《solr》专题
-
Ubuntu-Django Haystack和Solr集成错误
我已经阅读了这两篇构建搜索应用程序的教程。 使用OpenJDK在Ubuntu上安装Solr和django-haystack,在这里 Django-干草堆-Solr-安装指南,这里 但是当我来到: 配置django-haystack,根据文档设置搜索索引类 http://docs.haystacksearch.org/dev/tutorial.html#configuration 将所需的solr字
-
如何将实体识别与Apache solr和LingPipe或类似工具结合使用
我想在使用ApacheSolr索引数据时使用NLP。 > 标识命名实体,并在索引时对其进行标记。 当有人查询Solr索引时,我应该能够从查询中提取命名实体和意图并形成查询字符串,这样它就可以有效地搜索索引文件。 是否有任何工具/插件可以满足我的要求?我相信这是大多数基于内容的网站的常见用例。人们如何处理它?
-
通过Solr4.7.2索引Excel的xslx格式文件时出现异常
在通过Solr4.7.2搜索API索引xslx扩展的excel表时,我遇到了一个异常。 我有4阿帕奇POI罐在我的tomcat库相关此Excel工作表,这是:poi-3.9-20121203.jar,poi-ooxml-3.9-20121203.jar,poi-ooxml-schemas-3.9-20121203.jar,poi-scratchpad-3.9-20121203.jar 我检查并发现
-
Apache Solr/JDBC/MySQL.原因:com.mysql.jdbc.exceptions.jdbc4.无法创建到数据库服务器的连接
我的Solr 8.10.1 data importhandler indexer在尝试从MySQL5.7导入时抛出错误。 原因:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException:无法创建到数据库服务器的连接。原因:java.lang.NullPointerException:无法调用“java.util.Map
-
如何使用solr对索引时不可用的数据进行索引和查询
所以除了上面的5个字段之外,core0中的rest all字段将为null。 下一个是核心1 核心1我们使用单独的查询索引3个字段 谢谢,拉维
-
Solr WebAdmin错误500
几天来,我一直在试图找到一个正确启动Solr5.2.1的解决方案,但我总是得到这个错误: HTTP错误500 你对此有什么想法吗?多谢! 更新: 当我检查solr服务状态时:
-
使用mlockall使JVM/Solr不交换
我看到ElasticSearch提供了mlockall选项,它允许将JVM堆保存在物理内存中,而不是虚拟内存(可能是物理内存,也可能不是物理内存),并避免交换堆。 索尔有这样的选择吗?
-
如何忽略SOLR查询中的某些字段
我有Solr 5.3.1,需要查询除某些字段之外的所有字段(我需要在某些字段中搜索而不是以这种方式检索字段[/?q=query&fl=field1,field2,field3]) 2.[以下解决方案有效,但需要更多时间] 3.我在data-config.xml中设置了indexed=“false”,它只忽略此字段中的搜索,但是当我搜索所有字段http://localhost:8983/solr/t
-
在Solr中查询多核中的不同字段
我有两个内核运行在同一个tomcat实例上。我的要求是类似于以下内容: 1。对于单个Solr查询,从Core1返回field1、field2和从Core2返回field3、field4。我需要将所有四个字段作为一条记录返回。 请为我提供一些帮助,以实现这一点在Solr。
-
Spring靴中的redis和solr指标
我有spring boot 2.0.2中内置的服务。我用的是redis和solrj。 现在如果我想得到redis和solr的指标。它不显示在 是否有任何方法,例如制作自定义endpoint以获取redis和solr指标? 任何帮助都将不胜感激。。
-
Apache SOLR-搜索器选项
我正在通过manning阅读Solr in Action,对提交和各种搜索器升温选项几乎没有问题。 属性告诉solr根据指定的时间间隔(maxTime)、doc Count(maxDocs)提交要写入磁盘的文档。 问题1:-maxTime和maxDocs是否可以一起提供,或者它们是相互排斥的 自动提交有一个名为openNewSearcher的子文件。 书中说openNewSearcher如果在每次
-
突出显示时Solr性能非常慢
我配置了一个Solr 4.4.0内核,其中包含约630k文档,原始大小约为10 GB。为了查询和高亮显示,每个字段都会复制到文本字段中。当我在没有突出显示的情况下执行搜索时,结果会在大约100毫秒后返回,但当打开突出显示时,相同的查询需要10-11秒。我还注意到,对相同术语的后续查询持续大约10-11秒。 我对该字段的初始配置如下 发送的查询类似于以下内容 我所有的研究似乎都没有提供线索来解释为什
-
我应该如何配置Solr filterCache、firstSearcher和newSearcher?
问题1:我试图在solrconfig中优化我的搜索者。xml,并且有两种不同的搜索器可以使用。我的理解是firstSearcher只在服务器启动时启动。每当您需要新的搜索者时,就会创建一个newSearcher。在我看来,我们希望在每个中指定相同的FQ和方面。什么时候你希望他们有所不同? 问题2:是否有任何方法可以确定添加fq或方面对搜索者启动时间的影响?我知道我可以用蛮力测量有fqs/facet
-
提交时防止solr缓存刷新
我的应用程序的写入吞吐量很低,我可以管理2-3分钟的更改,以反映在solr搜索结果中 目前,我通过索引应用程序进行提交(在每批文档之后),并在solr端配置了以下内容: 选择配置的原因来自我对以下内容的理解: 我的应用程序被大量读取需要大量缓存,我负担不起刷新缓存的费用。因此,我已经完全禁用了软提交。 我已经禁用了opensearch cher,因为如果我不这样做,它会使不可取的顶级缓存无效 在生
-
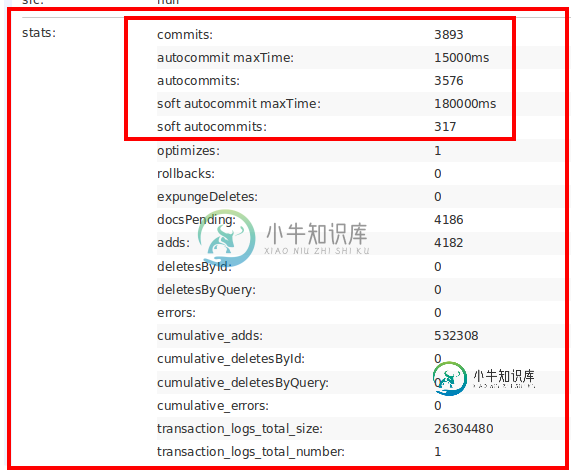 了解不同类型的SOLR提交
了解不同类型的SOLR提交我想澄清一下我对不同类型Solr提交的理解。如果我错了,请纠正我。 > 提交:所有类型的提交,包括软提交和硬提交。 自动提交:对磁盘进行硬提交,确保所有自动软提交提交都写入磁盘,并提交任何其他挂起的文档。 因此,如果我们将commit=true参数设置为任何带有一些文档数据的solr api调用,那么它很难将当前文档也提交到挂起的文档。文档将在(15000ms=15s)内更新到磁盘上 因此,如果我