《解释器》专题
-
函数返回函数的Redux中的函数参数解释?[副本]
我确实有点理解Redux,但我不明白如何将函数放入函数中。 我对这一行有问题: 我们在这里用
-
如何在保留注释的情况下解析golang中的general yaml?
-
Kubernetes逐出API不能完全解释Elasticsearch集群的健康状况?
我希望以一种不知道集群上运行的应用程序细节的方式对Kubernetes集群执行自动滚动更新。原则上,PodDisruptionBudget应该促进这一点。 这里有一个障碍:有一个Elasticsearch集群在这个Kubernetes集群上运行,我找不到一种方法来正确表达“OK to execute an ES Pod”信号。具体来说,在这种情况下,“这个Pod可以接收流量”和“这个Pod可以被逐
-
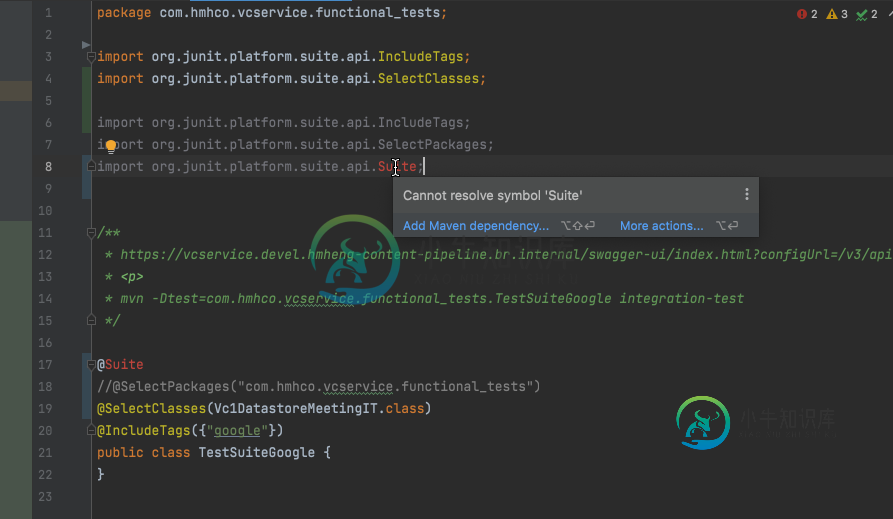 无法解析 junit.platform.suite.api 的符号套件,当使用 Spring 父注释时
无法解析 junit.platform.suite.api 的符号套件,当使用 Spring 父注释时我正在尝试将我们的项目从JUnit4更新到JUnit5,但我在导入时遇到了这个错误。 我认为这个问题与使用spring parent有关。如果我把它从我的调试分支中移除,它就会工作。 然而,可能有一种方法可以保持两者? 我试图从spring测试中排除JUnit平台套件引擎,但这不起作用。 这是我的完整pom: 谢谢。
-
更详细地解释JOIN与LEFT JOIN和WHERE条件性能建议
在这个候选答案中,有人断言,在某些涉及一些WHERE子句的情况下,JOIN优于LEFT JOIN,因为它不会混淆查询计划器,也不是“无意义的”。断言/假设是,这对任何人来说都应该是显而易见的。 请进一步解释或提供链接以供进一步阅读。
-
如何解释Python覆盖率。py分支机构覆盖率结果?
我正在使用来衡量我的测试的代码覆盖率。我已经启用了分支机构覆盖,但我不能完全理解该报告。 没有分支保险,我得到100%的保险: 启用分支覆盖: 有问题的来源可以在这里找到。 <代码>21- 然而,<代码>53-
-
有人能解释一下为什么这是可能的吗?[重复]
它通常会打印“z”。为什么它不返回分段错误?因为我试图访问一个不应该存在的索引,因为strB的大小(索引数量)等于tam_strA,它等于3。 另外,做有什么不同/问题吗?
-
你能解释一下Swift中静态和类的区别吗?[副本]
你能告诉我什么时候和为什么我应该使用关键字static以及什么时候我应该使用关键字class吗?(这是Swift中的类型属性语法)
-
递归神秘方法——有人能给我解释一下吗?[重复]
对于下面的方法,调用神秘(45)时,输出为“1 0 1 1 0:2 5 11 22 45”,我明白为什么“1 0 1 1 0:”打印出来,但不明白冒号后“2 5 11 22 45”是怎么打印出来的,有人能给我解释一下吗?我试着写出来,但就是想不通。
-
竞争程序员手册,最长递增子序列-需要解释
我很难理解上面提到的话题的一部分。 我们的第一个问题是确定n个元素数组中最长的递增子序列。这是数组元素的最大长度序列,从左到右,序列中的每个元素都比前一个元素大。例如,在数组中 <代码>{6,2,5,1,7,4,8,3} 最长的递增子序列包含4个元素: 我不理解的部分是为什么如果对于某个k,length(k)=c,那么为什么n>k有可能有length(n)
-
conda命令将提示错误:“错误的解释器:没有这样的文件或目录”
问题内容: 我正在使用arch linux,并且已经按照Anaconda网站上的说明安装了Anaconda。当我尝试运行时,出现以下错误: bash:/ home / lukasz / anaconda3 / bin / conda:/ opt / anaconda1anaconda2anaconda3 / bin / python:错误的解释器:无此类文件或目录 我尝试过查找目录,但是它根本不存
-
PyCharm:版本化.idea文件夹,同时在开发人员中保留不同的解释器
我们使用PyCharm作为一个项目的Python IDE。开发人员使用不同类型的OS设置,例如,python路径对我们中的一些人来说是不一样的(有些人将本地解释器存储在不同的位置或远程解释器)。 不幸的是,python解释器路径存储在.idea PyCharm项目文件夹(.iml文件)中。然后在与Mercurial合并分支时导致冲突或python路径重写。 注意:有一个有趣的SO问题(跨多个操作系
-
除了缓存指令,解释器生成的本机代码和JIT有什么区别吗?
我无法理解口译员和JIT之间的区别。例如,从这个答案中: JVMJava虚拟机-运行/解释/翻译字节码到本机代码 JIT是实时编译器——在运行时将给定的字节码指令序列编译为机器代码,然后在本地执行。它的主要目的是对性能进行重大优化。 两者都产生本机机器代码。然后,从另一个答案来看: 解释器为每条指令动态生成和执行机器代码指令,而不管之前是否执行过。JIT缓存以前已解释为机器代码的指令,并重用这些本
-
Perl中的单行注释和多行注释语法
本文向大家介绍Perl中的单行注释和多行注释语法,包括了Perl中的单行注释和多行注释语法的使用技巧和注意事项,需要的朋友参考一下 同其他大多数编程语言一样,Perl中的单行注释也是#开头,例如: 但多行注释,不同的语言有不同的注释方式,比如说: Java,C/C++: Python: Ruby: Shell: Perl: 多行注释为: 说明:第一个等号必须紧跟一个字符! 比如说:
-
将类注释的@Component更改为@Bean注释的method
我有一个被注释为的类,然后将其添加到另一个类中。但是,我需要删除这个注释,而是在以前自动连线它的类中用一个注释方法创建它。 以前的类看起来像: ...或者我直接调用这个方法(在我看来不是正确的方法): …或者这两个都不正确?