《kafka》专题
-
Storm 集成 Kafka
一、整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持; Storm Kafka Integration (0.10.x+) : 包含 Kafka 新版本的 consumer API,主要对 Kafka 0.10.x + 提供整合支持。 这里我服务端安装的
-
Spark Streaming 整合 Kafka
一、版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下: spark-streaming-kafka-0-8 spark-streaming-kafka-0-10 Kafka 版本 0.8.2.1 or higher 0.10.0 or higher A
-
Apache Kafka Binder
用法 对于使用Apache Kafka绑定器,您只需要使用以下Maven坐标将其添加到您的Spring Cloud Stream应用程序: <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-kafka</artifactId> </dependen
-
Kafka Streams
streams streams_overview Kafka Streams is a client library for processing and analyzing data stored in Kafka and either write the resulting data back to Kafka or send the final output to an external s
-
Kafka Connect
connect connect_overview Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other systems. It makes it simple to quickly define connectors that move large collec
-
spring-cloud-stream结合kafka使用详解
本文向大家介绍spring-cloud-stream结合kafka使用详解,包括了spring-cloud-stream结合kafka使用详解的使用技巧和注意事项,需要的朋友参考一下 1.pom文件导入依赖 2.application.yml文件配置 3.创建消息发送者 4.创建消息监听者 接下来就可以愉快的发送监听消息了 到此这篇关于spring-cloud-stream结合kafka使用详解的
-
Kafka Connect JDBC与Debezium CDC
问题内容: JDBC连接器和Debezium SQL Server CDC连接器(或任何其他关系数据库连接器)之间有什么区别?何时应该选择一个 ,寻找一种在两个关系数据库之间进行同步的解决方案? 不确定此讨论是否应该针对CDC与JDBC连接器,而不是 Debezium SQL Server CDC连接器,甚至不是Debezium,期待 以后进行编辑,取决于给出的答案(尽管我的情况是关于SQL Se
-
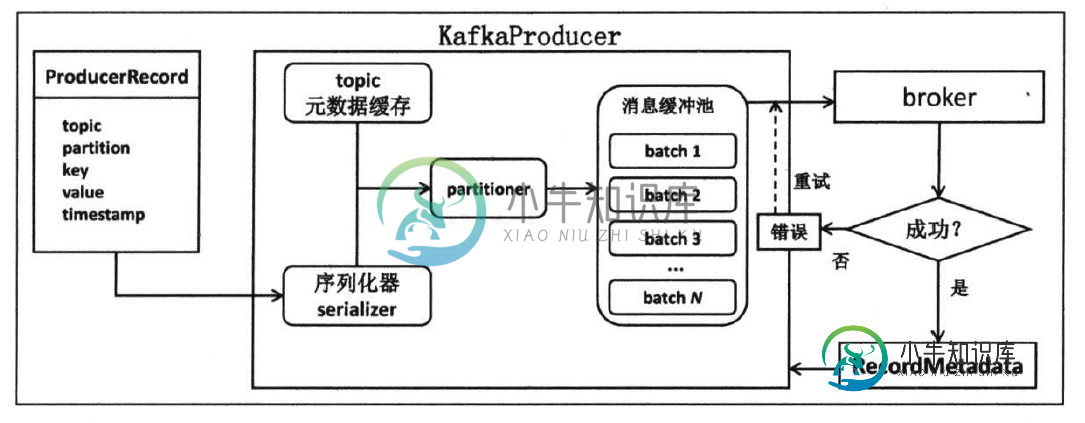 Kafka producer端开发代码实例
Kafka producer端开发代码实例本文向大家介绍Kafka producer端开发代码实例,包括了Kafka producer端开发代码实例的使用技巧和注意事项,需要的朋友参考一下 一、producer工作流程 producer使用用户启动producer的线程,将待发送的消息封装到一个ProducerRecord类实例,然后将其序列化之后发送给partitioner,再由后者确定目标分区后一同发送到位于producer程序中
