《zookeeper》专题
-
Pig、Hive、Hbase、Oozie、Zookeeper在Hadoop2.0中的安装是否与在Hadoop1.0中相同?
我最近安装了带有纱线配置的hadoop V2。我计划安装Hadoop生态系统堆栈,如Pig、Hive、Hbase、Oozie、Zookeeper等。我想知道我是否应该安装与Hadoop1.0配置相同的链接中的工具。如果没有,谁能请给我这些工具的Hadoop2配置的链接?。我听说Pig和Hive在Hadoop2.0中更快。因此想知道是否有更好的版本。 谢谢,高萨姆
-
Zookeeper:无法加载主类org . Apache . zookeeper . server . quorum . quorumpeermain
我开始使用ubuntu和Apache kafka,当我运行bin/zookeeper-server-start . sh config/zookeeper . properties时出现以下问题 :~/Documentos/kafka-0.8.2.1-src$ Error: no se ha encontrado o cargado la clase principal org.apache.zo
-
Hadoop Mapreduce任务跟踪器一直忽略hadoop_classpath。Zookeeper尝试连接到localhost而不是群集地址
我有一个包含5个数据阳极的Hadoop集群(Cloudera CDH4.2)。我正在尝试运行一个创建对象的MapReduce作业。tasktracker尝试失败,因为它们试图连接到而不是实际zookeeper安装的地址。
-
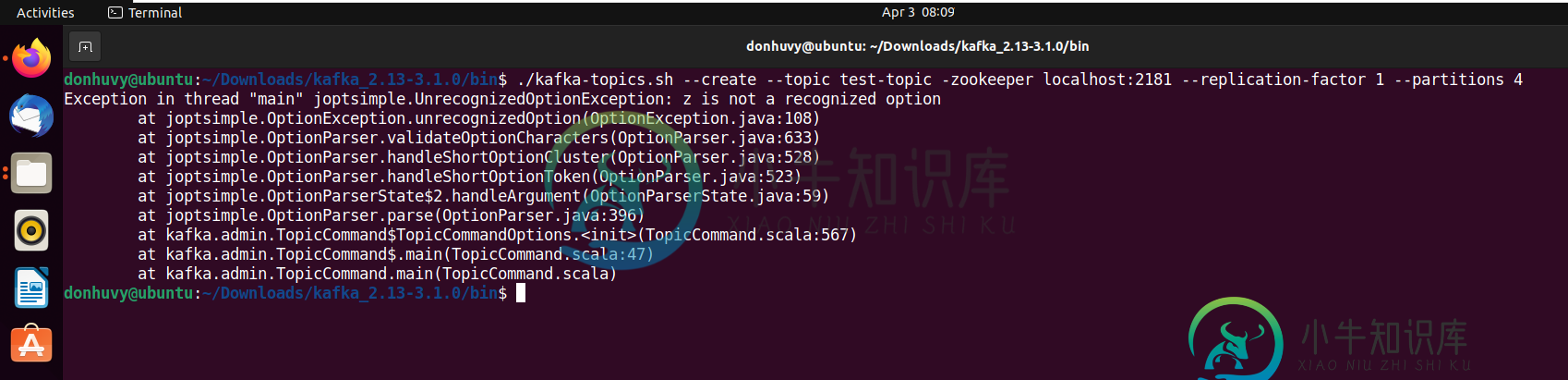 如何修复Kafka3。x错误参数-zookeeper?
如何修复Kafka3。x错误参数-zookeeper?我的版本https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz.在Ubuntu21.10和OpenJDK 11上运行。我跟着导游走https://github.com/donhuvy/kafka-for-developers-using-spring-boot/blob/master/SetUpKafka.md#how-创建一个主题-。我
-
Spring Boot start Zookeeper和Kafka服务器
到目前为止,在运行Spring Boot应用程序之前,我已经从命令行启动了zookeeper和kafka server,但现在我需要直接从代码启动它们。 首先,我已经尝试在main方法中使用ProcessBuilder: 但这似乎不起作用,因为控制台上没有打印任何内容,过了一段时间,应用程序抛出一个TimeoutException。 第二,我想让kafka服务器在Zookeeper启动后运行;一个
-
Solr 5.3&Zookeeper安全身份验证和授权
我遵循了以下教程/信息来源:https://cwiki.apache.org/confluence/display/solr/authentication+and+authorization+plugins和https://lucidworks.com/blog/2015/08/17/securing-solr-basic-auth-permission-rules/ 然后我创建了这个securi
-
使用Zookeeper Quorum建立Spark群集
我们正在尝试使用ZK设置火花高可用性设置。我们有2台机器用于Spark进程的主机,另有3台机器用于Spark从机。Spark主机中的配置在spark-env.sh中如下所示: 其中DEV-SMP-Manager01:2181DEV-SMP-Worker01:2181、DEV-SMP-Worker05:2181是ZK法定人数。它们都在运行。 我们看到了一些与curator相关的错误消息 java.l
-
使用多线程系统在zookeeper上观看多个节点
我有一个项目,我在几个不同的线程中观察几个节点。现在,我注意到,当我观察一个节点时,它发生了变化,引发了一个事件,某个节点上的观察(例如称为a)会阻止所有其他观察者。因此,只有在A上的观察者完成后,另一个观察者才会返回以观察节点的变化。也就是说,如果一个节点在其观察程序被阻止时发生了更改(例如称为B),则只有在a上的观察程序完成后,节点B上的观察程序才会引发该事件。 此问题会导致应用程序变慢。 所
-
如何为动态大小的ZooKeeper集群初始化策展人框架?
