《apache》专题
-
Shell脚本实现分析apache日志中ip所在的地区
本文向大家介绍Shell脚本实现分析apache日志中ip所在的地区,包括了Shell脚本实现分析apache日志中ip所在的地区的使用技巧和注意事项,需要的朋友参考一下 查询ip地址所用的组件 步骤和nginx是差不多的,只是取日志里面的ip地址的方法不一样~~~ 最后cat 查看~~
-
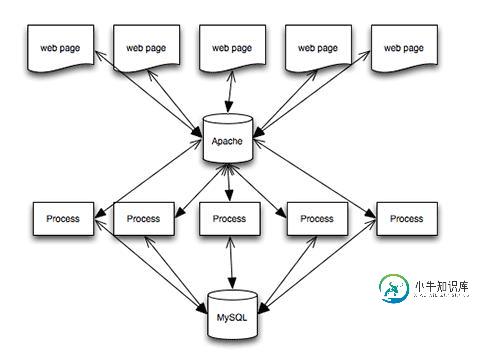 在Apache服务器上利用Varnish优化移动端访问的方法
在Apache服务器上利用Varnish优化移动端访问的方法本文向大家介绍在Apache服务器上利用Varnish优化移动端访问的方法,包括了在Apache服务器上利用Varnish优化移动端访问的方法的使用技巧和注意事项,需要的朋友参考一下 想象一下,你刚刚发布了一篇博文,并分享到了社交网络。然后,这篇文章恰巧被大V看中再次分享了出去,立即吸引了数百粉丝的目光,引导他们涌入了你的网站。看到这么多的访客量,以及它们的评论,你内心激动不已。突然之间,你的网站
-
django apache mod-wsgi暂停从.so文件导入python模块
问题内容: 我正在尝试将Django应用程序部署在apache mod- wsgi上进行生产。我有一个名为freecad的第三方python应用程序,它将python模块打包在FreeCAD.so库文件中。请求挂在“导入FreeCAD”上。一些Apache日志错误告诉我zlib可能有问题?尝试导入此模块时进行压缩。注意,使用django的runserver时一切正常。 在深入研究之后,这不是压缩问
-
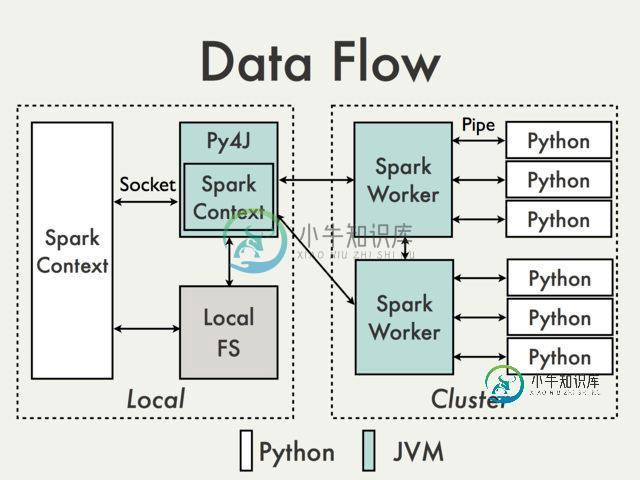 Apache Spark如何处理python多线程问题?
Apache Spark如何处理python多线程问题?问题内容: 根据python的GIL,我们不能在CPU绑定的进程中使用线程,所以我的问题是Apache Spark如何在多核环境中利用python? 问题答案: 多线程python问题与Apache Spark内部结构分开。Spark上的并行性在JVM内部处理。 原因是在Python驱动程序中,使用Py4J启动JVM并创建JavaSparkContext。 Py4J仅在驱动程序上用于Python和
-
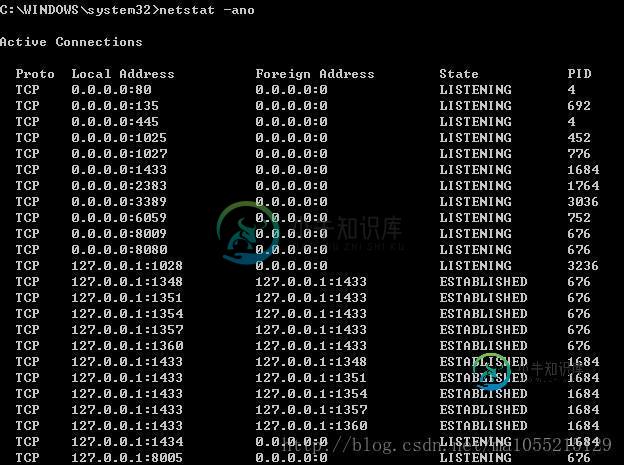 80端口被system占用导致Apache无法启动的解决方法
80端口被system占用导致Apache无法启动的解决方法本文向大家介绍80端口被system占用导致Apache无法启动的解决方法,包括了80端口被system占用导致Apache无法启动的解决方法的使用技巧和注意事项,需要的朋友参考一下 **昨天 开始学习PHP的时候,安装了WampServer,然后一切安装正常后发现有个服务一直无法启动,桌面右下角图标一直是黄色的,怎么也绿不了,然后谷歌了下说是80端口被占用。 下面我就来介绍一下我是怎么解决80端
-
 PHP环境搭建(php+Apache+mysql)
PHP环境搭建(php+Apache+mysql)本文向大家介绍PHP环境搭建(php+Apache+mysql),包括了PHP环境搭建(php+Apache+mysql)的使用技巧和注意事项,需要的朋友参考一下 一、软件及系统版本 系统下载地址: 软件包下载地址:http://xiazai.jb51.net/201611/yuanma/php+apache+mysql(jb51.net).rar 二、 下载软件包/换源 (1)下载安装需要软件包
-
如何通过apache渲染. phtml文件
我想渲染一个。但是,当我尝试使用Apache时,它将页面呈现为文本而不是html。 在vhost配置中,如果我尝试呈现索引。php,它可以正确执行。但是当我将DirectoryIndex更改为index时。phtml并尝试呈现索引。phtml存在于公共目录中,它只是呈现文本。 vhost配置为:ServerName parminder。com DocumentRoot“C:/workspace/p
