《kafka》专题
-
Kafka Connect 集群中只有一个节点响应 REST API 请求
我在不同的主机上运行Kafka Connect集群,我只看到其中一个节点响应REST API请求(特别是:POST、PUT或DELETE请求)的行为。我可以通过关闭一个节点并向另一个活动节点发出写入命令来可靠地交换响应API请求的节点。 这是我的 docker-compose worker 配置: 我可以使用Debezium Postgres连接器和Kafka Snowflake连接器重现它。所以
-
通过Postman访问Openshift Kafka Connect项目
我想通过postman在openshift项目上创建kafka connect连接器。但是当通过邮递员发送Post命令时,出现如下错误。在openshift中将pod公开为服务(通过postman进行交互)时,我们需要运行什么特定的命令?请指教。 您看到此页面的可能原因: 主机不存在。确保正确键入了主机名,并且存在与此主机名匹配的路由。 主机存在,但没有匹配的路径。检查URL路径是否键入正确,以及
-
Kafka Zookeeper连接问题
我用的是Kafka 0.8.2-beta,有2台Ubuntu 14虚拟机: 172.30.141.127正在运行动物园管理员 172.30.141.184在经营一家Kafka经纪人 我正在启动动物园管理员实例,如果一切顺利的话。然后,我尝试启动代理并将其连接到172.30.141.127:2181。它似乎能够在特定的端口上连接并建立会话,但是由于一些似乎没有记录的异常,它失去了连接。 代理输出:
-
如何获取阿帕奇Kafka中的所有话题?
我是apache kafka的新手。现在,有几天想和动物园管理员一起了解Kafka。我想获取与动物园管理员相关的主题。所以我尝试了以下几点 a:)首先我创建了一个动物园管理员客户端,如下所示: 但是使用Java代码执行时主题是空白集。我不明白这里有什么问题。我的动物园管理员道具如下:字符串zkConnect="127.0.0.1:2181";动物园管理员运行得非常好。 请帮助伙计们。
-
除非我重新启动ubuntu内核,否则kafka代理会超时连接到zoo的管理员
很抱歉,但我绞尽脑汁想弄清楚这一点。我的kafka经纪人说等待连接到zookeper,然后关闭(超时)。我检查了经纪人配置/端口是否netstat等也确认了zookeper设置。但是如果我重新启动我的ubuntu内核(kafka经纪人正在运行的地方),一切都很好。动物园管理员是Linux薄荷。请有人建议哪里的日志文件可以给我更多的细节——我做了通常的netstat和lsof运气不好。
-
雪花Kafka连接器疑惑与疑问
我正在使用 3 个服务器集群进行 Kafka 配置,使用 Snowflake 连接器 REST API 将数据推送到 Snowflake 数据库:所有这些都是在 AWS 上运行的 3 个不同的虚拟机 1.在这种情况下,我们是否需要3个kafka单独的服务器zookeeper服务需要在集群中启动和运行,否则只有1个就足够了,就像它需要在所有3个服务器zookerper服务中执行一样,它是否需要不同的
-
为什么kafka connect内部主题connect-offsets有50个分区,connect-status有10个分区?
根据阅读kafka connect文档: https://docs . confluent . io/5 . 3 . 3/connect/user guide . html #分布式模式 config . storage . topic =连接-配置 bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-confi
-
保护对Kafka Connect的REST API的访问
Kafka Connect的REST API没有经过安全保护和身份验证。由于没有经过身份验证,连接器或任务的配置很容易被任何人访问。由于这些配置可能包含如何访问源系统[在SourceConnector的情况下]和目标系统[在SinkConnector的情况下],是否有一种标准的方法来限制对这些API的访问?
-
如何使用 REST API 设置 Kafka Connect auto.offset.reset
我创建了一个接收器Kafka连接,将数据转换为其他存储;我想在使用 创建新连接器时将 设置为;我已经设置了配置; 但是当任务开始时,kafka 消费者仍然最早轮询记录;任何其他将 设置为最新版本的方法也是如此;
-
获取Kafka connect集群的信息
我目前使用的是Kafka connect集群,它有两个节点,使用的是同一个 当使用curl/connectors时,我可以获得创建的连接器列表,但我看不到有关活动节点的信息,健康检查。。。
-
无法在启用SSL的Kafka集群中注册Debezium(Kafka-Connect)连接器
我正在尝试在启用SSL的Kafka集群中注册MySql Debezium连接器。我为此目的使用的卷曲是: Debezium无法创建数据库。历史记录主题,它将失败,并出现以下错误: 美化错误:
-
使用rest API将连接器安装到kafka connect
我想使用apache Kafka Connect Rest API向我的本地Kafka集群添加一个连接器。谢谢
-
为什么我的 Kafka 连接接收器群集只有一个工作线程处理消息?
我最近在我的计算机上安装了一个本地Kafka,用于测试和开发: 3 经纪人 一个输入主题 主题和弹性搜索之间的 Kafka 连接接收器 我设法在独立模式下配置它,所以一切都是本地主机,Kafka connect是使用脚本。 我现在想做的是在分布式模式下运行我的连接器,这样Kafka消息就可以分成两个工作者。我已经启动了两个工作者(仍然是同一台机器上的所有东西),但是当我向我的Kafka主题发送消息
-
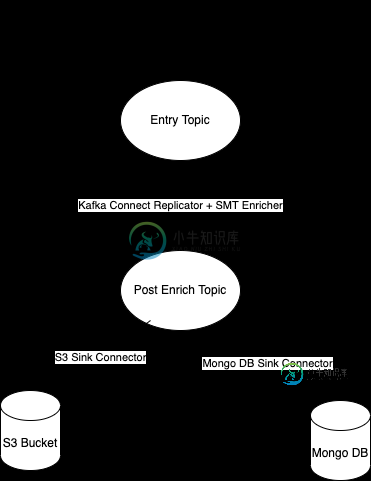 在同一Kafka集群中使用Kafka Connect Replicator
在同一Kafka集群中使用Kafka Connect Replicator我考虑在同一集群内使用Kafka Connect复制器来丰富事件。 这个想法是让SMT来丰富事件,之后需要将事件发送到Mongo DB 我的问题是:这是一个“有意义”的设计,还是我在这里遗漏了什么? 谢谢。
-
OpenShift 中 3 个代理集群中 Kafka 代理的常规网络连接故障
由于未知的原因,在生产和测试中通常每周几次,我们无法与 Kafka 代理通信,并且此消息在日志中重复出现:无法建立与节点 nnnn 的警告连接。经纪人可能不可用。(org.apache.kafka.clients.NetworkClient) 奇怪的是,这反过来又阻止了Kafka的工作(我们不能生产/消费)。 OpenShift没有意识到它不起作用,Kafka也没有识别它。 如果没有执行Broke