《kafka》专题
-
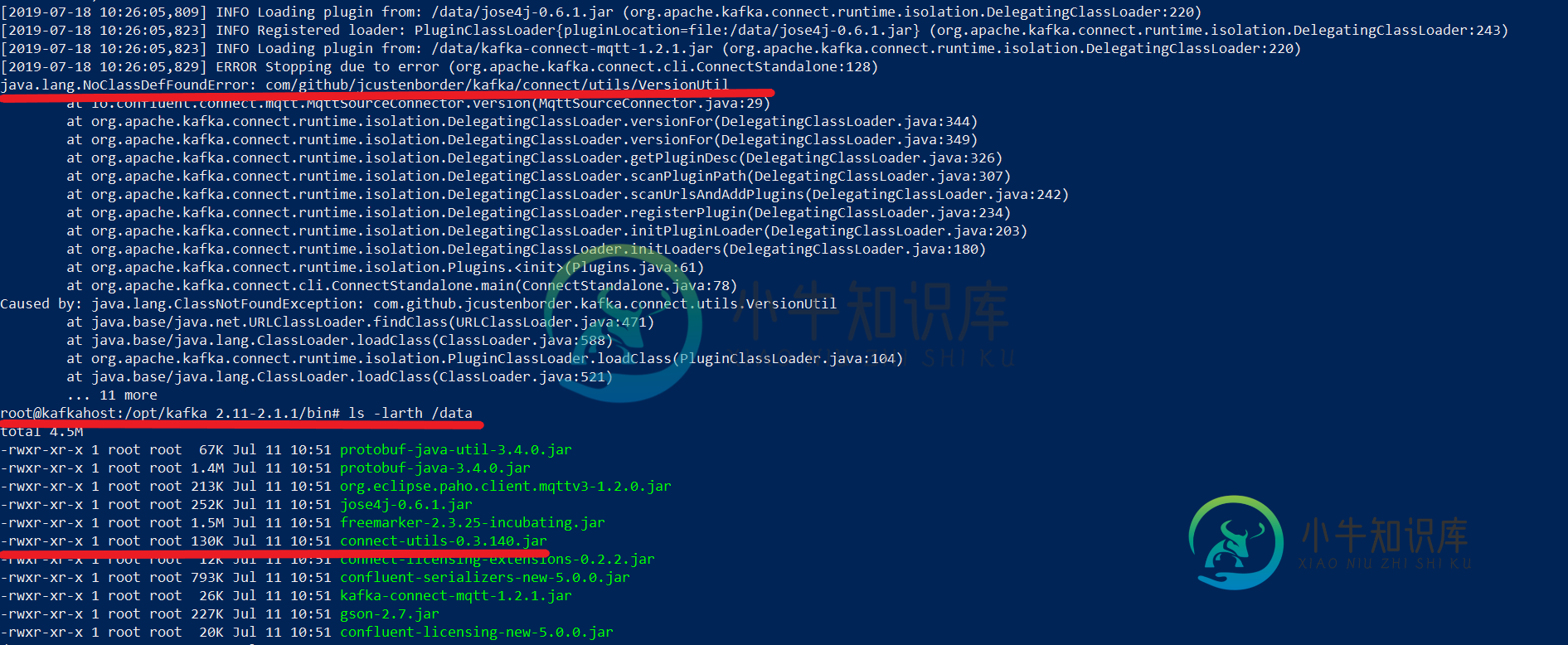 当plugin.path有逗号分隔的值时,Kafka connect抛出ClassNotFoundException
当plugin.path有逗号分隔的值时,Kafka connect抛出ClassNotFoundException我正在使用Kafka connect创建MQTT Kafka连接。我将从confluent站点下载的所有kafka MQTT连接器特定jar放到“/data”文件夹中。并相应地更新“connectstandalone.properties”文件以反映插件路径,即 当我运行Kafka Connect时 我收到以下错误: [2019-07-18 10:26:05,823]信息加载插件from:/dat
-
将Kafka主题下沉到mongodb
我有一个项目,我需要使用java从JSON文件中获取数据,并将其沉入kafka topic,然后将数据从topic沉入mongodb。我已经找到了kafka-mongodb连接器,但是文档只适用于使用汇合平台进行连接。我试过了: 从Maven下载mongo-kafka-connect-1.2.0.jar。 将文件放入 /kafka/plugins 中 在connect-standalone.pro
-
如何使用Spring Cloud Stream Kafka和每个服务的数据库实现微服务事件驱动架构
我试图实现一个事件驱动的架构来处理分布式事务。每个服务都有自己的数据库,并使用Kafka发送消息来通知其他微服务有关操作。 一个例子: 订单接收订单请求。它必须将新订单存储在其数据库中,并发布一条消息,以便支付服务意识到它必须对该项目收费: 私人订单业务; 以下是我的疑惑: 步骤a.-(保存在订单数据库中)和b.-(发布消息)应该在事务中自动执行。我怎样才能做到这一点? 这与前一个有关:我发送消息
-
@kafkaListener的范围
我只想了解@kafkaListener的范围是什么,原型还是单例。在单个主题的多个消费者的情况下,返回的是单个实例还是多个实例。在我的情况下,我有多个客户订阅单个主题并获得报告。我只是想知道如果 > 多个客户希望同时查询报告。在我的例子中,我在成功使用消息后关闭容器,但同时如果其他人想要获取报告,则容器应该打开。 如何将作用域更改为与容器的id相关联的原型(如果不是),以便每次都可以生成单独的实例
-
在@KafkaListener-方法中确认,而不会“丢失”消息
我们目前基本上通过以下简化机制确认消息: 基本上,每当我们暂时不能处理消息时(在IOExceptions的情况下),我们希望在以后的时间再次接收它。 但这不起作用,因为acknowledge假设同一分区内以前的所有消息都已成功处理。在我们的IOException案例中,失败的消息将被跳过,但可能会被同一分区上具有更高索引的不同消息确认。 我们对如何解决这个问题有一些想法,但这意味着需要一些棘手的解
-
Kafka如何保证消费者不会将一条信息读两遍?
Kafka如何保证消费者不会将一条信息读两遍? 或者上述情况是否可能?同一条信息可以被单个消费者或多个消费者阅读两次吗?
-
Apache Camel-Kafka组件-单生产者多消费者
我创建了两个apache camel(blueprint XML)kafka项目,一个是kafka-producer(接受请求并将其存储在kafka服务器中),另一个是kafka-consumer(从kafka服务器获取ups消息并处理它们)。 这个设置对单个主题和单个消费者都很有效。然而,我如何在同一个Kafka主题中创建单独的消费者组?如何在不同的消费者群体中路由同一主题中的多个消费者特定消息
-
