《架构思维》专题
-
Linux 基础架构/树莓派
1.1.1. 目录 1.1.2. 一、概述 1.1.3. 二、SDK 目录结构 1.1.4. 三、快速集成 1.1.5. 四、API接口 1.1.1. 目录 一、概述 二、SDK 目录结构 三、快速集成 集成前准备 开始集成 四、API接口 语音识别服务接口(speech) 语音合成服务接口(tts) 1.1.2. 一、概述 Rokid 语音识别服务(Speech) Rokid语音识别服务与Rok
-
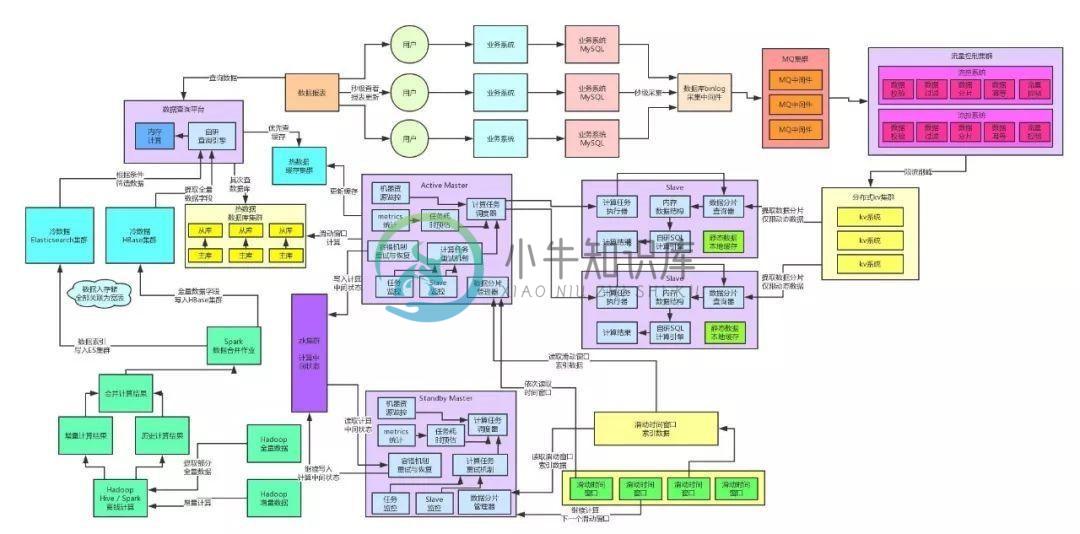 架构师的必备能力
架构师的必备能力主要内容:一、前情回顾,二、MQ集群高可用方案,三、KV集群高可用保障方案,四、实时计算链路高可用保障方案,五、热数据高可用保障方案,六、冷数据高可用保障方案,七、最终总结一、前情回顾 上篇文章:《同事老是吐槽我的接口性能差,原来真凶就在这里!》,聊了一下系统架构中的查询平台。 我们采用冷热数据分离: 冷数据基于HBase+Elasticsearch+纯内存自研的查询引擎,解决了海量历史数据的高性能毫秒级的查询 热数据基于缓存集群+MySQL集群做到了当日数据的几十毫秒级别的查询性能。 最终,整
-
 字节 系统架构 凉经
字节 系统架构 凉经字节一面(提前批) 自我介绍 介绍了项目使用的内容 子网是什么 net是什么(这个我并不知道) ARP协议 在ping的过程中,mac地址会变吗 介绍一下锁 知道分布式锁吗 常用redis使用分布式锁,你知道吗 在使用redis的时候采用的是什么模式 算法题:给了一个数字的字符串,排列出全部的合法ip组合。 https://leetcode.cn/problems/restore-ip-addre
-
您所说的框架是什么意思?命名可用的框架类型。
本文向大家介绍您所说的框架是什么意思?命名可用的框架类型。,包括了您所说的框架是什么意思?命名可用的框架类型。的使用技巧和注意事项,需要的朋友参考一下 框架是一组规则,指南和最佳实践,遵循这些框架可获得期望的结果。测试框架应具有以下功能: 应该支持多个浏览器。 应该在多个平台上运行。 应在Java,Python,C#,Ruby等多种编程语言上运行。 高效处理测试数据。 测试用例的创建和更新是容易且
-
JavaScript构造x=x | | y是什么意思?
