《stream》专题
-
使用Kafka Streams和依赖Headers中模式引用的Serdes
我正在尝试使用 Kafka 流对 CDC 数据执行 KTable-KTable 外键连接。我将读取的数据是 Avro 格式,但它的序列化方式与其他行业序列化程序/反序列化程序(例如 Confluent 模式注册表)不兼容,因为模式标识符存储在标头中。 当我设置KTables的Serdes时,我的Kafka Streams应用程序最初运行,但最终失败,因为它在内部使用,而不是包装序列化程序Value
-
我可以使用Kafka Streams/构建一个“空拓扑”吗?
我们有一个Spring Boot Kafka Streams处理器。由于各种原因,我们可能会遇到需要进程启动和运行的情况,但是没有我们希望订阅的主题。在这种情况下,我们只希望进程“Hibernate”,因为其他活动/环境检查器依赖于它的运行。此外,它是RedHat OCP集群的一部分,我们不希望pod不断地执行崩溃退避循环。我完全理解,在使用有效主题重新启动之前,它永远不会真正做任何事情,但没关系
-
配置的组ID在spring-cloud-streams中被忽略
我必须为kafka流消费者设置一个组id,它符合严格的命名约定。 在深入跟踪留档后,我找不到有效的方法。因为我仍然相信我可能有误解,我更喜欢在这里打开一个问题以供同行审查,然后再打开一个bug问题。 一年前就已经问过一个类似的问题,但这个问题不是很夸张,还没有回答,我希望我能在这里对这个问题有更多的见解。 从官方文档的几个来源来看,我看到在我的应用程序的 中配置这应该很容易。 文件中指出,我可以:
-
Spring Cloud Stream Kafka通道在Spring Boot应用程序中不工作
我一直试图让入站SubscribableChannel和出站MessageChannel在我的spring boot应用程序中工作。 我已经成功设置了kafka频道并成功测试了它。 此外,我还创建了一个基本的spring-boot应用程序,用于测试从通道添加和接收内容。 我遇到的问题是,当我把相同的代码放在它所属的应用程序中时,消息似乎永远不会被发送或接收。通过调试很难确定发生了什么,但对我来说唯
-
使用启用批处理模式的Spring Cloud Stream在Kafka中实现DLQ
我正在尝试使用启用批处理模式的spring cloud stream实现DLQ 但有一些疑问: > 如何使用属性配置键/值序列化程序-我的消息是String类型,但KafkaOperations使用的是ByteArraySerializer 在批处理中,有多个消息,但如果第一条消息失败,它会转到DLQ,但看不到下一条消息的处理。 要求-如果批处理失败,我只需要将该消息发送到DLQ,并且应该再次处理
-
为什么使用Kafka绑定器哈希键的Spring Cloud Stream与标准Kafka Producer不同?
我遇到了一个问题,我需要将一个现有的主题(< code>source)重新分区到一个新的主题(< code>target),这个新主题具有更大的分区数量(是以前分区数量的倍数)。 主题是使用Kafka Binder使用Spring Cloud Stream写入的。主题正在使用KStreams应用程序写入。 < code>source主题中的记录基于标题进行分区,其中< code>key=null。
-
Kafka Streams应用程序GSSAPI身份验证
我有一个使用Kafka Streams API的应用程序。我在当地工作时没有问题。我想连接到远程Kafka代理进行阶段测试。远程Kafka代理设置为使用GSSAPI sasl机制并使用Kerberos。我运行用java编写的Streams应用程序时出错。在我查找错误消息后,我找到了答案,但仍然有问题。 错误消息;获取相关id为3的元数据时出错:{[APPID]-KTABLE-AGGREGATE-S
-
将StateRestoreListener与Spring Cloud Kafka Streams绑定器一起使用
我打算将StateRestoreListener与Spring Cloud Kafka Streams绑定器一起使用。我需要监视应用程序的容错状态存储的恢复进度。汇流中有一个例子https://docs.confluent.io/current/streams/monitoring.html#streams-监控运行时状态。 为了观察所有状态存储的恢复,您需要为应用程序提供 org.apache.