来自seda的Camel路由不是路由到Kafka目标endpoint
我有一个简单的骆驼路线,从Kafka的主题消费。做一些处理并写回另一个Kafka主题。 我怀疑Kafka可能是一个请求-应答交换,响应被反馈给源endpoint。因此尝试向Seda添加“waitfortasktoComplete=Never”。但没有成功。 任何帮助都将不胜感激。
-
1.1.1 为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?
面试题 为什么使用消息队列? 消息队列有什么优点和缺点? Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景? 面试官心理分析 其实面试官主要是想看看: 第一,你知不知道你们系统里为什么要用消息队列这个东西? 不少候选人,说自己项目里用了 Redis、MQ,但是其实他并不知道自己为什么要用这个东西。其实说白了,就是为了用而用,或者是别人设计的架构,他从
-
Flume 整合 Kafka
一、背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合后的数据输入到 Storm 等分布式计算框架中,可能就会超过集群的处理能力,这时采用 Kafka 就可以起到削峰的作用。Kafka 天生为大数据场景而设计,具有高吞吐的特性,能很好地抗住峰值数据的冲击
-
深入理解 Kafka 副本机制
一、Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息。每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文件 server.properties 中进行配置,或者由程序自动生成。下面是 Kafka brokers 集群自动创建的过程: 每一个 broker 启动的时候,它会在 Zookeeper 的 /b
-
Kafka 消费者详解
一、消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经常会做一些高延迟的操作,比如把数据写到数据库或 HDFS ,或者进行耗时的计算,在这些情况下,单个消费者无法跟上数据生成的速度。此时可以增加更多的消费者,让它们分担负载,分别处理部分分区的消息,这就是
-
Kafka 生产者详解
一、生产者发送消息的过程 首先介绍一下 Kafka 生产者发送消息的过程: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送 ProducerRecord 对象前,生产者会先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。 接下来,数据被传给分区器。如果之前已经在 Prod
-
基于 Zookeeper 搭建 Kafka 高可用集群
一、Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。 1.1 下载 & 解压 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/ # 下载 wget https://archive.apache.
-
Kafka 简介
一、简介 ApacheKafka 是一个分布式的流处理平台。它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ、ActiveMQ 等消息队列; 支持数据实时处理; 能保证消息的可靠性投递; 支持消息的持久化存储,并通过多副本分布式的存储方案来保证消息的容错; 高吞吐率,单 Broker 可以轻松处理数千个分区以及每秒百万级的消息量。 二、基本概念 2.1 Messages And Ba