问题内容: 我正在调试一些JavaScript,无法解释它的作用? 有人可以给我一个提示,为什么这个人正在使用?我有时也看到它而没有声明。 问题答案: 这意味着该参数是可选的。因此,如果您不带任何参数调用该方法,则它将使用默认值。 它是写作的简写: 这种带有布尔表达式的速记技巧在Perl中也很常见。带有表达式: 它计算是否为或为。因此,如果为真,则完全不需要检查。这称为短路布尔评估,因此: 基本上
-
Ktable to KGroupTable-架构不可用(未注册状态存储更改日志架构)
我有一个Kafka主题-让我们活动-每日-聚合,我想使用KGroupTable进行聚合(添加/子)。所以我使用 在第1步和第2步之前,我已经将MockSchemaRegistryClient配置为 当我使用测试用例运行拓扑时,我在第2步得到一个错误。 组织。阿帕奇。Kafka。溪流。错误。StreamsException:进程中捕获异常。taskId=0_0,processor=KSTREAM-S
-
Java应用程序架构指南
问题内容: 是否有与之相对应的Java应用程序体系结构指南:http : //www.codeplex.com/AppArchGuide? 问题答案: 以下内容将对您有所帮助 核心J2EE模式 头先设计模式 J2EE蓝图 尽管快速浏览了Codeplex上的文档,但我可以告诉您,其中可能有70-80%的内容也适用于Java。
-
休眠自定义架构创建
问题内容: 创建一个新的数据库架构,并创建一个不存在的数据库架构,并更新现有的数据库架构。如果我想检查数据库模式是否存在,并根据将要创建的数据库模式来检查,该如何实现。目前,我的配置是: 和HibernateEMSDao.java: 这是工作。什么配置可以帮助我实现这一目标?就像是: 检查ID = 1的用户是否存在 如果没有创建架构 感谢致敬。 问题答案: 您可以禁用该选项,检查条件(可能使用普通
-
Laravel数据库架构中的MediumBlob
问题内容: 如何在Laravel模式构建器中创建一个? 在文档中说: 但是我需要一个MediumBlob,否则图像将在64K时被截断;我们正在运行MySQL。 我知道Laravel的架构生成器与数据库无关,但是有一种方法可以避免“本机方法”,如果没有,我该如何创建列? 问题答案: 你不能 该问题建议使用原始查询来创建此类列,因此您应该在迁移文件中执行以下操作:
-
Python MySQL错误的架构错误
问题内容: 我已经来了一段时间,并阅读了许多有关该主题的网站。怀疑我有垃圾造成了这个问题。但是哪里? 当我在python中导入MySQLdb时,这是错误: 我正在尝试64位,所以在这里检查: 已将python的默认版本设置为2.6 尝试删除构建目录和python setup.py clean重命名为Python / 2.5 / site-packages,使其无法尝试提取它。 删除所有内容,并按照
-
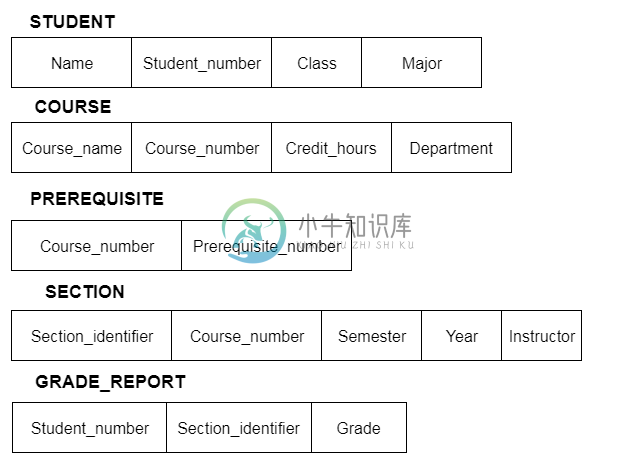 数据模型架构和实例
数据模型架构和实例数据模型架构和实例 在特定时刻存储在数据库中的数据称为数据库的实例。 数据库的整体设计称为模式。 数据库模式是数据库的骨架结构。它表示整个数据库的逻辑视图。 模式(schema)包含模式对象,如表,外键,主键,视图,列,数据类型,存储过程等。 可以使用可视化图表来表示数据库模式。 该图显示了数据库对象以及彼此之间的关系。 数据库设计者设计数据库模式以帮助软件开发与数据库交互的程序员。数据库创建过程
-
无法从endpoint下载GraphQL架构
我目前正在使用Prisma的graphql cli从endpoint下载模式。但是,即使在我部署了对模式所做的更改(部署成功)之后,每当我尝试下载模式时,我都会得到
-
合流架构注册表主机
对于跨网络汇流平台,我们有一个kafka集群在Premise上,另一个在AWS上,其中数据使用mirror Maker从on-prem复制到AWS。这两个集群都独立于它们自己的模式注册表、rest代理和Connect,这两个集群都有不同的生产者和消费者集,并且选择的主题在集群之间被镜像。 部署schema-registry的最佳实践应该是什么?我们是否应该在on-prem和AWS上有一个主服务器(
-
 【实习】百度-基础架构(OC)
【实习】百度-基础架构(OC)以前投的百度捞我面试 一面 HTTP2和HTTP1的区别 HTTP2头部压缩算法是什么 说一下Hpack TCP慢启动,拥塞避免 TCP滑动窗口3啥意思 JS基本数据类型 判断类型方法 两道手写,四道算法,麻了 二面 狂问项目 前后端不分离浏览器的渲染过程 ssr怎么实现 项目中的localStorage 项目中token的实现及验证过期 如何优化token token的轮询检测 同时打开窗口,l
-
OpenShift 3.5架构-虚拟机供应
我的任务是为OpenShift生产环境推荐VM配置。OpenShift安装文档并没有详细说明很多不同的选项。我知道我们需要高可用性(这意味着多个主机),但我有点困惑的是: etcd的单独主机 基础设施节点 etcd需要单独的主机/节点吗?(优势似乎与性能有关,但希望更好地理解) 基础架构组件(注册表、路由器等)是否需要单独的主机/节点,还是可以将它们托管在主节点上?