
在同一Kafka集群中使用Kafka Connect Replicator

我考虑在同一集群内使用Kafka Connect复制器来丰富事件。
这个想法是让SMT来丰富事件,之后需要将事件发送到Mongo DB
我的问题是:这是一个“有意义”的设计,还是我在这里遗漏了什么?
谢谢。
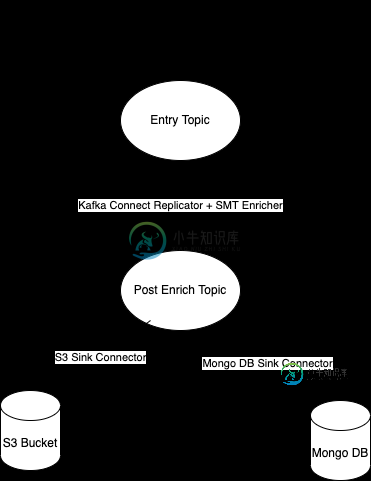
共有1个答案

Replicator旨在在集群之间使用,而不是在同一集群内使用。(这也是一个付费功能,如果有可能的话,您可以使用MirrorMaker2来实现同样的功能)。
KStreams / ksqlDB用于在集群内传输数据,似乎是这里的最佳选择。
Flink,Spark或其他流处理工具可以工作,但需要外部调度程序,并且不需要Kafka Connect即可写入Mongo,S3等,因此实际上取决于您需要解决方案的灵活性。
-
这可能不是典型的设置,但由于更高的决策,我们最终在一个应用程序中有多个 kafka 集群,每个集群有多个主题,每个集群可能具有不同的序列化策略。Json/avro.avro可能与融合的架构注册表一起使用,或者使用单个对象编码。 好吧,我通过构建自己的抽象和注册中心,分析配置并手动创建大部分内容,以某种方式实现了它,但我觉得我需要在几个地方多次重复主题名称、模式注册url等内容,以便创建所有需要的b
-
什么是port和targetport? 是否为每个代理设置LoadBalancer服务? 这些多个代理是否映射到cloud LB的单个公共IP地址? K8S/Cloud之外的服务如何访问单个代理?通过使用?或者使用?。还有,这里用的是哪个端口?还是? 如何在Kafka Broker的属性中指定此配置?对于k8s集群内部和外部的服务,As端口可能不同。 请帮忙。
-
我有一个要求,其中我的一些quartz作业应该以集群方式运行(三个节点中只有一个应该运行该作业),而一些作业应该以非集群方式运行(三个节点中的所有三个都应该运行该作业)。 2个quartz.properties一个用于群集实例,一个用于非群集实例。 群集的两个实例都将在应用程序启动时启动。 因此,在非群集排定程序下配置的作业将以排定程序名称NON_CLST_SCHE保存在jobs表中,在同一表中以
-
我有 2 个Kafka集群。群集 A 和群集 B。这些集群是完全独立的。我有一个Spring启动应用程序,它侦听集群 A 上的主题,转换事件,然后将其生成到集群 B 上。我只需要一次,因为这些是金融事件。我注意到,对于我当前的应用程序,我有时会遇到重复的情况,也会错过一些事件。我试图尽我所能只实现一次。其中一篇帖子说,与Spring启动相比,flink将是一个更好的选择。我应该搬到闪光灯吗?请参阅
-
本文向大家介绍为什么要使用Apache Kafka集群?相关面试题,主要包含被问及为什么要使用Apache Kafka集群?时的应答技巧和注意事项,需要的朋友参考一下 答:为了克服收集大量数据和分析收集数据的挑战,我们需要一个消息队列系统。因此Apache Kafka应运而生。其好处是: 只需存储/发送事件以进行实时处理,就可以跟踪Web活动。 通过这一点,我们可以发出警报并报告操作指标。 此外,
-
我见过,但对于我的(简单的)用例来说,它似乎有些过头了。 我也知道,但我不想仅仅为此编写和维护代码。 我的问题是:有没有一种方法可以用kafka原生工具实现这个主题调度,而不用自己写一个Kafka-Consumer/Producer?