《xpath》专题
-
XPath如何处理XML命名空间?
XPath如何处理XML命名空间? 如果我使用 为了解析下面的XML文档,我得到了0个节点。 但是,我没有在XPath中指定名称空间(即不是路径的每个标记的前缀)。如果我没有明确告诉XPath,它怎么知道我想要哪个?我认为在这种情况下(因为只有一个名称空间),XPath可以完全忽略。但如果有多个名称空间,事情可能会变得糟糕。
-
为什么我在selenium相对XPath中得到语法错误?
//div class=“vp-btnc-text”xpath=“1”>cs-核心容量规划 Chropath提供的相对路径://div[contains(text(),'CS-Core Capacity Planning')] 我正在尝试的代码行是:driver.find_element_by_xpath('//div[contains(),'CS-Core Capacity Planning')
-
 无法定位元素xPath Selenium Webdriver
无法定位元素xPath Selenium Webdriver我试图引用并单击网页上的元素。 我们应该能够使用简单的XPath进行引用。例如 然而,这似乎并不奏效。 我使用的chrome扩展表示该元素不存在。 我的代码找不到元素。 下面是我使用Selenium web驱动程序的Java代码。 以下是错误: 太奇怪了!关于为什么我不能引用元素,或者为什么xPath不exist的任何想法。
-
无法通过xpath找到元素(JS激活的网站Selenium chrome)
我试图刮一个使用JavaScript的网站。我在Selenium中的xpath上看过类似的问题,但它们并没有真正的帮助。我尝试使用请求,但Javascript没有完全加载,所以我使用Selenium chrome驱动程序。 我尝试了完整的xpath、xpath和类名,但无法获得元素。下面是我的代码和html。
-
Python Selenium:无法通过Xpath定位元素
我试图通过selenium单击save按钮,但是,我得到的错误是它无法定位元素。 这是网站的html部分 这是我得到的错误: NoSuchelementException:没有这样的元素:找不到元素:{“method”:“id”,“selector”:“divflashviewermain_savepdfbuttonicon”} (会话信息:chrome=74.0.3729.169)(驱动程序信息
-
Selenium无法通过XPath定位元素
你知道为什么吗?
-
Selenium未定位xpath元素
-
Selenium XPath:无效选择器--当为同一元素传递多个条件时
纠正我。
-
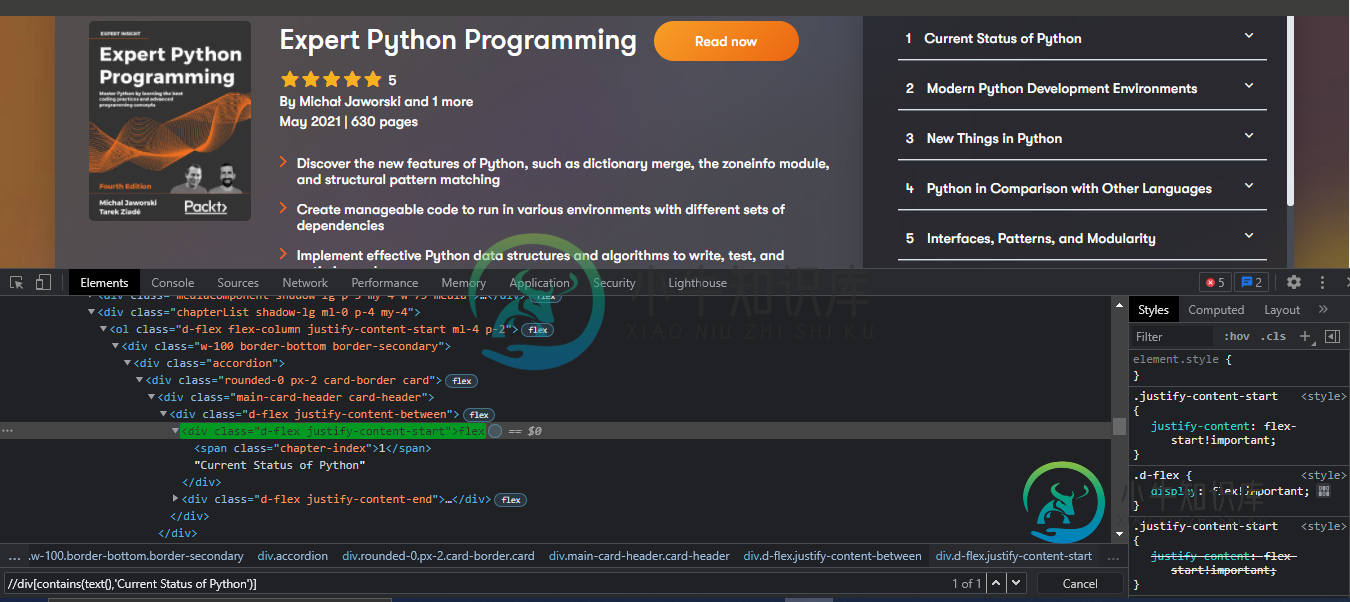 即使验证了Xpath,也无法在运行时找到Xpath[重复]
