《solr》专题
-
ElasticSearch,Sphinx,Lucene,Solr,Xapian。哪种适合哪种用法?
问题内容: 我目前正在寻找其他搜索方法,而不是拥有庞大的SQL查询。我最近看过Elasticsearch,并玩过whoosh(搜索引擎的Python实现)。 您能给出选择理由吗? 问题答案: 作为ElasticSearch的创建者,也许我可以为您提供一些理由,说明我为什么继续并首先创建它:)。 使用纯Lucene具有挑战性。如果要使其真正发挥出色,就需要注意很多事情,而且它是一个库,因此没有分布式
-
如何将树数据存储在Lucene / Solr / Elasticsearch索引或NoSQL数据库中?
问题内容: 说说我有一些小树而不是文档,我需要将它们存储在Lucene索引中。我该怎么做呢? 树中的一个示例节点: 在上面的节点中,“数据”成员变量是用空格分隔的字符串,因此需要全文搜索。“类型”成员变量只是一个单词。 搜索查询本身将是一棵树,并将搜索每个节点中的数据和类型,以及树的结构以查找匹配项。在与子节点匹配之前,查询必须首先与父节点数据和类型匹配。可以对数据值进行近似匹配。 索引此类数据的
-
将ElasticSearch和/或Solr用作MS Office和PDF文档的数据存储
问题内容: 我目前正在设计一个全文搜索系统,用户可以在其中搜索MS Office和PDF文档的文本,结果将返回与查询最匹配的文档列表。然后,用户将选择返回的任何文档,并在MS Word,Excel或PDF查看器中查看该文档。 我可以使用ElasticSearch或Solr将原始二进制文档(即.docx,.xlsx,.pdf文件)导入其“数据存储区”,然后根据命令将文档导出到用户的设备以进行查看。
-
我们可以将Kibana用于Apache Solr而不使用elasticsearch吗
问题内容: 如何将Kibana与Apache solr集成在一起,而不是使用elasticsearch。 如果无法完成。 Kibana for Solr的替代品有哪些 问题答案: 在LucidWorks,我们已经移植了Kibana与Solr一起使用并将其作为开源发布。 如果需要捆绑的软件包,可以从http://www.lucidworks.com/lucidworks- silk/ 下载。 我们的
-
Elasticsearch:排除筛选器时可以进行分面吗?(例如在Solr中)
问题内容: 我正在研究从Solr到ES的转变。我找不到有关信息的一件事是,在刻面时ES是否允许我定义排除过滤器。 例如,考虑以下值:我要介绍的值(即:显示计数)。还要考虑到查询仅限于。 在这种情况下,Solr允许我指定我要排除约束影响其上的构面。IOW,它显示计数,好像没有应用约束。 如何在Solr中执行此操作,请参见:http : //wiki.apache.org/solr/SimpleFac
-
使用tomcat 6.0的Apache Solr配置
问题内容: 您能帮助我使用Tomcat配置Apache Solr以及如何使用Solr在MS SQL数据库中建立索引。配置Tomcat以在Tomcat中运行Apache Solr的步骤是什么。 问题答案: 这是有帮助的分步过程。 第1部分:使用TOMCAT设置SOLR 步骤1:下载Solr。这只是一个zip文件。 步骤2:从SOLR_HOME_DIR / dist / apache-solr-1.3
-
Solr术语
主要内容:一般术语,SolrCloud术语,配置文件在本章中,我们将解释并理解在Solr中经常使用的一些术语的真正含义。 一般术语 以下是在所有类型的设置中使用的一般术语的列表 - 实例 - 就像一个实例或一个实例,这个术语指的是在JVM中运行的应用程序服务器。Solr主目录提供对每个这些Solr实例的引用,一个或多个核心可以配置在每个实例中运行。 核心(core) - 在应用程序中运行多个索引时,可以在每个实例中拥有多个核心,而不是每个核心的多个
-
