《jmeter》专题
-
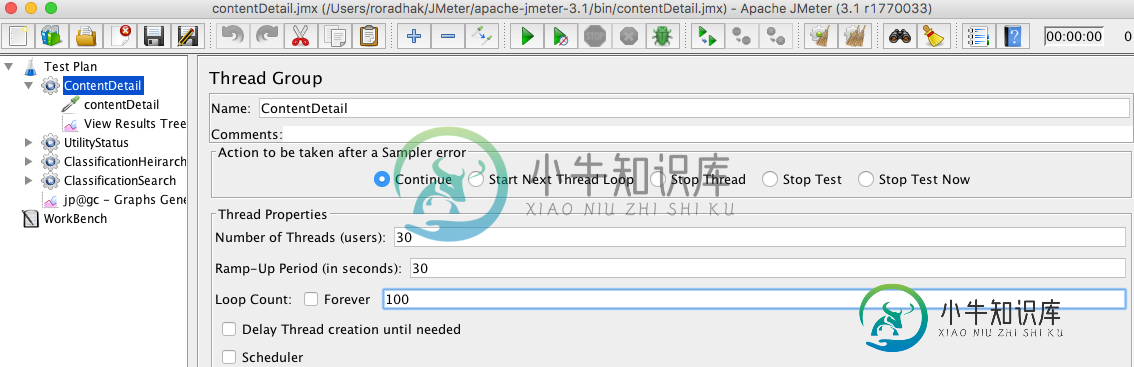 JMeter中的循环计数和上升周期
JMeter中的循环计数和上升周期我已经创建了一个集,只是与循环计数和斜坡周期混淆。我有一个具有以下参数的测试集。 根据Quora上的页面。
-
JMeter在使用调度器时忽略持续时间
null null 线程组用于登录事务,有57个示例。当我点击Run时,整个线程不是运行1800秒,而是运行84秒 运行前有什么需要检查或配置的吗?
-
JMeter:测试5个用户的场景,增加1小时触发10,000个请求
null 请建议和指导。
-
在JMeter中陆续添加用户
-
一段时间内/所需持续时间内的Jmeter负载测试网站
如何在jmeter(负载测试)中模拟多个会话(用户)在网站上长时间停留(例如超过15分钟)并发出多个请求
-
在Jmeter的线程组中爬升
我对在JMeter中设置斜坡有异议。 下面描述了我的测试场景。 null
-
如何在JMeter中将文件传递给CSV采样器
我有一个包含CSV文件的目录。每个文件都包含我想用JMeter发出的GET请求列表。我想要做的是读取一个目录中的所有文件,然后循环通过每个CSV在JMeter中发送请求。文件的数量不一致,所以我不想将文件名硬编码到CSV采样器中。 因此,实际上,我希望读取目录中的所有文件,并将这些文件存储在一个数组变量中。循环遍历数组并将CSV文件发送给CSV采样器,然后CSV采样器读取CSV文件并将内容传递给H
-
使用JMeter从ForEach控制器中的目录中自动读取多个CSV文件
Im试图从While控制器中的特殊目录读取多个CSV文件,以将文件中的数据转换为特定的JMeter属性/变量。但我总是得到一个错误: 有没有可能这个变量现在没有被求值?(__v不能改变任何东西)。我真的不知道为什么这不起作用。 当我在ForEach和While控制器之间放置一个调试采样器时,它会显示JMeterVariable CURRENTACTIONATTRIBUTEFILE具有正确的路径和文
-
如何在JMeter中的groovy脚本采样器中检测“CSV数据集配置”的?
我想知道,如何在groovy脚本中对a做出反应。我正在使用While控制器迭代CSV中的所有行,并在实际测试计划之前生成JMeter变量。对于不同的CSV文件,我需要多次执行此操作,因此我不想在While控制器中停止线程。 我想象了这样的事情: CSV_VALUE1是JMeter变量的值,CSV_VALUE2是变量的名称。 测试计划 我也很欣赏更好的解决方案,它遍历CSV文件的每一行,并根据我的约
-
如何使用CSV配置集的共享模式在JMeter中运行线程?
有没有办法在CSV数据集配置中使用“共享模式”的这个选项“编辑”?我在官方网站上找到了这个描述? apache jmeter组件CSV数据集配置 标识符-共享相同标识符的所有线程共享相同的文件。例如,如果您有4个线程组,您可以为两个或更多的组使用一个公共id来在它们之间共享文件。也可以使用线程号在不同线程组中的相同线程号之间共享文件。 但是我不明白普通id和线程号是什么意思?如何将它们用于特定的线
-
如何通过JMeter设置的“用户定义变量”进行迭代/循环?
