《kafka》专题
-
Kafka经纪人的高CPU使用率
我们正在使用带有 5 个代理的 Apache Kafka 2.2 版本。我们每天收到 50 数百万个事件,但我们达到了高 kafka CPU 使用率。我们使用默认的生产者/消费者/代理设置。 我对表演有一些疑问; 我们有不同的kafka流应用程序,它们进行聚合或连接操作以携带丰富的消息。我们所有的kafka-流应用程序都包含以下设置: < li >恰好一次:true < li >最小同步副本:3
-
Kafka主题在一个分区中具有更多数据
我们使用的是 Kafka 2.5.1 版本集群。最近注意到其中一个主题分区数据大小不均匀。与其余分区相比,一个特定分区的大小增加了 300%。这在群集中造成了不均衡的磁盘利用率。 已验证使用者滞后,看起来像其他分区一样正常 此外,我们使用默认分区程序和设置为默认值的“metadata.max.age.ms”配置,即 300000ms(5 分钟) 我们是如何使分区数据均匀分布的?
-
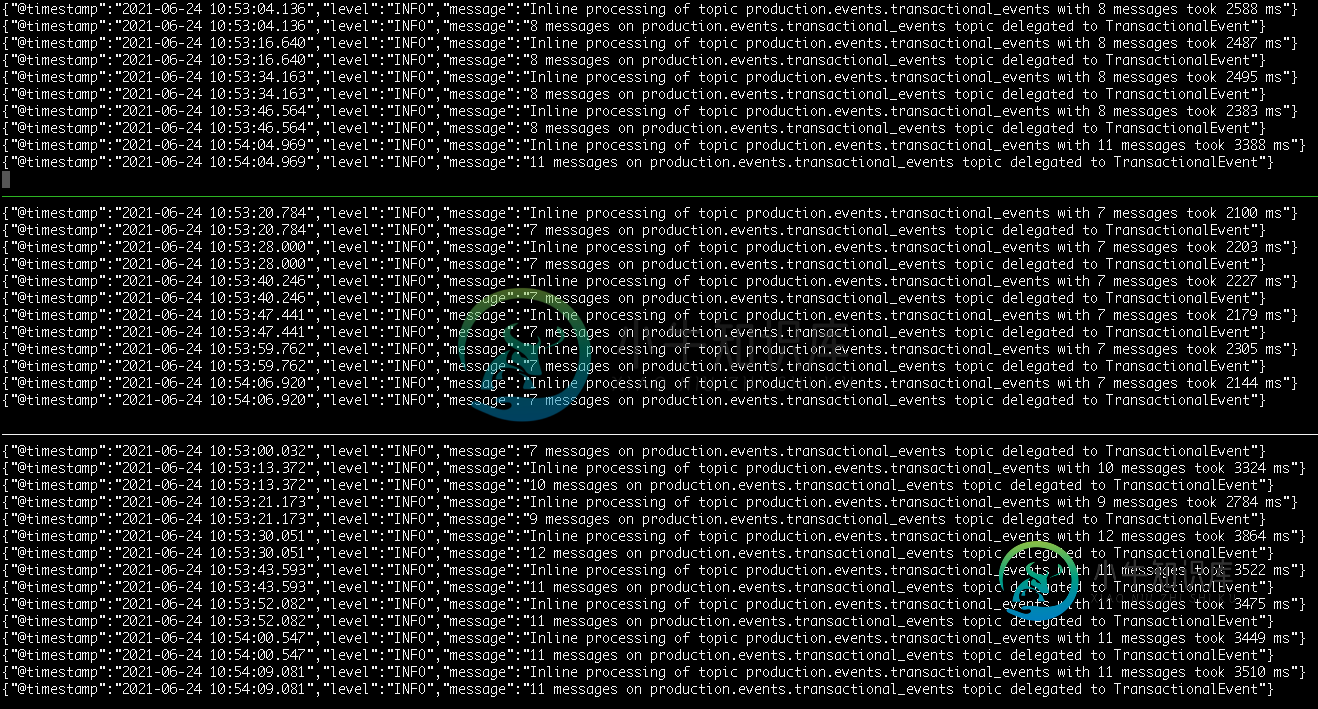 两个连续kafka批次处理之间的长时间延迟(使用ruby/karafka消费者)
两个连续kafka批次处理之间的长时间延迟(使用ruby/karafka消费者)我正在使用karafka阅读主题,并调用外部服务。每次调用外部服务大约需要300毫秒。在消费者组中运行3个消费者(k8s中的3个pod),我预计每秒可以实现10个事件。我看到这些日志线,这也证实了处理每个单独事件的300ms预期。然而,整体吞吐量不相加。每个karafka进程似乎在处理两批事件之间卡住了很长时间。 遵循 方法的检测,意味着使用者代码本身不会花费时间。 https://github
-
kafka消费者(通过新消费者api创建)的偏移和延迟设置为未知
我经常看到kafka消费者的当前偏移和滞后设置为未知的问题 早期消费者的偏移和滞后 几天后,当我再次订阅该消费者时,其偏移和滞后被设置为未知 kafka是否删除了该消费者之前的偏移,因为我正在取消订阅整个消费群的主题?
