《数据结构》专题
-
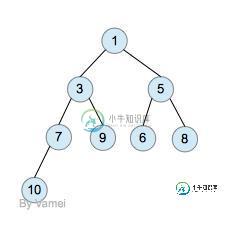 PHP SPL标准库之数据结构堆(SplHeap)简单使用实例
PHP SPL标准库之数据结构堆(SplHeap)简单使用实例本文向大家介绍PHP SPL标准库之数据结构堆(SplHeap)简单使用实例,包括了PHP SPL标准库之数据结构堆(SplHeap)简单使用实例的使用技巧和注意事项,需要的朋友参考一下 堆(Heap)就是为了实现优先队列而设计的一种数据结构,它是通过构造二叉堆(二叉树的一种)实现。根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。二叉堆还常用于排序(堆排序)。 如下:最小堆(任
-
 ReactJs实现树形结构的数据显示的组件的示例
ReactJs实现树形结构的数据显示的组件的示例本文向大家介绍ReactJs实现树形结构的数据显示的组件的示例,包括了ReactJs实现树形结构的数据显示的组件的示例的使用技巧和注意事项,需要的朋友参考一下 本文介绍了ReactJs实现树形结构的数据显示的组件的示例,分享给大家,具体如下: 1、该组件树形显示数据 2、组件中数据的请求方式为fetch方式 3、点击对应的数据前面的小三角,fetch请求改数据下对应的子数据,并展开该节点。 4、将
-
需要帮助解决具有挑战性的数据结构问题
我遇到了这个问题,给定一个整数数组,判断整数序列是从左、右还是死端退出数组。您从左侧输入数组并沿指定方向移动N个索引(其中N是整数的值)(正是右,负是左) 我想到的一个解决方案是,若所有整数的值都是正的,那个么就向右退出或向左退出。但是,此解决方案并不涵盖所有场景。我需要帮助来解决这个问题。
-
Spark结构化流媒体中的拼花数据和分割问题
我正在使用Spark结构化流媒体;我的DataFrame具有以下架构 如何使用Parquet格式执行writeStream并写入数据(包含zoneId、deviceId、TimesInclast;除日期外的所有内容)并按日期对数据进行分区?我尝试了以下代码,但partition by子句不起作用
-
 JS中的算法与数据结构之字典(Dictionary)实例详解
JS中的算法与数据结构之字典(Dictionary)实例详解本文向大家介绍JS中的算法与数据结构之字典(Dictionary)实例详解,包括了JS中的算法与数据结构之字典(Dictionary)实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS中的算法与数据结构之字典(Dictionary)。分享给大家供大家参考,具体如下: 字典(Dictionary) 字典(Dictionary)是一种以 键-值对 形式存储数据的数据结构 ,就如同我们
-
C++数据结构与算法之反转链表的方法详解
本文向大家介绍C++数据结构与算法之反转链表的方法详解,包括了C++数据结构与算法之反转链表的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C++数据结构与算法之反转链表的方法。分享给大家供大家参考,具体如下: 算法概述:要求实现将一条单向链表反转并考虑时间复杂度。 算法分析: 数组法(略): 将列表元素逐个保存进数组,之后再逆向重建列表 点评:实现逻辑最简单,需要额外的内存开销
-
Spring Batch 3 数据库结构更改是否与 Spring Batch 2 兼容?
我们从Spring Batch 2.1.7迁移到Spring Batch 3.0.6,但收到以下jboss启动错误: org.springframework.jdbc.BadSqlGrammarException: PreparedStatementCallback;坏SQL语法[选择E.JOB_EXECUTION_ID,E.START_TIME,E.END_TIME,E.STATUS,E.EXI
-
查找树数据结构中所有叶节点的最佳方法
我有一个树数据结构,其中每个节点可以有任意数量的子节点,树可以是任何高度的。获取树中所有叶节点的最佳方法是什么?有没有可能比遍历树中的每个路径更好,直到我到达叶节点? 在实践中,树的最大深度通常为 5 左右,树中的每个节点将有大约 10 个子节点。 我对其他类型的数据结构或特殊树持开放态度,这将使获取叶节点特别理想。 我正在使用javascript,但实际上只是在寻找一般建议,任何语言等。 谢啦!