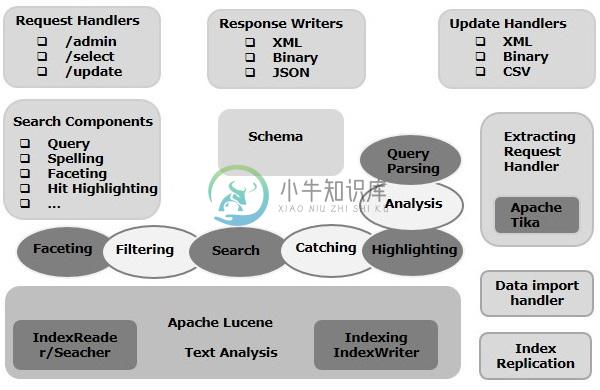 Solr架构(体系结构)
Solr架构(体系结构)在本章中,我们将讨论Apache Solr的架构。 下图显示了Apache Solr的体系结构的框图。 Solr架构 - 构件块 以下是Apache Solr的主要构建块(组件) 请求处理程序 - 发送到Apache Solr的请求由这些请求处理程序处理。请求可以是查询请求或索引更新请求。根据这些请示的要求来选择请求处理程序。为了将请求传递给Solr,通常将处理器映射到某个URI端点,并且它将为指
-
 Hadoop配置使用Solr
Hadoop配置使用Solr主要内容:下载Hadoop,从命令提示符下载Hadoop,安装Hadoop,验证Hadoop安装,在Hadoop上安装SolrSolr可以和Hadoop一起使用。 由于Hadoop是用于处理大量数据,Solr帮助我们从这么大数据源中找到所需的信息。在本节中,我们将了解如何在系统上安装Hadoop。 下载Hadoop 下面给出了如何将Hadoop下载到系统中的步骤。 第1步 - 打开Hadoop主页 - www.hadoop.apache.org/。 单击链接版本,如下面的屏幕截图中突出显示。 它
-
 Solr Windows环境安装配置
Solr Windows环境安装配置主要内容:设置Java环境在本章中,我们将讨论如何在Windows环境中设置Solr。要在Windows系统上安装Solr,需要按照以下步骤 - 访问Apache Solr的主页,然后点击下载按钮或直接访问:http://lucene.apache.org/solr/downloads.html 。 选择一个镜像以获取Apache Solr。从那里选择下载名称为的文件。 将文件从下载文件夹移动到所需的目录并解压缩,在这个示
-
 Solr搜索引擎基础
Solr搜索引擎基础主要内容:搜索引擎组件,搜索引擎是如何工作的?搜索引擎是指一个庞大的互联网资源数据库,如网页,新闻组,程序,图像等。它有助于在万维网上定位信息。 用户可以通过以关键字或短语的形式将查询传递到搜索引擎中来搜索信息。 搜索引擎然后搜索其数据库并向用户返回相关链接。 比如下面常用到两个搜索引擎 - 百度 谷歌 搜索引擎组件 一般来说,搜索引擎有三个基本组件,如下所列 - Web爬虫 - Web爬虫也称为蜘蛛或机器人。 它是一个收集网络信息的软件组件
-
Solr教程
主要内容:Apache Solr特点,Lucene在搜索应用程序Solr是一个开源搜索平台,用于构建搜索应用程序。 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 使用Solr构建的应用程序非常复杂,可提供高性能。 为了在CNET网络的公司网站上添加搜索功能,Yonik Seely于2004年创建了Solr。并在2006年1月,它成为Apache软件基金会下的一个开源项目。并于2016年发布最新版本,支持并行SQL查询的
-
如何用Solr/Lucene序列化/反序列化一个map?
我是solr的新手,当我试图在Solr中序列化/反序列化一个Map时,我遇到了一个问题。 我在Java应用程序中使用Spring Data Solr,如下所示: 它在Solr中展平并序列化我地图,如下所示: 但是,当我运行搜索时,返回的对象始终将此字段设置为 NULL。反序列化不适用于此特定字段,看起来它无法识别键 1、键 2...作为地图的一部分。 有人知道如何使派生工作吗?我必须实现自定义转换
-
solr和lucene的区别
我知道Lucene和Solr是两个不同的Apache项目,它们是一起工作的,但我不明白每个项目的目标是什么。 到目前为止,我所理解的是,Lucene用于创建搜索索引,而Solr使用该索引执行搜索。我是对的还是这是一个完全不同的方法?
-
在多个solr索引之间共享爬网nutch数据
我们有数以千计的solr索引/集合共享Nutch抓取的页面。 感谢任何想法或帮助:)