)。我可以轻松地遍历列表,但是python中已经有这样的列表了吗? 问题答案: 根据文档,您可以通过执行以下操作找到它们: 您可以使用标记做同样的事情 编辑:在最新版本中,仍然有相同的样式,但是您可以改变点/线之间的间隔。
-
临时表的Postgresql线程安全
问题内容: 我用于创建临时表的语法如下: 我知道这意味着在每笔交易结束时,都会删除该表。我的问题是,如果同一会话上的两个或多个线程创建并将值插入到临时表中,它们将各自获取自己的实例,还是该临时实例在整个会话中共享?如果它是共享的,是否有一种方法可以使每个线程本地化? 感谢Netta 问题答案: 临时表对于同一会话中的所有操作都是可见的。因此,在删除存在的临时表之前(在您的情况下提交事务),您 无法