-
春云流:@StreamListener处理消息两次
我正在使用Spring Cloud Stream(Edgware.SR5)和Spring Boot(1.5.10.RELEASE)。我的@StreamListener正在处理收到的每条消息两次。 该示例的思想是在队列中发布消息并对其进行处理。 服务: 绑定: application.properties: 配置(用于在测试中注入代理服务): 测试: 我得到了以下输出: 我不知道我的配置有什么问题,
-
Spring Cloud Stream Kafka-方法必须是声明性的
我已经配置了一个基于Spring启动的应用程序与Spring云流。我试图在KStream上工作,但我不断得到错误"java.lang.IllegalArgumentExc的:方法必须是声明性的"。有人能帮我了解如何配置这个吗?我查找了StreamListener留档,但我无法让它工作。 https://docs.spring.io/spring-cloud-stream/docs/Elmhurst
-
Spring-Cloud-Stream 仅在应用程序启动时实现的状态存储完全填充并准备就绪后处理 kafka 消息
参考这个解决方案,我的Spring云流应用程序.yml文件具有以下配置: 在我的主应用程序中,类注释为@EnableB 问题是,在应用程序第一次启动时,状态存储尚未完全填充,也尚未准备就绪(例如空状态存储),但消息仍然更早到达,并且正在由Kafka流拓扑处理,结果出乎意料。 我们如何确保在第一次启动应用程序时,在@StreamListener中定义的任何流处理拓扑开始处理传入消息之前,所有或特定(
-
Flink Streaming:如何使用过去30天的所有事件处理每个事件?
