《顺丰2024春招》专题
-
Spring boot-bean创建顺序
-
SpringBoot中的配置顺序
null 非常感谢你的帮助
-
ElasticSearch多词聚合顺序
我有一个描述容器的文档结构,它的一些字段是: 我想运行一个搜索聚合,该聚合在两个权重字段上有两个级别的术语聚合,但按权重字段的降序排列,如下所示: 样本文件: 预期输出(未完成): 但是,我不能按嵌套聚合排序。(错误:术语桶只能在子聚合器路径上排序,该子聚合器路径由路径中的零个或多个单桶聚合和最终的单桶或指标聚合构建...) 例如,对于上述示例输出,如果我在术语聚合上引入大小(如果我的数据很大,我
-
Spring感知接口顺序
在https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/beans/factory/Aware.html中使用一个实现所有感知接口的bean 在生命周期中,这些接口是否总是以特定的顺序调用? 我所说的接口是:ApplicationContextAware、ApplicationEve
-
redis查询结果顺序
对于redis查询返回结果顺序的判断,我有些怀疑,特别是对于hgetall查询 例如,我将一些数据按其枚举的顺序放入数据库: 不带任何其他参数的“keys key:*”命令是否总是按照数据在数据库中出现的顺序返回该数据,还是会尝试以任何方式对数据进行排序?
-
MapReale-保留输入顺序
包含由管道分隔的数字列表的文件可以有重复项。需要编写map reduce程序,在原始输入顺序中列出不重复的数字。我可以删除重复项,但不保留输入顺序。
-
Java设置保留顺序?
Java集是否保持顺序?一个方法返回一个集合给我,假设数据是有序的,但是在集合上迭代,数据是无序的。有更好的方法来管理这个吗?这个方法需要改变来返回集合以外的东西吗?
-
翻新的顺序请求
我使用reform连接到一个API,该API在每个响应中包含一个惟一的令牌。这个令牌必须包含在下一个请求中。这意味着我需要在发出下一个请求之前等待请求的响应。 在改造中是否有内置机制来实现这一目标?如果不是,推荐的方法是什么?请注意,我使用的是异步改造方法和版本 1.9。拦截器用于读取令牌并自动将其添加到下一个请求中,这非常有效。当两个请求非常接近时,就会出现问题,因此第二个请求最终使用过时的令牌
-
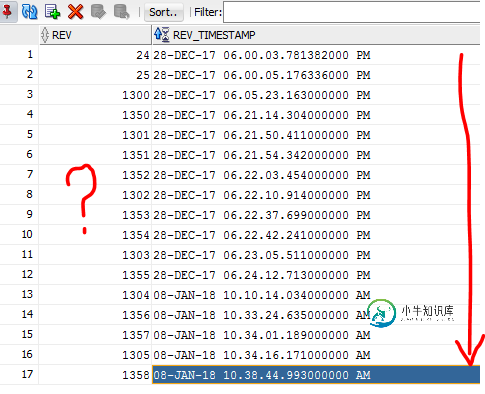 Hibernate Envers版本号顺序
Hibernate Envers版本号顺序我们可以看到,转速不是单调增加的。在我的实体的审计表中,我有以下内容: 通过将记录与转速号链接在一起形成时间线,我得到了: 24 -- 事实上,我有一个由2台服务器组成的集群。它们都可以将数据持久化到数据库中。我怀疑这与版本号中的顺序问题有关。因为这个问题。像MyEntity anEntity=auditReader.find(MyEntity.class,id,revNum)这样的查询不起作用,
-
按顺序使用“case”(MySQL)
我在一个返回一个巨大选择的过程中工作,我不想定义它是如何排序的。我不想从三个字段中选择一个,如果它是升序还是降序,如果三个选项都没有定义,它会默认返回降序中的第一个字段 这边 当然,这不起作用... mysql指责单词DESC和ASC中的错误,我怎么能让这个工作??
-
Cassandra聚类密钥顺序
所以我有一张表,它看起来像这样: 我们依赖该表根据进行分页来正确排序。 问题是:当从cassandra返回结果时,看起来它们是根据ASCII值而不是逻辑的A-Z排序进行排序的。-对于观看它的人来说,这在程序上是有意义的,但在逻辑上是不合理的。 是否有一个选项来改变当前聚类顺序的方法? -或者另一种逻辑排序的方法?
-
XMLUnit忽略元素顺序
现在,如果我使用以下代码进行比较,我将在XMLUnit的帮助下相互比较两个xml文件 现在它给出了:预期的属性值'02',但是'01',但我不希望有差异,我希望表id是唯一的,如果在另一个文件中看到相同的表id,则只检查本例中的Main-Element:table->包含什么。
-
 同花顺笔试,产品
同花顺笔试,产品单选题和问答题,大部分无产品相关,有一些与金融有关。 单选题不记得了,感觉不难。 问答题: 1图表分析,根据四个app的日活自己留存率回答问题 2为什么YouTube5秒可跳过广告但爱奇艺优酷不可以?为的是提高用户体验吗?有什么好处? 3.MVP是什么,如何界定mvp边界,如何进行mvp 4.30天留存与次月留存的区别? 5.chatgpt未来三个应用方向以及意义 希望有个好成绩给孩子一个offe
-
顺序存储二叉树
顺序存储二叉树是指用一个数组存储的二叉树,一般用于完全二叉树,物理上用数组存储逻辑上是一个树结构。 第n个元素的左节点索引2n+1 第n个元素的右节点索引2n+2 第n个元素的父节点为(n-1)/2 n为元素在数组中的索引 class Node(object): def __init__(self, data): self.data = data class Array
-
$request_vars_order 变量顺序变量
The order in which request variables are registered, similar to variables_order in php.ini 请求变量的顺序在这里配置,类似于php.ini中的变量顺序.