-
如何访问合流kafka rest代理中主题的最新偏移量以计算延迟
在 confluent kafka rest 代理中,我们可以获取特定消费者组的最后一个提交偏移量,但是我们如何获取主题的最新偏移量来计算滞后。
-
突然间,Kafka Streams(scala)应用程序陷入了重新加入的过程(没有明显的原因),并且从未完成它。
我正在摆弄K8s处理的Kafka Streams。到目前为止,它或多或少进展顺利,但在测试环境中观察到奇怪的行为: [消费者clientId=dbe-livestream-kafka-streams-77185a88-71a7-40cd-8774-aeecc04054e1-StreamThread-1-Consumer,groupId=dbe-livestream-kafka流]我们收到了一个任务
-
如何让Kafka的消费者从最后消费的偏移量开始阅读而不是从头开始
我是 kafka 的新手,并试图了解是否有办法从上次使用的偏移量读取消息,但不是从头开始。 我正在写一个例子,这样我的意图就不会偏离。 有没有一种方法可以获取从上次使用的偏移量生成的消息。?
-
Kafka突然重置了消费者补偿
我正在使用Kafka 0.8 最近,我们开始喂食和消耗一个行为怪异的新主题,消耗的偏移量突然被重置,它尊重我们设置的auto.offset.reset策略(实际上是最小的)但我无法理解为什么该主题会突然重置其偏移量。 我正在使用高级消费者。 这是我发现的一些错误日志: 我们有一堆这样的错误日志: 每次出现此问题时,我都会看到警告日志: 然后真正的问题发生了: 现在的问题是:有人已经经历过这种行为吗
-
Kafka相同的消费者组用于消息消费者以及流拓扑
我们运行一个集群工作线程应用程序,该应用程序依赖于 Kafka 使用高级消费者 API 使用消息。群集中的所有节点共享同一个使用者组。现在我们想要的是将该逻辑的一部分迁移到 Kafka 流处理器 API。这里的方法是什么?如果分配了相同的 groupId/clientId,流拓扑是否会与现有使用者就消息进行斗争?我们应该分配不同的 groupId/clientId 吗?流式传输拓扑?说“组”。 “
-
如何重置偏移值以重新读取 kafka 主题
有一种情况,当消费者1阅读来自Kafka主题的消息时。当使用相同的groupId连接第二个用户2时,需要重新平衡分区。有没有可能以某种方式重置偏移,以便在重新平衡过程之后,两个消费者都从头开始阅读主题?
-
如何确定主题已被Kafka Stream应用程序从第一个偏移量到最后一个偏移量从Java应用程序完全阅读
我在Kafka Streams中需要一些帮助。我已经启动了一个Kafka流应用程序,它从第一个偏移量流式传输一个主题。主题的数据非常庞大,所以我想在我的应用程序中实现一种机制,使用Kafka流,这样我就可以在主题被完全读取到最后一个偏移量时得到通知。 我已经阅读了Kafka Streams 2.8.0 api,我找到了一个api方法i-e allLocalStore分区延迟,它将存储名称映射返回到
-
从 Spring 云流中的处理器写入主题 Kafka 流应用程序
我正在使用处理器 API 对状态存储进行一些低级处理。关键是我还需要在存储到商店后写入主题。如何在Spring Cloud Streams Kafka应用程序中完成?
-
Kafka Streams应用程序在一段时间没有读取消息后停止工作
我注意到我的Kafka Streams应用程序在一段时间没有读取来自Kafka主题的新消息时停止工作。这是我第三次看到这种情况发生。 自5天以来,没有向主题发送任何消息。我的Kafka Streams应用程序也托管了一个spark java Web服务器,它仍然具有响应能力。然而,Kafka Streams不再阅读我向Kafka主题发出的消息。当我重新启动应用程序时,所有消息都将从代理获取。 如何
-
Kafka领导人选举导致Kafka流崩溃
我有一个Kafka Streams应用程序,使用3个代理和3个复制因子从Kafka集群进行消费和生产。除了消费者偏移主题(50个分区)之外,所有其他主题都只有一个分区。 当代理尝试首选副本选择时,Streams应用程序(运行在与代理完全不同的实例上)将失败,并出现错误: Streams应用程序尝试成为分区的领导者是否正常,因为它在不属于Kafka集群的服务器上运行? 我可以通过以下方式复制这种行为
-
它是否会影响Kafka性能或再平衡影响如果我有相同的消费者组名称,来自不同的服务和不同的主题
对于每个服务,我们都有一个特定的Kafka主题 每个服务都有其Kafka主题和该主题的消费者组。 服务1- 这里每个服务都是不同主题的消费者,但它们的消费者组名称是相同的。 如果我们在同一个组中添加另一个服务,是否会影响其他3个服务,因为它们也共享相同的ConsumerGroup名称,尽管它们绑定到不同的主题?或者,如果一个新的消费者被添加到Service3,Kafka需要为主题分区重新平衡消费者