-
Apache Beam KDA应用程序未创建检查点
我在Amazon KDA上部署了一个Apache Beam应用程序。 它使用默认设置启用了检查点。 但在应用程序日志中,我可以看到: "存在依赖检查点的无限制源,但检查点被禁用。" 只有当我将作为运行时属性传递给我的应用程序时,它才会进行检查点。那么有必要显式传递这些值吗? 该应用程序基本上从Kinesis读取窗口数据,将其转换为大小约为30的固定持续时间,然后将数据发布回PubSub。 应用程序
-
使用Apache Beam笔记本启动数据流作业时处理名称错误
当我运行Google Cloud Platform网站上可用的示例笔记本Dataflow_Word_count.ipynb时,我可以使用Apache Beam笔记本启动数据流作业,并且该作业成功完成。管道的定义如下。 如果我使用一个新函数重构提取单词的部分,如下所示 并运行笔记本我得到以下错误消息: 为了处理名称错误,我按照说明添加了以下行 但是当我运行笔记本时,出现了以下错误 有没有简单的方法来
-
Apache Beam:分布式KV表中的维护状态
我试图更好地理解梁计算模型,并检查我的问题是否可以在该模型内解决。 假设我有一系列事件, 我想建立管道: 读取事件流 我读过关于有状态处理的内容,据我所知,在StatefulParDo中维护用户的最大分数很容易。但这种状态是如何存储的是Beam实现的细节,而这种状态在StatefulParDo函数之外是不可用的。 是否有可能在某种可供外部消费者(我的管道之外的读取器)使用的KV存储中以定义良好的格
-
多线程如何在apache beam管道中使用有界源代码?
我是大数据处理的新手。我正在使用apache束JavaSDK来使用它。试图了解多线程/并行数据处理在apache束管道中是如何工作的。关于多线程,数据是如何从一个PTransform处理到另一个PTransform的?
-
Apache Beam容错如何适用于全局Windows?
我正在用Beam Python构建管道。我有一个来自PubSub的事件流,其中包含userId和buttonId。我有一个全局窗口,用于维护所有用户单击按钮的次数。 如果一段时间后服务器重新开始运行Direct Runner/Flink Runner,全局windows状态是否会恢复到管道? Beam中的容错是如何工作的? 如何跟踪PubSub的偏移量/检查点? 光束留档指出: 状态的存储和容错:
-
Apache Beam Kinesio Java-使用kinesis流中的数据
首先,我想说这对Beam世界来说是全新的。我正在处理一个以Apache Beam为中心的任务,我的主要数据源是Kinesis流。在那里,当我使用流数据时,我注意到当我重新启动程序(我的消费者应用程序)时,相同的数据集也会出现。这是我的代码, 简单地说,我想要的是,我需要从我之前阅读的地方开始阅读数据。如果有人能提供一些资源,我真的很感激。 我还发现了一个类似的问题,但它对我没有帮助-Apache
-
Apache Beam如何管理驱动检查点?
我有一个在Apache Beam(使用Spark Runner)中开发的流媒体管道,它从kinesis流中读取。 我正在Apache Beam中寻找管理kinesis检查点的选项(即定期存储kinesis流的当前位置),以便允许系统从故障中恢复,并在流中断的地方继续处理。 Apache Beam是否有类似于Spark Streaming(参考链接-https://spark.apache.org/
-
Apache Beam Spark便携式转轮
我正在运行一个示例管道,我的环境就是这样。 Python"SaiResearch-Apache-Beam-Spark.py"--run=PortableRunner--job_endpoint=192.168.99.102:8099 我的Spark运行在Docker容器上,我可以看到JobService运行在8099。 我得到以下错误:grpc_频道_多线程登录: 当我卷曲到ip: port时,我