我刚刚在独立模式下使用Apache Curator和ZooKeeper实现了一个分布式锁。我草签了策展人框架如下: 一切都很好,所以我尝试在集群模式下使用ZooKeeper。我启动了三个实例,并初始化了CuratorFramework,如下所示: 如您所见,我刚刚添加了两个新节点的地址。到目前为止还不错。 但是,当我不知道每个节点的地址和集群的大小时,我如何初始化客户端,因为我想动态扩展它? 我可
-
Drill JDBC和Zookeeper抛出UnsolvedAddressException
我正在尝试使用JDBC驱动程序从外部连接到DC/OS上的容器化分布式apache drill设置,如下所示 https://drill.apache.org/docs/using-the-jdbc-driver/#example-以编程方式连接到drill 但是,当在集群之外运行此程序以从我的机器连接时,zooManager连接完成,然后它尝试以以下形式解析Drillbit地址 其中是内部钻头id
-
带Zookeeper的集群监视器
我正在尝试用CuratorFramework创建一个基于动物园管理员的应用程序。该应用程序必须能够在更多的节点上以仲裁的方式运行。应用程序的每个实例都嵌入了动物园管理员服务器和客户端的实例。节点在仲裁中被成功地删除。每个节点都向 /workers/active/node1写入一个EPHEMERAL节点(“活动”是由领导者创建的PERSISTENT znode)。因为当客户端连接到动物园管理员服务器
-
无法使用Zookeeper启动Flink HA群集
我试图安装一个Flink HA群集(动物园管理员模式),但任务管理器找不到作业管理器。 这里我给你介绍一下建筑; 大师: 奴隶: flink-conf.yaml: 这里是任务管理器的日志,它试图连接到localhost而不是Machine1: PS.:/etc/hosts包含localhost、Machine1和Machine2 你能告诉我任务经理如何连接到工作经理吗? 当做
-
如何使用zookeeper和策展人进行配置管理?
我一直在读关于使用zookeeper进行配置管理的文章。 我知道有一位阿帕奇策展人可以方便地与zookeeper互动。 我有一些客户连接到一组资源。他们必须以同样的方式使用这些资源。比如资源之间的分片和主选举。 我想使用zookeeper,这样,如果一个客户端在给定时间内注意到其中一个资源已关闭,它可以更改配置,其他客户端可以立即开始使用新配置。 因此,一个客户端在znodezooManager中
-
如何使用curator监视ZooKeeper中后代节点上的事件?
我正在做一个项目,在这个项目中,我需要在一个节点上维护一个表,并且该节点也包括子节点。我尝试过使用PathCache,但我不知道如何在这里监视孩子们的孩子? 这里我的根节点是-,我正在使用下面的代码监视该节点。我想做的是,让手表保持在znode上。假设这些节点被添加到我的根节点- 然后我应该得到通知(直到这一部分我能够使它工作),但如果任何新节点被添加、更新或删除到,和,那么我也应该得到通知,而这
-
如何使用kazoo在ZooKeeper中监视子代节点上的事件?
我最近开始为Zookeeper使用Python。我正在使用动物园管理员的库。我需要监视我的根节点- 可能会添加到我上面的根节点的其他几个节点如下- 现在我需要检查添加到根节点中的子节点是否为。如果节点被添加到中,那么我将只监视节点,如果任何新的子节点被添加到节点中,那么我也需要监视该节点。 比如说,的子代是,所以现在我需要监视,然后如果在这个节点上添加了任何新节点,比如和,那么我需要打印节点的子节