在键控流上,我希望在新事件到达时,立即为每个新传入事件计算一次窗口函数,同时以迭代器的形式为它提供过去30天内该键的所有早期事件的上下文。 预期的行为类似于滑动窗口,长度为30天,滑动时间为1纳秒,每个传入事件只计算一次窗口函数。 我看不到如何在内置的翻滚/滑动/会话窗口(带/不带触发器/驱逐器等)上映射此行为。 有人能帮忙吗?或者这需要编写自己的窗口赋值器或自己的键控状态处理吗?
-
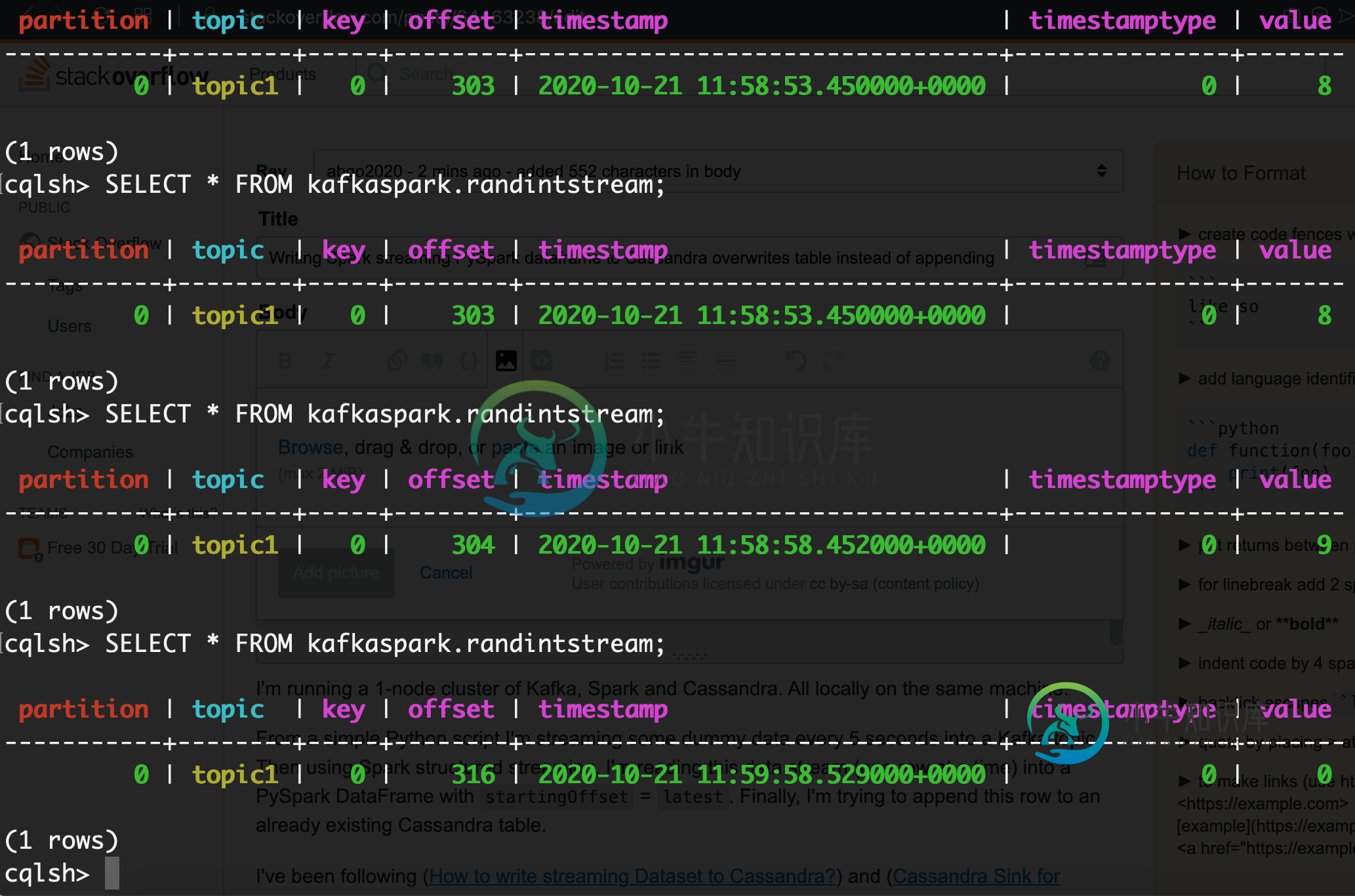 将Spark streaming PySpark dataframe写入Cassandra会覆盖表而不是追加
将Spark streaming PySpark dataframe写入Cassandra会覆盖表而不是追加我正在运行一个由Kafka、Spark和Cassandra组成的1节点集群。全部本地在同一台机器上。 从一个简单的Python脚本中,我每5秒将一些虚拟数据流到一个Kafka主题中。然后使用Spark结构化流,我将这个数据流(一次一行)读入PySpark DataFrame中,并使用=。最后,我尝试将此行追加到一个已经存在的Cassandra表中。 我一直在关注(如何向Cassandra编写流数据
-
Spark streaming使用更少的执行器
我正在使用火花流处理一些事件。它是以独立模式部署的,有1个主和3个工作人员。我已将每个执行人的核心数设为4个,执行人的总数设为24个。这意味着总共有6个执行者将被产生。我已经把摊开成真了。所以每个工人机器得到2个执行者。我的批处理间隔为1秒。另外,我已经将批处理重新分区为21。其余3个是给接收器的。在运行时,我从事件时间线观察到,只有3个执行器被使用。其他3个没有使用。据我所知,在spark独立模
-
使用Stream将String 2D数组映射到新对象
我有一个POJO旅行者,变量为字符串name,字符串city。我有一个字符串数组,比如 我想要一张地图,上面有名字和城市列表。 我无法给旅行者绘制地图。有没有一种方法可以为旅行者绘制地图,并将其名称作为重点和城市列表。