-
以下程序的高效解决方案和最佳数据结构
我正在寻找解决这个问题的有效方法,即...编写一个程序来查找总和等于给定数字的所有整数对。例如,如果输入整数数组是{2, 6, 3, 9, 11}并且给定总和是9,则输出应该是{6,3} 现在我尝试的是以下内容,但我知道这不是一个可行且有效的解决方案。。 从数组中取一个数字,然后循环遍历数组和输出对,这等于给定的总和。您对第一个数组中的所有数字都这样做,
-
数据结构>队列:为什么(后方=前方)是空的条件?
像这样的正常队列: _empty1__empty2__empty3__empty4_... 所以这里的“front”指向“empty1”。但是, (*1):我的第三项质询与第二项质询相同,但以通函方式提出。
-
Azure Cosmos DB SQL API-读取/查询数据结构未知的文档
我有一个Cosmos数据库,其容器包含不同结构的文档。
-
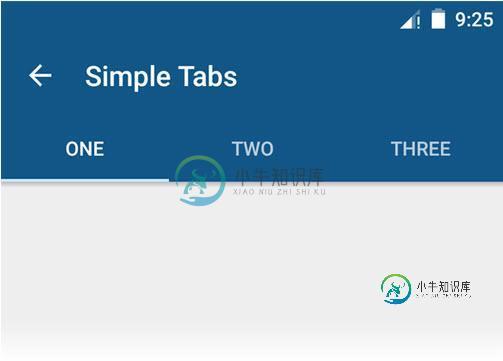 在MVVM体系结构中使用Tab布局与数据绑定库
在MVVM体系结构中使用Tab布局与数据绑定库我正在开发一个应用程序,有一个标签布局作为图像。 我想使用MVVM体系结构和数据绑定库,但我对这个框架是新的。 我可以在不使用MVVM的情况下,通过使用ViewPager设置选项卡布局来完成此操作。 没有MVVM和数据绑定的普通选项卡布局: activity_main.xml: mainactivity.java: MVVM中的选项卡布局: 当将MVVM与数据绑定库一起使用时,我们将不得不为选项卡
-
Chapter-3 DataStructure 第3章 数据结构 - LeftistTree(LeftistHeap) 左偏树(左偏堆)
描述 左偏树是一种接近于堆的二叉树,它的根节点总是树中的最小值或最大值。与堆不同的是,两个堆的合并需要遍历被合并的堆中所有元素,依次插入另一个堆中,而左偏树可以支持更快速的合并操作。本问题只考虑根节点为最小值情况的左偏树。 左偏树的主要操作有 (1) 合并两个左偏树; (2) 插入新节点; (3) 查找最值; (4) 删除最值。其中 (2) - (4) 的实现依赖于 (1) ,合并操作是左偏树的核
-
MySQL哈希索引的数据结构以及索引的优缺点
主要内容:1 索引的优缺点,2 哈希索引,3 全文索引,4 空间数据索引(R-Tree)我们看看其他哈希索引结构的实现,以及索引的优缺点。 1 索引的优缺点 索引可以让服务器快速的定位到表的指定位置。但是这并不是索引的唯一作用,总结下来索引有以下4个优点: 索引大大减少了服务器需要扫描的数据量。 B-Tree索引可以帮助服务器避免排序和临时表,可以用于 ORDER BY 和 GROUP BY 操作,临时表主要是在去重、排序、分组过程中创建,不需要排序和分组,也就不需要创建临时表。 由
-
java - Redission实现公平锁为什么要使用ZSet数据结构?
Redission实现公平锁为什么要使用ZSet数据结构? 使用ZSet结构有什么好处? 看lua代码好像也并没有使用到 ZSet的二分查找这种优势