-
 Kafka多节点分布式集群搭建实现过程详解
Kafka多节点分布式集群搭建实现过程详解本文向大家介绍Kafka多节点分布式集群搭建实现过程详解,包括了Kafka多节点分布式集群搭建实现过程详解的使用技巧和注意事项,需要的朋友参考一下 上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法。多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建。 一、安装Jdk 具体安装步骤可参考linux安装jdk。 二、安装
-
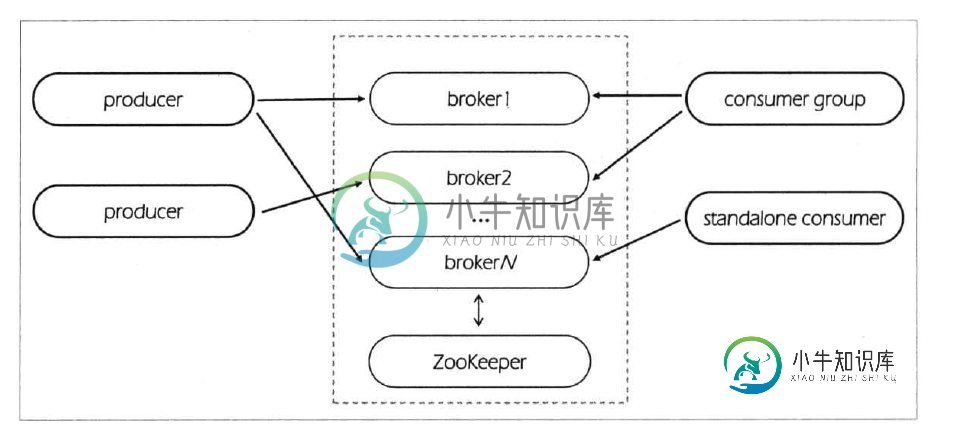
 Kafka使用入门教程第1/2页
Kafka使用入门教程第1/2页本文向大家介绍Kafka使用入门教程第1/2页,包括了Kafka使用入门教程第1/2页的使用技巧和注意事项,需要的朋友参考一下 介绍 Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topic为单位进行归纳。 •将向Kafka topic发布消息的程序成为
-
 Linux下Kafka单机安装配置方法(图文)
Linux下Kafka单机安装配置方法(图文)本文向大家介绍Linux下Kafka单机安装配置方法(图文),包括了Linux下Kafka单机安装配置方法(图文)的使用技巧和注意事项,需要的朋友参考一下 介绍 Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topic为单位进行归纳。 •将向Kafka
-
docker-compose部署zk+kafka+storm集群的实现
本文向大家介绍docker-compose部署zk+kafka+storm集群的实现,包括了docker-compose部署zk+kafka+storm集群的实现的使用技巧和注意事项,需要的朋友参考一下 集群部署总览 172.22.12.20 172.22.12.21 172.22.12.22 172.22.12.23 172.22.12.24 zoo1:2181 zoo2:2182 zoo3:2
-
将Kafka与Netflix导体结合使用
我想知道是否有一种简单的方法来连接Kafka和Netflix导体(而不是SQS)?目前,它似乎只适用于Amazon SQS。此外,似乎只能按任务执行一个操作。有没有办法按任务执行多个操作? 提前感谢,
-
批处理监听器使用application.yml/properties的Spring kafka集成属性
我试图在spring boot应用程序中使用kafka消费者批处理。我可以看到一些例子,其中我们有一个kafka配置类,其中,被配置并 已启用。我只是想知道这是否可以在没有工厂类的情况下实现,即在应用程序中使用SpringKafka集成属性。yml。早些时候,我定义了一个工厂,并通过应用程序将其替换为SpringKafa集成属性。yml用于简洁的代码。我试图了解后者是否有局限性,使用配置类是否更可
-
python3连接kafka模块pykafka生产者简单封装代码
本文向大家介绍python3连接kafka模块pykafka生产者简单封装代码,包括了python3连接kafka模块pykafka生产者简单封装代码的使用技巧和注意事项,需要的朋友参考一下 1.1安装模块 1.2基本使用 1.3简单封装 以上这篇python3连接kafka模块pykafka生产者简单封装代码就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。