《集群》专题
-
开发集群的部署
要从事 ceph 开发,可以用 vstart.sh 工具部署一个位于本地的伪集群,以便测试。 用法 用此工具可在本机部署伪集群以便开发,它可以启动 rgw 、 mon 、 osd 、和/或 mds ,不指定的话会启动所有类型。 要启动开发集群,执行此命令: vstart.sh [OPTIONS]... [mon] [osd] [mds] 要停止集群,可以执行: ./stop.sh 选项 -i ip
-
Envoy 集群流量控制
Sentinel 提供了一个 Envoy Global Rate Limiting gRPC Service 的实现 sentinel-cluster-server-envoy-rls,借助集群限流 token server 来为 Envoy 服务网格提供集群流量控制的能力。 Note: You can refer to here for the English version. 构建 若要构建可
-
Consul 集群安装部署
1、安装 1.1、下载 以linux下安装为例,首先下载安装包,下载地址:https://www.consul.io/downloads.html 下载后上传到 linux 服务器,或者直接在 linux 上下载,版本可自行替换 wget https://releases.hashicorp.com/consul/1.7.0/consul_1.7.0_linux_amd64.zip 1.2、解
-
搭建多节点集群
因为每个 Disque 节点都会将自己的配置信息储存在 disque-server 运行的文件夹里面, 而同一个文件夹只能有一份这样的配置信息, 所以如果我们打算同时运行多个节点, 那么就必须在不同的文件夹里面运行 disque-server , 并为每个节点指定不同的端口。 假设我们现在打算运行三个 Disque 节点, 那么首先要做的就是创建三个文件夹, 然后分别在这些文件夹里面运行 disq
-
搭建单节点集群
Disque 以集群模式运行, 每个服务器都是集群中的一个节点, 用户可以运行任意数量的节点, 只要确保每个节点的端口号不同即可。 在默认情况下, 运行 Disque 服务器程序 disque-server 将启动一个端口号为 7711 的 Disque 节点: $ ./disque-server 528:C 28 Apr 11:50:08.519 # Warning: no config fil
-
如何在收集列表、收集集合或组集合后修复配置单元错误?
假设我的配置单元表包含以下值: 我正在使用。我在collect_list/collect_set或group_concat查询后出现此错误。 错误:org。阿帕奇。蜂箱服务cli。HiveSQLException:处理语句时出错:失败:执行错误,从组织返回代码2。阿帕奇。hadoop。蜂箱ql.exec。org的MapRedTask先生。阿帕奇。蜂箱服务cli。活动活动toSQLException
-
从spark集群向cassandra集群写入dataframe:分区和性能调优
我有两个集群-1。Cloudera Hadoop-Spark作业在这里运行2。云-卡桑德拉星团,多DC 在编写从spark作业到cassandra集群的dataframe时,我在编写之前在spark中进行了重新分区(repartioncount=10)。见下文: 在我的多租户spark集群中,对于一个有20M记录的spark批加载,以及以下配置,我看到了很多任务失败、资源抢占和动态失败。 PS:我
-
任何Java集合以比较数据集
问题内容: 我有2个月的2个数据集,包括学生的姓名和分数。 我需要提供每个学生的2月分数,以及他/她2月分数的变化百分比。 我可以使用Java集合吗? 样本数据集: 输出应该是这样的 (名称:约翰,2月分数:80,百分比变化:100) (名称:玛丽,2月的分数:81,百分比变化:32.76) (名称:吉姆,2月的分数:82,百分比变化:57.69) (名称:利兹,2月的分数:84 ,百分比变化:N
-
两个或更多排序集的交集
问题内容: 我有两个排序集,并且想要进行交集,即。 关于效率,是否有比以下更好的方法: 问题答案: 您应该先使用ZCARD检查哪些元素较少,然后克隆并修剪较短的元素。 其次,您将剩下2个剩菜。您可以重复使用同一辅助程序,以加快清除速度。 我还想建议克隆使用DUMP和RESTORE,但是对于排序集的情况,ZUNIONSTORE实际上要快得多。这是一个100万个元素集的时间安排:
-
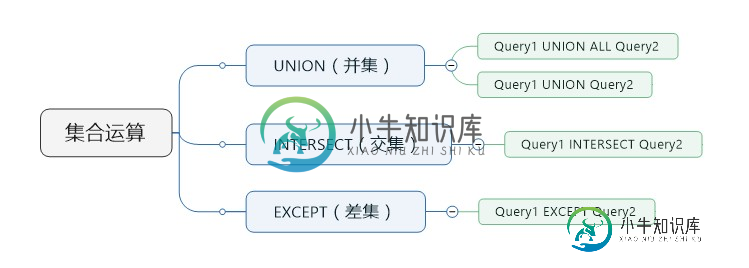 sql server 交集,差集的用法详解
sql server 交集,差集的用法详解本文向大家介绍sql server 交集,差集的用法详解,包括了sql server 交集,差集的用法详解的使用技巧和注意事项,需要的朋友参考一下 概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便。 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合。 在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个
-
添加到集合时修改了集合
尝试添加到集合时出现“Collection was modified”异常 问题出在“添加”方法上。如果我注释掉该部分,则不会引发异常。重要的是要注意,我已经尝试将foreach重写为for循环并添加“ToList()”以形成。链接。在所有情况下都会引发相同的异常。我在站点的其他部分使用这种完全相同的模式没有问题,这就是为什么这如此令人沮丧。这也适用于“创建”。问题只影响“编辑”操作。 其他相关代
-
将对象集映射到字符串集
我是Mapstruct的新手。我有一个Word对象,它包含一个字符串值和一组它自己,我想把它映射到WordDTO,它包含一个值和一组字符串值。我不知道怎么做。正如我在注释中所说,mapstruct不能映射两个对象是有道理的,但如果它有帮助,我将错误放在下面: 我为映射实现了这个接口: 谢谢你的帮助。
-
不同类型集合的集合重载
我知道重载是在编译时决定的,但当我试图运行下面的示例时,它给出了我无法理解的结果 当我每次运行这个代码片段时,我都会得到“Collection”的输出,这意味着调用参数为Collection的classify方法。 请解释
-
测试和持续集成 - 持续集成
translated_page: https://github.com/PX4/Devguide/blob/master/en/test_and_ci/continous_integration.md translated_sha: 95b39d747851dd01c1fe5d36b24e59ec865e323e PX4 Continuous Integration PX4 builds and
-
集合操作 - 集合间移动元素
smove srckey dstkey member 从srckey对应set中移除member并添加到dstkey对应set中,整个操作是原子的。成功返回1,如果member在srckey中不存在返回0,如果key不是set类型返回错误