
两个连续kafka批次处理之间的长时间延迟(使用ruby/karafka消费者)

我正在使用karafka阅读主题,并调用外部服务。每次调用外部服务大约需要300毫秒。在消费者组中运行3个消费者(k8s中的3个pod),我预计每秒可以实现10个事件。我看到这些日志线,这也证实了处理每个单独事件的300ms预期。然而,整体吞吐量不相加。每个karafka进程似乎在处理两批事件之间卡住了很长时间。
遵循围绕 use 方法的检测,意味着使用者代码本身不会花费时间。
https://github . com/Kara fka/Kara fka/blob/master/lib/Kara fka/backends/inline . Rb # L12
INFO Inline processing of topic production.events with 8 messages took 2571 ms
INFO 8 messages on production.events topic delegated to xyz
然而,我注意到两件事:
> < li>
当我在3个pod上跟踪日志时,每次3个pod中似乎只有一个发出日志。这对我来说没有意义。因为所有分区都有足够的事件,并且每个消费者应该能够并行消费。
尽管上面的消息大致显示每个事件321ms(2571/8),但实际上我看到日志在两个批处理之间停滞了很长时间。我很好奇,时间去哪儿了?
====== 编辑:
经纪人之间的数据分布存在一定的偏差,因为我们最近将经纪人从3个扩展到总共6个。然而,没有一个经纪人受到cpu或磁盘压力。这是一个新的集群,在高峰时间几乎不使用4-5%的cpu。
我们的数据平均分布在3个分区中——我这么说是因为每个分区的最后偏移量大致相同。
然而,我确实看到一个消费者永远落后于其他两个。下表显示了我的消费者的滞后。每个分区有一个使用者进程:
这是所有3个消费者的日志截图。您可以注意到每次调用< code>consume函数所花费的时间和两次相邻调用之间的时间间隔之间的巨大差异。基本上,我想解释和/或减少等待时间。这个主题中有100k个事件,我的虚拟karafka应用程序能够快速检索它们,所以kafka经纪人不是问题。
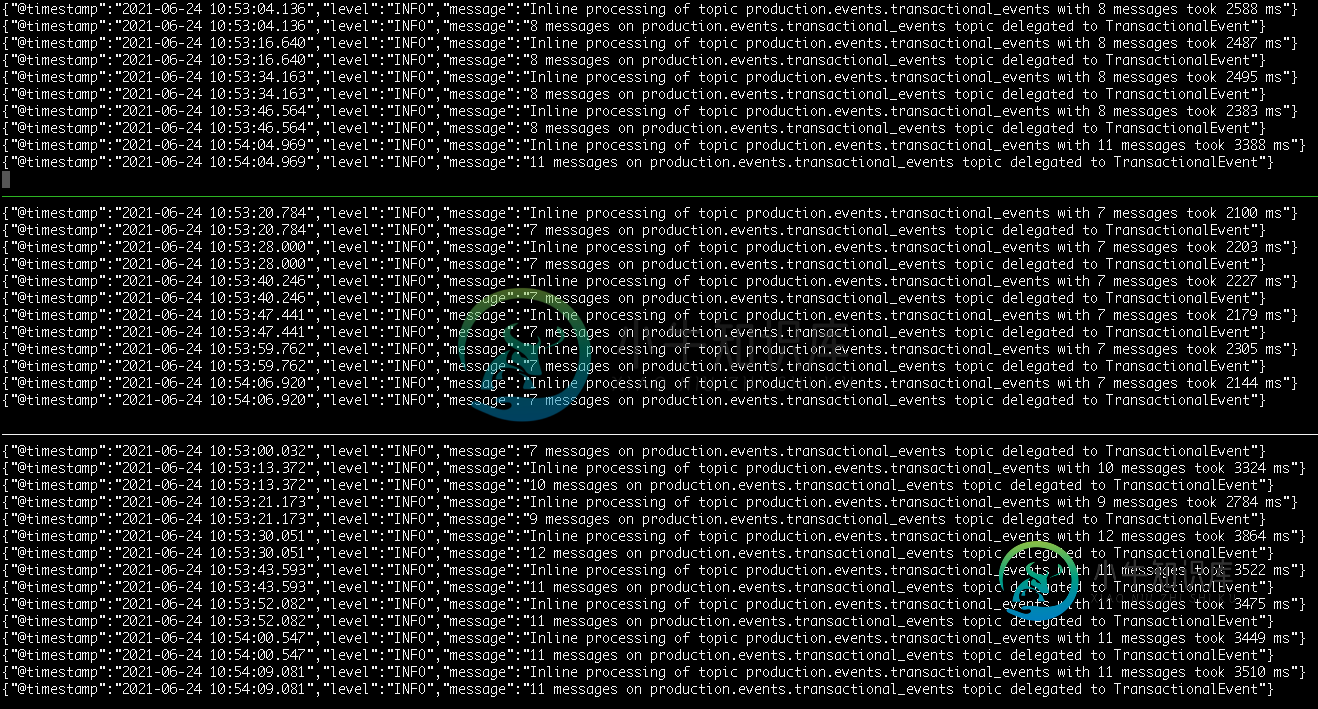
将max_wait_time设置为1秒后更新(之前为5秒)
减少等待配置后,问题似乎得到了解决。现在,两个连续日志之间的差异大约等于消耗的时间
2021-06-24 13:43:23.425 Inline processing of topic x with 7 messages took 2047 ms
2021-06-24 13:43:27.787 Inline processing of topic x with 11 messages took 3347 ms
2021-06-24 13:43:31.144 Inline processing of topic x with 11 messages took 3344 ms
2021-06-24 13:43:34.207 Inline processing of topic x with 10 messages took 3049 ms
2021-06-24 13:43:37.606 Inline processing of topic x with 11 messages took 3388 ms
共有1个答案

您可能会面临几个问题。这边有点猜测,没有更多细节,但让我们试一试。
您确定您在分区之间均匀地分布数据吗?也许它正在吃掉一个分区的东西?