即使验证了Xpath,也无法在运行时找到Xpath[重复]嗨,我正在尝试访问一个xapth,我已经从开发人员工具中验证了它是正确的。但是在运行时,我是selenium无法定位它,并且获取元素不可见的异常。 My Xptah://div[contains(text(),'Current Status of Python')] 我在这里找不到任何iframe,但在运行时它仍然无法定位元素。
-
java xpath从xml中删除元素
我正在尝试从xml文件中删除元素和子元素。特别是附加名称Testlog。 首先这是我的xml文件的外观。 以下是我的java代码: 我想删除此appender的所有内容,但引发了一个异常。可能是我错过了一些简单的东西。 有什么想法吗?
-
 Selenium在特定页面的XPATH上找不到元素
Selenium在特定页面的XPATH上找不到元素基于文本的HTML:
-
Selenium,了解xPath;输入vs选择;循环浏览元素
案例选择 案例输入 因为我不知道字段类型是什么,所以我将使用以下sytnax: > 据我所知,当我使用selenium驱动程序时。通过xpath查找\u element\u,使用路径的“*”示例,代码将返回符合条件的第一个元素<我如何使用“查找下一个”之类的词 如何区分输入和选择字段? 我尝试了以下操作: obj.get_attribute("type")-
-
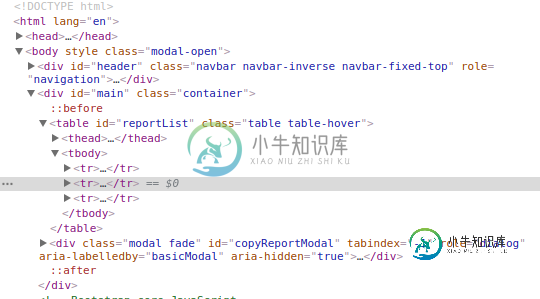 Selenium-通过文本查找xpath(td/tr)
Selenium-通过文本查找xpath(td/tr)我有一个大的超文本标记语言电子邮件表,我正在尝试查找特定电子邮件的名称,然后在此元素中选择一个按钮。我可以通过XPATH轻松找到表体: 那么在这个表中有多行(tr),是否可以在所有表行中搜索文本? 我得到的最接近的结果是: 不幸的是,这无法定位元素。 我知道我可以简单地复制XPATH以定位特定的tr,但是出于自动化目的,我尝试传递一个字符串,然后在所有tr中搜索我的特定文本。
-
如何使用XPath查找具有相同信息的两个不同元素
我试图找到在同一页中重复自身的元素。我尝试使用在FirePath中找到的以下XPath,但在selenium自动化测试中没有成功运行它。 以下是两个XPath: 这是我页面上的信息: 带有两个字段和部分超文本标记语言代码的截图 第一个屏幕截图上显示了另一个包含两个输入文本的HTML代码的屏幕截图
-
如何基于XPATH过滤元素?
我想选择仅在顶级国家/地区之后或仅在其他国家/地区之后的span元素 我已经尝试了 如果我分别尝试这两种XPATH,它们都可以工作,但如果结合使用,它们就不起作用。 我只想选择排名靠前的国家,并将其列入一个列表:,然后过滤掉其他国家。 如果我使用[text()=“Top Countries”]//以下同胞::span所有国家都被选中。例如,<代码>[“澳大利亚”、“几内亚比绍”、“西班牙”、“瑞士