《scala》专题
-
scala.reflect.internal.MissingRequirement错误: 找不到编译器镜像中的对象 java.lang.Object。预测设置
我正在尝试设置一个预测IO引擎以在我的项目中进一步使用,我在为推荐引擎构建预测应用程序时遇到了这个问题 Java版本 Scala版本
-
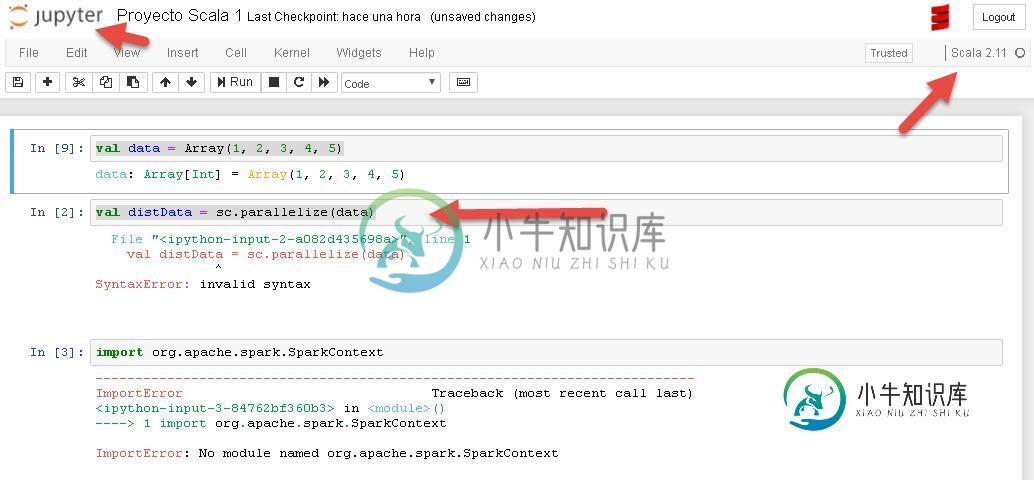 我不能从Jupyter运行scala
我不能从Jupyter运行scala我在jupyter中,选择kernel scala 2.11,当我放置返回数据时运行平稳: 然后,当我执行时,它返回
-
scala版本`2.10.5`中的Scallop Verify()方法不起作用
这里有什么变通方法可以让它与Scala2.10.5一起工作吗?
-
如何在akka-kryo-serializer中使用Scala映射
下面的行不编译,因为编译没有找到“hashmap$hashtriemap” 40) 最后,我的示例如下所示: 注我没有使用Kryo特定的Akka特性,我使用它作为一个通用的序列化框架。火花也一样。没有直接插入火花或akka配置。
-
番石榴Bloomfilter-Scala编译器中的错误:尝试做typevar的lub/glb?t
使用scala 2.11.8、guava 20.0和sbt 0.13.13,以下代码片段会导致编译崩溃: 错误为:
-
Spark Scala noClassDefFounderRor:org/apache/Spark/logging
以下是我的构建。SBT内容:
-
找不到Scala清单Spark流
我对Spark Streaming是新手,从Spark Streaming我使用Kafkautils创建了一个直接到Kafka的流。如下所示 当我试图运行该作业时,它正抛出以下错误 下面是我的pom.xml 请让我知道如何解决这个问题。
-
 java.lang.NosuchMethodError:Scala.predef$.RefArrayOps在Spark作业中使用Scala
java.lang.NosuchMethodError:Scala.predef$.RefArrayOps在Spark作业中使用Scala完全错误: 线程“main”java.lang.nosuchmethoderror:scala.predef$.refarrayops([ljava/lang/object;)[ljava/lang/object;)[ljava/lang/object;;在org.spark_module.sparkmodule$.main(sparkmodule.scala:62)在org.spark_modu
-
为什么apache spark工件名称包含scala版本
在maven存储库http://mvnrepository.com/artifact/org.apache.spark中,apache-spark版本1.4.1有两种版本。 SPARK-*2.10和SPARK-*2.11 这些似乎是Scala版本。如果我使用java发行版部署apache-spark,那么哪一个是首选?