你在这里写的:
主题生产的信息内联处理。包含8条消息的事件花费了2571毫秒
这表明有一批 8 个由单个消费者处理。这可能表明数据分布不均匀。
有两个性能属性会影响您对Karafka运行方式的理解:吞吐量和延迟。
-
< li >吞吐量是在给定时间内可以处理的消息数 < li >滞后时间是指消息从产生到处理的时间。
据我了解,所有的消息都在产生。你可以尝试使用Karafka设置,尤其是这个设置:https://github . com/Kara fka/Kara fka/blob/83 a9 a5 ba 417317495556 C3 ebb4b 53 f 1308 c 80 Fe 0/lib/Kara fka/setup/config . Rb # L114
正在使用的记录器会不时刷新数据,因此您不会立即看到它,而是在一段时间后。您可以通过查看日志时间来验证这一点。
-
我正在使用spring-kafka“2.2.7.RELEASE”来创建一个批处理消费者,并且我正在尝试了解当我的记录处理时间超过 max.poll.interval.ms 时消费者重新平衡是如何工作的。 这是我的配置。 这是我的出厂设置。 我添加了自定义消费者监听器,如下所示。 现在我期望消费者群体能够重新平衡,因为处理时间超过 max.poll.interval.ms 但我没有看到任何这样的行为
-
我经常看到两个参与者之间有很长的延迟(60+秒),从第一个参与者发送消息到第二个参与者,以及第二个参与者的方法随消息实际调用时。我可以寻找哪些类型的东西来调试这个问题? ActorA的每个实例都使用为ActorB发送一条消息。在ActorA中调用方法并在ActorB的开始处获得另一个时间戳之后,我立即收集了一个毫秒时间戳(使用)。这些时间戳之间的间隔一致为60秒或更长。具体地说,当按时间绘制时,该
-
如何使用Apache Kafka生成/使用延迟消息?标准的Kafka(和Java的kafka-client)功能似乎没有这个特性。我知道我自己可以用标准的等待/通知机制来实现它,但是它看起来不是很可靠,所以任何建议和好的实践都很感谢。 找到相关问题,但没有帮助。正如我所看到的:Kafka基于从文件系统的顺序读取,并且只能用于直接读取主题,保持消息的顺序。我说的对吗?
-
我正在使用Spring Kafka1.0.3来消费kafka消息。Kafka的2个主题,每个主题有1个分区。在java代码中,有2@KafKalistener来消费每个主题消息。ConcurrentKafkaListenerContainerFactory的并发设置为1。但消息有时会延迟20秒以上。 有人知道为什么吗? 添加调试日志,并且延迟不是每次都可以,有时也可以:
-
我有一个Python进程(或者更确切地说,在一个使用者组中并行运行的一组进程),它根据来自某个主题的Kafka消息输入来处理数据。通常每条消息的处理都很快,但有时,取决于消息的内容,可能需要很长时间(几分钟)。在这种情况下,Kafka broker断开客户端与组的连接,并启动重新平衡。我可以将设置为一个非常大的值,但它可能会超过10分钟,这意味着如果客户机死亡,集群在10分钟内无法正确地重新平衡。
-
我们正在运行一个3 broker Kafka 0.10.0.1集群。我们有一个java应用程序,它产生了许多消费线程,从不同的主题消费。对于每一个主题,我们都指定了不同的消费者群体。 很多时候,我看到每当这个应用程序重新启动时,一个或多个CG需要超过5分钟来接收分区分配。在此之前,这个话题的消费者不会消费任何东西。如果我去Kafka broker并运行Consumer-Groups.sh并描述特定