是否有可能像CSV数据集(WHILE-COUNTER-CSV数据集Config)一样,对“用户定义的变量”集进行迭代或循环? 我想为“User Defined Variables”集合中包含的每个变量激发一个JDBC请求(Select语句)。它在CSV文件中工作得很好,但我不知道如何在变量集中循环。有可能吗?我有各种场景,在那里我想要循环一个“用户定义的变量”集。
-
如何使用Jmeter从一个位置读取多个csv文件
我想让我的Jmeter从一个位置读取多个csv文件,比如C:\Jmeter\file。 当前,如果我在csv数据集配置下的'filename'中提供特定的csv文件名,Jmeter会识别该文件并执行我的脚本。 我不想对文件名进行硬编码,我想让jmeter从该位置自动读取。 我已经编写了BeenShell预处理器(因为我找不到任何简单的解决方案),这个程序从位置读取所有csv文件列表,并将它们存储在
-
JMeter使用变量作为CSV文件位置
在我的JMeter测试中,我在其他几个模块中嵌套了一个循环控制器,其中包含一个CSV数据集配置。我的线程组顶部还有一个CSV数据集配置,它从CSV读取文件位置。我要在嵌套的CSV数据集中使用这个文件位置,以便从该位置获取CSV并循环访问该位置。由于在测试开始时一次加载了所有的CSV文件,因此会抛出一个错误。有没有一种方法可以延迟CSV的加载,这样我就可以确保文件路径变量已经设置好了?
-
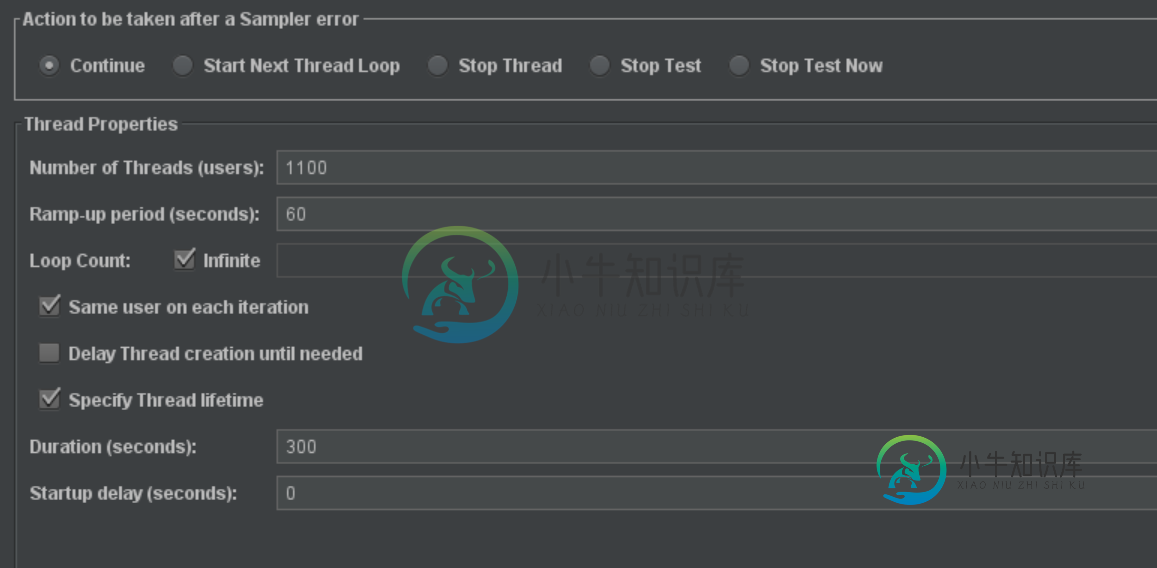 Jmeter-计算上升周期
Jmeter-计算上升周期我在配置中错过了什么? “无限”复选框需要勾选还是不勾选?
-
jmeter中的线程数、上升周期、循环计数、调度器持续时间
线程组1和线程组2之间有什么区别吗? 每个循环之间的时间上限是多长? 线程组3、4、5和6之间有什么不同吗? 组3、4、5和6是否都需要5秒才能发送完所有请求?每组的总成绩应该是5吗? 当我尝试线程组5时,我得到了大约83个回复,为什么不只有5个回复?这是否意味着上升周期不起作用? 我很困惑这些群体之间的差异,希望有人能帮助我。提前多谢!