-
在Scala中将中缀转换为后缀表示法
我试图将给定的数字或代数表达式从内缀符号转换为后缀符号。我希望能够对多位数和负数的数字也这样做。我没有使用指数,如2^3=8。 我使用了一个有点困难的输入表达式,并且我能够成功地将其解析为负数和由多个数字组成的数字。然后,我将这个最终表达式放入ListBuffer中。我创建了一个堆栈类,并定义了我需要的几个方法。我唯一的问题(可能不是唯一的问题)是当我遇到“我不相信我正确地使用了pop和peek”
-
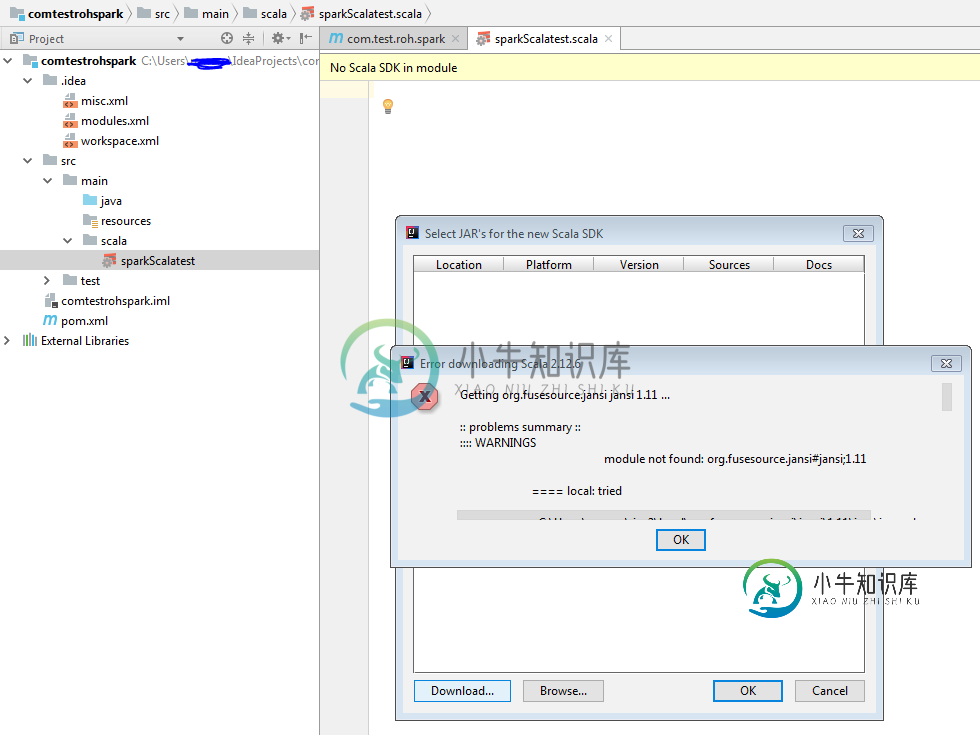 无法从intellij下载/安装Scala sdk
无法从intellij下载/安装Scala sdk我在intellij中创建了一个maven项目,并尝试下载scala SDK。我得到下面的错误。请帮助我,如果您曾遇到相同的问题与下面的细节。 正在获取org.fusesource.jansi jansi 1.11... ::问题摘要::::::::未找到警告模块:org.fusesource.jansi#jansi;1.11====本地:已尝试 C:\users\userx.ivy2\local
-
为什么sbt报告Scala2.10.2缺少库(自8月1日起)?
我有很多Play2.2.x应用程序,已经构建了几个月没有问题了。然而,从2014年8月1日开始,我开始收到以下警告和错误: 正在获取org.scala-sbt sbt 0.13.0... 未找到警告模块:org.scala-lang#scala-library;2.10.2 repo.typesafe.com/typesafe/iv-releases/org.scala-lang/scala-li
-
如何通过scala in play框架连接到cassandra
我正在寻找的ans是通过Play-Scala连接到cassandra所需要的依赖项。cassandra版本2.2.0,play版本2.4 我的build.sbt文件: 惰性val root=(文件中的项目(“.”))。enablePlugins(PlayScala) scalaVersion:=“2.11.6”libraryDependencies++=Seq( “com.typesafe.akk
-
如何强制Scala使用不同的库版本?
将以上内容更改为 解决了问题。但是,与其将Scala-XML2.11版本1.0.5排除在scalatest之外,我想强制scala编译器使用Scala-XML2.11版本1.0.5而不是版本1.0.4。(我在https://mvnrepository.com上研究了这些版本。)因此,我尝试将替换为 然而,这导致 [警告]*org.scala-lang:scala-library:(2.11.8,2
-
未解析的依赖关系org.scallatest#scalatest2.11;2.2.6:找不到
我刚刚在Coursera上开始Scala专门化的函数编程。正在进行设置并查看第一个视频。当我修改Intellij中的sbt时,我得到“Module not found:org.scallatest#scalatest2.11;2.2.6” 我的sbt如下所示: 版本:=“1.0” scalaVersion:=“2.11.8”libraryDependencies+=“org.scallatest”